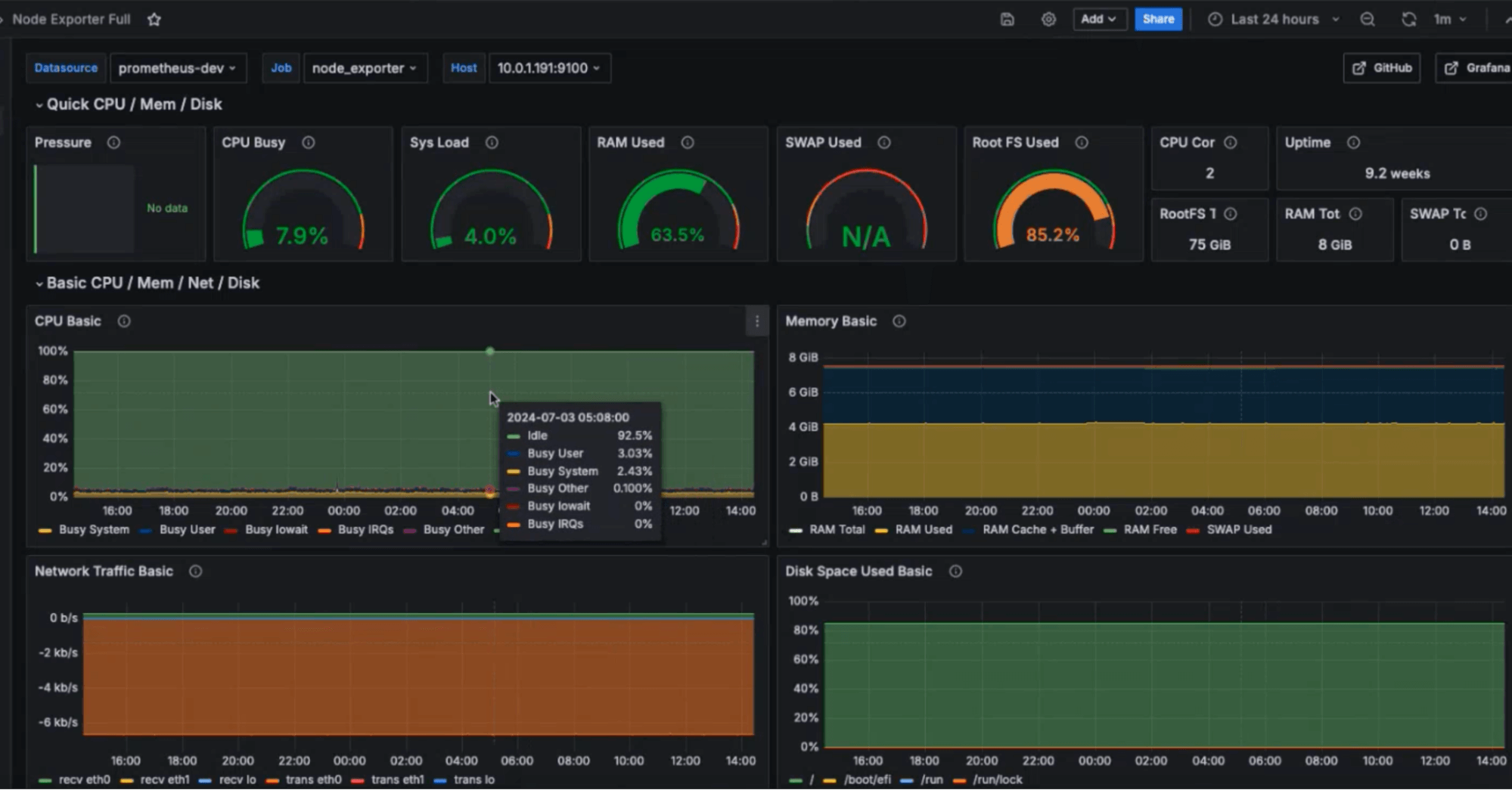
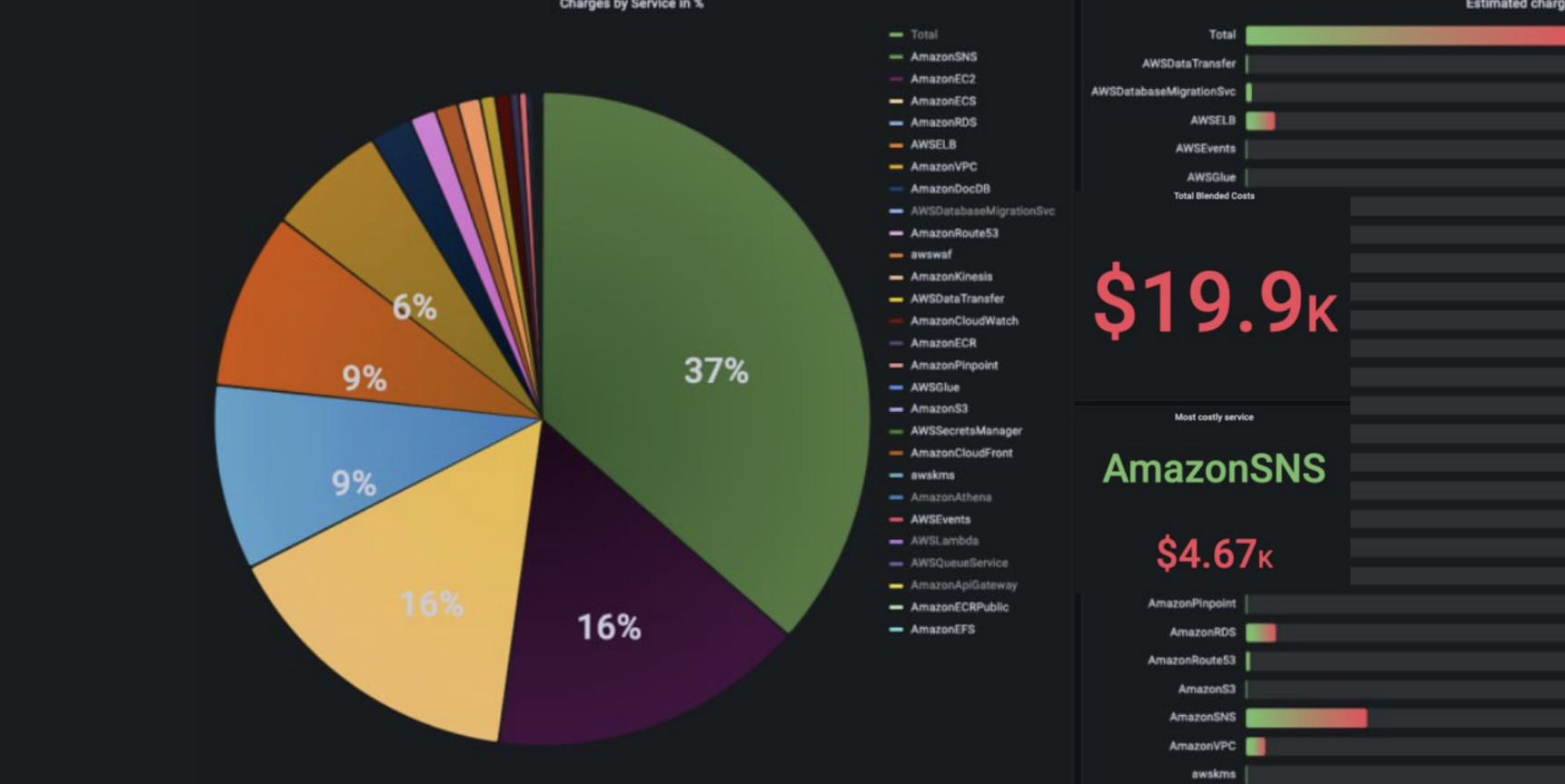
Compliance Monitoring is the ongoing process of verifying that an organization's systems, processes, and people continuously adhere to regulatory requirements, internal policies, and industry standards — not just at audit time, but every day. For cloud-native and regulated businesses in 2026, it is the difference between a clean audit and a costly breach.
What is Compliance Monitoring?
Compliance monitoring is the systematic, continuous practice of evaluating whether an organization's operations, systems, and people conform to the laws, regulations, and internal standards that govern them. Unlike a one-time audit, compliance monitoring runs as an always-on feedback loop — collecting evidence, flagging exceptions, and enabling rapid remediation before regulators ever knock on the door.
The practice is critical across heavily regulated industries:
Healthcare — HIPAA, HITECH, 21 CFR Part 11
Finance & Banking — PCI DSS, SOX, Basel III, MiFID II
Cloud & SaaS — SOC 2, ISO 27001, CSA CCM
EU-regulated entities — GDPR, NIS2, DORA
Energy & Utilities — NERC CIP, ISO 50001
Pharmaceuticals — GxP, FDA 21 CFR
💡 In short: Compliance monitoring is your organization's immune system. Audits are the annual check-up. Monitoring is what keeps you healthy between check-ups.
Why Compliance Monitoring Matters in 2026
Regulatory landscapes have never moved faster. GDPR fines reached record highs in 2024–2025, NIS2 entered enforcement mode across the EU, and DORA (Digital Operational Resilience Act) took effect for financial entities. Meanwhile, cloud adoption has created entirely new attack surfaces that traditional point-in-time audits simply cannot cover.
Risk Without MonitoringTypical Business ImpactProbability (unmonitored)Undetected misconfigured S3 bucket / cloud storageData breach, regulatory fine, brand damageHighStale privileged access not reviewedInsider threat, audit failure, SOX violationVery HighMissing audit log retentionInability to prove compliance, automatic audit failureHighBackup not testedUnrecoverable data loss, SLA breach, recovery failureMediumUnpatched critical CVE beyond SLAExploitable vulnerability, CVSS breach, PCI non-complianceHighWhy Compliance Monitoring Matters in 2026
Strong compliance monitoring builds trust with enterprise clients and partners, significantly reduces audit preparation time, and enables a proactive risk posture instead of a reactive, fire-fighting one.
Compliance Monitoring vs Compliance Audit vs Compliance Management
These three terms are often used interchangeably but they describe distinct activities that work together. Understanding the difference helps organizations allocate resources correctly.
DimensionCompliance MonitoringCompliance AuditCompliance ManagementFrequencyContinuous / near-real-timePeriodic (annual, quarterly)Ongoing governancePurposeDetect & alert on deviationsFormal independent assessmentPolicies, training, cultureOutputAlerts, dashboards, exception logsAudit report, findings, attestationPolicies, procedures, risk registerWho leadsEngineering / Security / DevOpsInternal audit / Third-party auditorCompliance Officer / GRC teamAnalogyBlood pressure cuff worn dailyAnnual physical with doctorHealthy lifestyle programCompliance Monitoring vs Compliance Audit vs Compliance Management
✅ Monitoring answers
Is MFA enforced right now?
Are all logs being retained?
Did anything change in IAM this week?
Are backups completing successfully?
Is encryption enabled on all storage?
📋 Auditing answers
Were controls effective over the period?
Did evidence satisfy the framework?
What is the organization's control maturity?
What formal findings require remediation?
Is the organization SOC 2 / ISO 27001 ready?
Explore our Compliance Audit services
The 7-Step Compliance Monitoring Process
Effective compliance monitoring is not a single tool or dashboard — it's a disciplined cycle. Here is the process Gart uses when setting up or maturing a client's compliance monitoring program:
1. Define Scope & Applicable Frameworks
Identify which regulations, standards, and internal policies apply. Map your systems, data flows, and third-party integrations to determine the monitoring perimeter. Ambiguous scope is the most common reason monitoring programs fail.
2. Inventory Systems & Controls
Catalogue all assets (cloud, on-prem, SaaS, CI/CD pipelines) and map each one to a control objective. Assign control owners. Without ownership, no one acts when an exception fires.
3. Define Evidence Collection Rules
For each control, specify what constitutes "evidence of compliance" — a log entry, a configuration state, a test result, a screenshot, or a signed document. Define collection frequency (real-time, daily, monthly) and acceptable format for auditors.
4. Instrument & Automate Collection
Deploy monitoring agents, SIEM rules, cloud policy engines (AWS Config, Azure Policy, GCP Security Command Center), and IaC scanning tools. Automate evidence collection wherever possible — manual evidence gathering at audit time is a costly, error-prone anti-pattern.
5. Monitor Exceptions & Triage Alerts
Create alert thresholds for control deviations. Not every alert is a breach — build a triage process that separates noise from genuine risk. Route high-priority exceptions to security/engineering immediately; lower-priority items to a weekly review queue.
6. Prioritize Risks & Remediate
Score exceptions by likelihood and impact. Maintain a risk register that tracks open findings, owners, and target remediation dates. Escalate unresolved critical findings to leadership with a clear business-impact framing.
7. Re-test, Report & Continuously Improve
After remediation, re-test the control to confirm it is effective. Produce compliance health reports for leadership and auditors. Run a quarterly retrospective to tune alert thresholds and update monitoring scope as regulations and infrastructure evolve.
Key Controls & Evidence to Monitor
Across hundreds of compliance engagements, the controls below consistently appear on auditor checklists. These are the areas where automated compliance monitoring delivers the highest return:
Control AreaWhat to MonitorEvidence Auditors WantRelevant FrameworksIdentity & Access (IAM)Privileged role assignments, inactive accounts, MFA status, service account permissionsAccess review logs, MFA adoption rate, least-privilege config exportsSOC 2, ISO 27001, HIPAAAudit LoggingLog completeness, retention period, tamper-evidence, SIEM ingestion healthLog retention policy, SIEM dashboard, CloudTrail / Audit Log exportsPCI DSS, SOX, NIS2, GDPREncryptionData-at-rest encryption on storage, TLS version on endpoints, key rotation schedulesEncryption config exports, key management audit logs, TLS scan reportsPCI DSS, HIPAA, GDPR, ISO 27001Patch ManagementCVE scan results, SLA adherence per severity, open critical/high vulnerabilitiesScan reports, patch cadence logs, SLA compliance metricsSOC 2, PCI DSS, ISO 27001Backup & RecoveryBackup job success rate, RPO/RTO test results, offsite replication statusBackup logs, recovery test records, DR test reportsSOC 2, ISO 22301, DORA, NIS2Vendor / Third-Party AccessActive vendor sessions, access scope, contract/NDA currency, SOC 2 report datesVendor access logs, contract register, third-party risk assessmentsISO 27001, SOC 2, GDPR, NIS2Network & PerimeterFirewall rule changes, open ports, egress filtering, WAF alert volumesFirewall config snapshots, IDS/IPS logs, pen test reportsPCI DSS, SOC 2, NIS2Incident ResponseMean time to detect (MTTD), mean time to respond (MTTR), breach notification timelinesIncident logs, CSIRT reports, post-mortemsGDPR (72h), NIS2, HIPAA, DORAKey Controls & Evidence to Monitor
Continuous Compliance Monitoring for Cloud Environments
Cloud infrastructure changes constantly — teams spin up resources, update IAM policies, and deploy code multiple times per day. This makes continuous compliance monitoring not a nice-to-have but a fundamental requirement. Manual checks against cloud state are obsolete before the ink dries.
AWS Compliance Monitoring — Key Automated Checks
AWS Config Rules — detect non-compliant resources in real time (e.g., unencrypted EBS volumes, public S3 buckets, missing CloudTrail)
AWS Security Hub — aggregates findings from GuardDuty, Inspector, Macie into a single compliance posture score
CloudTrail + Athena — query audit logs for unauthorized IAM changes, API calls outside approved regions
IAM Access Analyzer — surfaces external access to resources and unused roles/permissions
Azure Compliance Monitoring — Key Automated Checks
Azure Policy & Defender for Cloud — enforce and score compliance against CIS, NIST SP 800-53, ISO 27001 benchmarks
Microsoft Purview — data classification, governance, and audit trail across Azure and M365
Azure Monitor + Sentinel — SIEM-class alerting on suspicious activity with compliance-relevant playbooks
Privileged Identity Management (PIM) — just-in-time access with mandatory justification and approval workflows
GCP Compliance Monitoring — Key Automated Checks
Security Command Center — organization-wide misconfiguration detection and compliance benchmarking
VPC Service Controls — perimeter security policies that prevent data exfiltration
Cloud Audit Logs — immutable, per-service activity and data access logs
Policy Intelligence — recommends IAM role right-sizing based on actual usage data
🔗
For authoritative cloud security benchmarks, the CIS Benchmarks provide configuration baselines for AWS, Azure, GCP, Kubernetes, and 100+ other platforms — an industry-standard starting point for any cloud compliance monitoring program.
See Gart's Cloud Computing & Security services
Industry-Specific Compliance Monitoring Frameworks
Compliance monitoring requirements differ significantly by industry and geography. Below are the frameworks Gart's clients most commonly monitor against, along with the controls that require continuous (not just periodic) monitoring.
FrameworkIndustry / RegionKey Continuous Monitoring RequirementsResourcesISO 27001Global / All industriesAccess control review, log management, vulnerability scanning, supplier reviewISO.orgSOC 2 Type IISaaS / TechnologyContinuous availability, logical access, change management, incident responseAICPAHIPAAHealthcare (US)ePHI access logs, encryption at rest/transit, workforce activity auditsHHS.govPCI DSS v4.0Payment / E-commerceReal-time network monitoring, file integrity monitoring, quarterly vulnerability scansPCI SSCNIS2EU / Critical sectorsIncident detection within 24h, risk assessments, supply chain security checksENISAGDPREU / Global processing EU dataData subject request tracking, breach detection (<72h notification), processor auditsGDPR.euIndustry-Specific Compliance Monitoring Frameworks
How to prepare for a HIPAA Audit - Gart's PCI DSS Audit guide
First-Hand Experience
What We Usually Find During Compliance Monitoring Reviews
After reviewing postures across dozens of regulated environments, these are the patterns we encounter repeatedly — regardless of organization size.
👥
Incomplete or stale access reviews
Former employees and service accounts with active permissions weeks after departure. IAM hygiene is rarely automated, and reviews are often rubber-stamped.
📋
Missing backup test evidence
Backups appear healthy, but nobody has tested a restore in 6–18 months. Auditors want dated restore test logs with RPO/RTO outcomes, not just success metrics.
📊
Fragmented or incomplete audit logs
Gaps in the log chain (like disabled S3 data-event logging) make it impossible to reconstruct an incident or prove that one didn't happen.
🔔
Alert fatigue masking real issues
Thousands of low-fidelity alerts lead teams to mute notifications or build exceptions, inadvertently disabling detection for real threats.
📄
Policy-to-implementation gaps
Written policies say "encryption required," but reality reveals unencrypted legacy buckets. Continuous monitoring is the only way to detect this drift.
🔧
Automation is first patched, last monitored
CI/CD pipelines move faster than human reviewers. IaC repositories often lack policy-as-code scanning, leaving non-compliant resources active for months.
Featured Success Story
Case study: ISO 27001 compliance for Spiral Technology
→
Compliance Monitoring Tools & Automation
The right tooling depends on your stack, frameworks, and team maturity. Most organizations use a layered approach rather than a single platform:
CategoryRepresentative ToolsBest ForCloud Security Posture Management (CSPM)AWS Security Hub, Wiz, Prisma Cloud, Orca Security, Defender for CloudCloud misconfiguration detection, continuous benchmarkingSIEM / Log ManagementSplunk, Elastic SIEM, Microsoft Sentinel, Datadog SecurityLog correlation, anomaly detection, audit evidenceGRC PlatformsVanta, Drata, Secureframe, ServiceNow GRC, OneTrustEvidence collection automation, audit-ready reportingPolicy-as-Code / IaC ScanningOpen Policy Agent (OPA), Checkov, Terrascan, tfsec, ConftestPrevent non-compliant infrastructure from being deployedVulnerability ManagementTenable Nessus, Qualys, AWS Inspector, Trivy (containers)CVE detection, patch SLA monitoring, container scanningIdentity GovernanceSailPoint, CyberArk, Azure PIM, AWS IAM Access AnalyzerAccess reviews, least-privilege enforcement, PAM
⚠️ Tool sprawl is a compliance risk: More tools mean more integrations to maintain, more alert queues to manage, and more places where evidence can fall through the cracks. Start with native cloud tools and expand deliberately. The Linux Foundation and CNCF maintain open-source compliance tooling for cloud-native environments worth evaluating before adding commercial licenses.
Compliance Monitoring Best Practices
1. Shift compliance left into the development pipeline
The cheapest time to catch a compliance violation is before the resource is deployed. Integrate policy-as-code scanning (OPA, Checkov) into your CI/CD pipeline so that non-compliant Terraform or Helm charts never reach production. Treat compliance failures as build-breaking errors, not post-deploy recommendations.
2. Automate evidence collection — not just detection
Detection without evidence collection is useless at audit time. Configure your monitoring tools to export and archive compliance evidence (configuration snapshots, access review logs, scan reports) automatically to an immutable store. Auditors need evidence from a defined period — not a screenshot taken the morning of the audit.
3. Assign control owners, not just tool owners
Every control needs a named human owner who is accountable for exceptions. When an alert fires that MFA is disabled on a privileged account, "the security team" is not a sufficient owner — a specific person must be on call to investigate and remediate within the SLA.
4. Tune alerts ruthlessly to eliminate fatigue
Compliance monitoring programs that generate thousands of daily alerts quickly become ignored. Start with a small set of high-fidelity, high-impact alerts. Expand incrementally after each is tuned to near-zero false positive rates. A team that responds to 20 real alerts per day is more secure than one drowning in 2,000 noisy ones.
5. Monitor your monitoring
Monitoring pipelines break silently. Log shippers stop, API rate limits are hit, SIEM ingestion queues fill up. Build meta-monitoring to detect when evidence collection or alerting pipelines have gaps — and treat those gaps as compliance findings in their own right.
6. Conduct a quarterly compliance posture review
Beyond continuous automated monitoring, schedule a quarterly human review of the compliance posture. Review open exceptions, re-assess risk scores, retire obsolete controls, and update monitoring scope to cover new systems and regulatory changes.
Compliance Monitoring Checklist for Cloud Teams
A starting point for cloud-first compliance. Each item requires a named owner, a monitoring cadence, and a defined evidence artifact.
✓
MFA enforced on all privileged and administrative accounts
✓
Access reviews completed for all privileged roles (minimum quarterly)
✓
Service accounts audited for least-privilege and no unused permissions
✓
Audit logging enabled and retained (90 days min; 1 year for PCI/HIPAA)
✓
SIEM ingestion health monitored — no silent log gaps
✓
Data-at-rest encryption confirmed on all storage (S3, RDS, EBS, blobs)
✓
TLS 1.2+ enforced; TLS 1.0/1.1 disabled on all endpoints
✓
Encryption key rotation scheduled and verified
✓
Vulnerability scans run weekly; critical/high CVEs remediated within SLA
✓
Patch management SLA compliance tracked and reported
✓
Backups verified complete daily; restore tests documented quarterly
✓
DR test completed at least annually; RPO/RTO outcomes logged
✓
No public cloud storage buckets without explicit business justification
✓
Firewall change log reviewed; unauthorized rule changes alerting
✓
Vendor/third-party access scoped, time-limited, and reviewed quarterly
✓
Incident response plan tested; MTTD and MTTR tracked
✓
Policy-as-code scans integrated into CI/CD pipelines
✓
Compliance evidence archived in immutable storage for audit period
✓
Monitoring pipeline health checked — no silent collection failures
✓
Quarterly posture review conducted with named control owners
Gart Solutions · Compliance Monitoring Services
How Gart Helps You Build a Continuous Compliance Monitoring Program
We work with CTOs, CISOs, and engineering leaders to design, implement, and run compliance monitoring programs that hold up under real auditor scrutiny — not just on paper.
🗺️
Scope & Framework Mapping
We identify applicable frameworks (ISO 27001, SOC 2, HIPAA, PCI DSS, NIS2, GDPR) and map your cloud infrastructure to each control objective.
🔧
Monitoring Setup & Automation
We deploy CSPM tools, SIEM rules, and policy-as-code pipelines — so evidence is collected automatically, not manually on audit day.
📊
Gap Analysis & Risk Register
We deliver a clear view of your current compliance posture, prioritized by risk, with a remediation roadmap and accountable owners.
🔄
Ongoing Reviews & Readiness
Monthly exception reviews and pre-audit evidence packages — so you're never scrambling the week before an official audit.
☁️
Cloud-Native Expertise
AWS, Azure, GCP, Kubernetes, and CI/CD. We speak infrastructure as code and translate compliance into DevOps workflows.
📋
Audit-Ready Deliverables
Exception logs, risk matrices, and control evidence archives. Everything formatted for the specific framework you're being audited against.
Get a Compliance Audit
Talk to an Expert
Fedir Kompaniiets
Co-founder & CEO, Gart Solutions · Cloud Architect & DevOps Consultant
Fedir is a technology enthusiast with over a decade of diverse industry experience. He co-founded Gart Solutions to address complex tech challenges related to Digital Transformation, helping businesses focus on what matters most — scaling. Fedir is committed to driving sustainable IT transformation, helping SMBs innovate, plan future growth, and navigate the "tech madness" through expert DevOps and Cloud managed services. Connect on LinkedIn.

IT infrastructure monitoring is the continuous collection and analysis of performance data — from servers and networks to cloud services and applications — to prevent downtime, reduce costs, and maintain reliability. This guide covers what to monitor, the six major types, a tool comparison table, implementation best practices, and a checklist to get started today.
In today's digital economy, businesses live and die by the reliability of their IT systems. A single hour of unplanned downtime now costs enterprises an average of $300,000, according to research cited by Gartner. Yet many organizations still operate with incomplete visibility into their IT infrastructure — reacting to outages instead of preventing them.
IT infrastructure monitoring closes that gap. It gives engineering teams the real-time intelligence to act before issues become incidents, optimize costs, and build systems that meet the reliability expectations of modern software.
In this guide — built on hands-on experience from hundreds of Gart infrastructure engagements — we cover everything: from the foundational definition and architecture to tools, types, best practices, and a practical implementation checklist.
What Is IT Infrastructure Monitoring?
IT infrastructure monitoring is the systematic process of continuously collecting, analyzing, and acting on telemetry data from every component of an organization's technology environment — including physical servers, virtual machines, containers, cloud services, databases, and network devices — to ensure optimal performance, availability, and security.
Unlike reactive incident response, IT infrastructure monitoring is inherently proactive. Monitoring agents deployed across the environment stream metrics, logs, and traces to a central platform, where anomaly detection and threshold-based alerting surface problems before they impact users.
Why it matters now: Modern software is distributed, cloud-native, and updated continuously. A monolith deployed once a quarter could survive without formal monitoring. A microservices platform deployed dozens of times a day cannot. IT infrastructure monitoring is the operational nervous system that keeps that environment coherent.
The discipline sits at the intersection of three related practices that are often confused:
ConceptCore QuestionPrimary OutputIT Infrastructure MonitoringIs the system healthy right now?Dashboards, alerts, uptime metricsObservabilityWhy is the system behaving this way?Distributed traces, structured logs, high-cardinality metricsSREWhat is our acceptable failure level?SLOs, error budgets, runbooksWhat Is IT Infrastructure Monitoring?
A mature organization needs all three working in concert. The Cloud Native Computing Foundation (CNCF) provides a useful open-source landscape for understanding how these disciplines intersect with tool selection.
How IT Infrastructure Monitoring Works: Architecture Overview
At its core, IT infrastructure monitoring follows a four-layer architecture: data collection, aggregation, analysis, and action. Here is how these layers interact in a modern cloud-native environment.
IT Infrastructure Monitoring — Architecture
1. COLLECTION
Agents, exporters, and instrumentation libraries gather metrics, logs, and traces from every infrastructure component in real time.
2. TRANSPORT
Telemetry is shipped to a central aggregator — via pull (Prometheus) or push (agents streaming to Datadog, Loki, etc.).
3. STORAGE & ANALYSIS
Time-series databases (Prometheus, VictoriaMetrics) store metrics. Log platforms (Loki, Elasticsearch) index events. Trace backends (Tempo, Jaeger) correlate distributed requests.
4. ALERTING & ACTION
Rule-based and SLO-driven alerts route to PagerDuty or Slack. Dashboards surface patterns. Runbooks guide remediation.
The most important design principle: correlation across all three telemetry types. When an alert fires, engineers must be able to jump from the metric spike to the relevant logs and the distributed trace for the same time window — in seconds, not minutes. Tools like Grafana, Datadog, and Dynatrace increasingly make this three-way correlation a single click.
Google's Four Golden Signals framework — Latency, Traffic, Errors, and Saturation — remains the most practical starting point for deciding what to collect and how to alert on it.
74% of enterprises report IT downtime costs exceed $100k per hour (Gartner)
74%
of enterprises report IT downtime costs exceed $100k per hour (Gartner)
4×
faster Mean Time to Detect achieved with centralized monitoring vs. siloed alerts
38%
infrastructure cost reduction Gart achieved for one client via usage-aware automation
Ready to level up your Infrastructure Management? Contact us today and let our experienced team empower your organization with streamlined processes, automation, and continuous integration.
Types of IT Infrastructure Monitoring
Effective IT infrastructure monitoring spans multiple layers. Missing any layer creates blind spots that surface as incidents. These are the six essential types every engineering organization should cover.
🖥️
Server & Host Monitoring
Tracks CPU, memory, disk I/O, and process health on physical and virtual servers. The foundational layer for any monitoring program.
🌐
Network Monitoring
Monitors latency, packet loss, bandwidth utilization, and throughput across switches, routers, and VPNs. Critical for diagnosing connectivity-related incidents.
☁️
Cloud Infrastructure Monitoring
Provides visibility into AWS, Azure, and GCP resources — EC2 instances, managed databases, load balancers, and serverless functions.
📦
Container & Kubernetes Monitoring
Tracks pod restarts, OOMKill events, HPA scaling, and control plane health. The standard stack: kube-state-metrics + Prometheus + Grafana.
⚡
Application Performance Monitoring (APM)
Focuses on runtime application behavior: response times, error rates, database query performance, and memory leaks.
🔒
Security Monitoring
Detects anomalies in authentication events, network traffic, and container runtime behavior using tools like Falco for threat detection.
For teams with cloud-native environments, the Linux Foundation and its CNCF project maintain an extensive open-source ecosystem covering each of these layers — useful for evaluating vendor-neutral tooling options.
What Should You Monitor? Key Metrics by Layer
Identifying the right metrics is more important than collecting everything. Cardinality explosions and alert fatigue are common consequences of monitoring too broadly without structure. The table below maps infrastructure layer to the most important metric categories, grounded in the Google SRE Golden Signals and the USE method (Utilization, Saturation, Errors).
Infrastructure LayerKey Metrics to TrackAlerting PriorityServers / HostsCPU utilization, memory usage, disk I/O, network throughput, process healthHighNetworkLatency, packet loss, bandwidth usage, throughput, BGP statusHighApplicationsResponse time (p95/p99), error rates, request throughput, transaction volumeCriticalDatabasesQuery response time, connection pool usage, replication lag, slow queriesHighKubernetes / ContainersPod restarts, OOMKill events, HPA scaling, node pressure, ingress 5xx rateCriticalCloud CostCost per service, idle resource spend, reserved instance utilizationMediumSecurityFailed logins, unauthorized access attempts, anomalous network traffic, CVE alertsCritical
Practical advice from Gart audits: Most teams monitor what is easy to collect — CPU and memory — but leave deployment failure rates and user-facing latency untracked. Always start from the user experience and work inward toward infrastructure. If a metric does not map to a business outcome, question whether it needs an alert.
IT Infrastructure Monitoring Tools Comparison (2026)
Choosing the right monitoring tool depends on your team's size, cloud footprint, budget, and maturity stage. Below is a concise comparison of the most widely adopted platforms, based on Gart's hands-on implementation experience and public vendor documentation.
ToolBest ForPricingKey StrengthsMain LimitationsPrometheusMetrics collection, Kubernetes environmentsFree / OSSPull-based, powerful PromQL query language, massive ecosystemNo long-term storage natively; high cardinality causes performance issuesGrafanaVisualization & dashboardsFreemiumMulti-source dashboards, rich plugin library, Grafana Cloud optionDashboard sprawl without governance; alerting UX not always intuitiveDatadogFull-stack observability, enterprisePer host/GBBest-in-class UX, unified metrics/logs/traces/APM, AI featuresExpensive at scale; bill shock without governance; vendor lock-in riskNagiosNetwork & host checks, legacy environmentsFreemiumHighly extensible plugin architecture, battle-tested for 20+ yearsDated UI; complex config for large deployments; limited cloud-native supportZabbixBroad infrastructure coverage, on-premisesFree / OSSRich auto-discovery, custom alerting, strong communitySteeper learning curve; resource-intensive at scale; UI can overwhelmNew RelicAPM & user monitoringPer user/usageDeep transaction tracing, browser/mobile RUM, synthetic monitoringPricing model shift makes cost unpredictable; can be costly for large teamsDynatraceEnterprise AI-driven monitoringPer host / DEM unitAI root cause analysis (Davis), auto-discovery, full-stack, cloud-nativePremium pricing, complex licensing, steep onboarding curveGrafana LokiLog aggregation, cost-conscious teamsFreemiumLabel-based indexing makes it very cost-efficient; integrates natively with GrafanaFull-text search slower than Elasticsearch; less mature than ELK
For most cloud-native teams starting out, a Prometheus + Grafana + Loki + Tempo stack provides comprehensive coverage at near-zero licensing cost. As you scale or need enterprise SLAs, Datadog or Dynatrace become serious options — but budget accordingly and implement cost governance from day one.
The Platform Engineering community has produced a useful comparison of open-source and commercial observability stacks that is worth reviewing when evaluating options for multi-team environments.
IT Infrastructure Monitoring Best Practices
Based on Gart infrastructure audits across SaaS platforms, healthcare systems, fintech products, and Kubernetes-native environments, these are the practices that separate mature monitoring programs from those that generate noise without insight.
1. Define monitoring requirements during sprint planning — not after deployment
Observability is a feature, not an afterthought. Every new service should ship with a defined set of SLIs (Service Level Indicators), dashboards, and alert runbooks. If a team cannot describe what "healthy" looks like for a service, it is not ready for production.
2. Use structured alerting frameworks — not static thresholds
Alerting on "CPU > 80%" generates noise during every traffic spike. SLO-based alerting, built on error budget burn rates, is dramatically more actionable. An alert that fires because "we will exhaust the monthly error budget in 24 hours" gives teams time to act before users are impacted. AWS, Google Cloud, and Azure all provide native guidance on monitoring best practices aligned with this approach.
3. Deploy monitoring agents across your entire environment — not just key apps
Partial coverage creates blind spots. Deploy collection agents — whether node_exporter, the Google Ops Agent, or AWS Systems Manager — across the full production environment. A host that falls outside the monitoring perimeter will be the one that causes your next incident.
4. Instrument with OpenTelemetry from day one
Using a vendor-proprietary instrumentation agent locks you to that vendor's backend. OpenTelemetry provides a single SDK that exports metrics, logs, and traces to any compatible backend — Prometheus, Datadog, Jaeger, Grafana Tempo, or others. It is the de facto instrumentation standard endorsed by the CNCF and increasingly the only approach that makes long-term sense.
5. Automate: adopt AIOps for infrastructure monitoring
Modern IT infrastructure monitoring tools offer AI-powered anomaly detection that learns baseline behavior for every service and surface deviations before thresholds are breached. Platforms like Dynatrace (Davis AI) and Datadog (Watchdog) reduce both Mean Time to Detect and alert fatigue simultaneously. For teams not yet ready for commercial AI tooling, Prometheus anomaly detection via MetricSets and Alertmanager provides a strong open-source baseline.
6. Create filter sets and custom dashboards for each team
A unified platform should still deliver role-specific views. Infrastructure engineers need node-level dashboards. Developers need service-level RED dashboards. Finance teams need cost allocation views. Tools like Grafana and Datadog support this through tag-based filtering and custom dashboard permissions. Organize hosts and workloads by tag from day one — retrofitting tags across an existing environment is painful.
7. Test your monitoring — with chaos engineering
The most common finding in Gart monitoring audits: alerts that are configured but never fire — even when the system is broken. Chaos engineering experiments (Chaos Mesh, Chaos Monkey) validate that dashboards and alerts actually trigger when something breaks. If your monitoring cannot detect a simulated failure, it will not detect a real one. The Green Software Foundation also notes that effective monitoring is foundational to sustainable infrastructure — you cannot optimize what you cannot measure.
8. Review and prune regularly
A dashboard no one opens is a maintenance cost with no return. A monthly review cycle — checking which alerts never fire and which dashboards are never visited — keeps the monitoring program lean and trusted.
Use Cases of IT Infrastructure Monitoring
DevOps engineers, SREs, and platform teams apply IT infrastructure monitoring across four primary operational scenarios:
Troubleshooting performance issues. When a latency spike or error rate increase hits, monitoring tools let engineers immediately identify the failing host, container, or downstream service — without manual log archaeology. Mean Time to Detect drops from hours to minutes when logs, metrics, and traces are correlated on a single platform.
Optimizing infrastructure cost. Historical utilization data surfaces overprovisioned servers, idle EC2 instances, and underutilized database clusters. Organizations consistently find 15–40% of cloud spend is recoverable through monitoring-driven right-sizing. Read how Gart helped an entertainment platform achieve AWS cost optimization through infrastructure visibility.
Forecasting backend capacity. Trend analysis on resource consumption during product launches, seasonal traffic peaks, or user growth allows infrastructure teams to provision ahead of demand — rather than reacting to overloaded nodes during the event.
Configuration assurance testing. Monitoring the infrastructure during and after feature deployments validates that new releases do not degrade existing services. This is the operational backbone of safe continuous delivery.
Ready to level up your Infrastructure Management? Contact us today and let our experienced team empower your organization with streamlined processes, automation, and continuous integration.
Our Monitoring Case Study: Music SaaS Platform at Scale
A B2C SaaS music platform serving millions of concurrent global users needed real-time visibility across a geographically distributed infrastructure spanning three AWS regions. Prior to engaging Gart, the team relied on ad hoc CloudWatch dashboards with no centralized alerting or SLO definitions.
Gart integrated AWS CloudWatch and Grafana to deliver unified dashboards covering regional server performance, database query times, API error rates, and streaming latency per region. We defined SLOs for the five most critical user-facing services and implemented SLO-based burn rate alerting using Prometheus Alertmanager routed to PagerDuty.
"Proactive monitoring alerts eliminated operational interruptions during our global release events. The team now deploys with confidence instead of hoping nothing breaks."— Engineering Lead, Music SaaS Platform (under NDA)
The outcome: Mean Time to Detect dropped from over 20 minutes to under 4 minutes. Infrastructure cost reduced by 22% through identification of overprovisioned regions. See Gart's IT Monitoring Services for details on what this engagement included.
Monitoring Checklist: Where to Start
Distilled highest-impact actions based on patterns observed across Gart’s client audits:
Define SLIs and SLOs for all user-facing services before configuring alerts
Deploy monitoring agents across 100% of production — not just key hosts
Implement Google's Four Golden Signals (Latency, Traffic, Errors, Saturation)
Centralize logs in a structured format (JSON) via Loki or Elasticsearch
Set up distributed tracing with OpenTelemetry before launching new services
Configure SLO-based burn rate alerting to replace pure static thresholds
Create role-specific dashboards (Infra, Dev, Finance) using tag-based filtering
Write a runbook for every alert before enabling it in production
Run a chaos engineering test to verify that alerts fire correctly
Establish a monthly review cycle to prune unused alerts and dashboards
Gart Solutions · Infrastructure Monitoring Services
Is Your Monitoring Stack Actually Working When It Matters?
Most teams discover monitoring gaps during an incident — not before. Gart identifies blind spots and alert fatigue, delivering a concrete remediation roadmap.
🔍
Infrastructure Audit
Observability assessment across AWS, Azure, and GCP.
📐
Architecture Design
Custom monitoring design tailored to your team size and budget.
🛠️
Implementation
Hands-on deployment of Prometheus, Grafana, Loki, and OpenTelemetry.
📊
SLO & DORA Metrics
Error budget alerting and DORA dashboards for performance.
☸️
Kubernetes Monitoring
Full-stack observability for EKS, GKE, and AKS environments.
⚡
Incident Response
Runbook creation and PagerDuty/OpsGenie integration.
Book a Free Assessment
Explore Services →
No commitment required · Free 30-minute discovery call · Rated 4.9/5 on Clutch
Roman Burdiuzha
Co-founder & CTO, Gart Solutions · Cloud Architecture Expert
Roman has 15+ years of experience in DevOps and cloud architecture, with prior leadership roles at SoftServe and lifecell Ukraine. He co-founded Gart Solutions, where he leads cloud transformation and infrastructure modernization engagements across Europe and North America. In one recent client engagement, Gart reduced infrastructure waste by 38% through consolidating idle resources and introducing usage-aware automation. Read more on Startup Weekly.
Wrapping Up
In conclusion, infrastructure monitoring is critical for ensuring the performance and availability of IT infrastructure. By following best practices and partnering with a trusted provider like Gart, organizations can detect issues proactively, optimize performance and be sure the IT infrastructure is 99,9% available, robust, and meets your current and future business needs. Leverage external expertise and unlock the full potential of your IT infrastructure through IT infrastructure outsourcing!
Let’s work together!
See how we can help to overcome your challenges
Contact us

DevOps monitoring is the continuous practice of collecting, analyzing, and acting on telemetry data from every layer of your software delivery system — infrastructure, applications, pipelines, and user experience. It is the operational nervous system that connects what your team ships with how that software actually behaves in production.
Without effective DevOps monitoring, you are flying blind. You ship code and hope it works. You hear about incidents from users, not dashboards. You spend hours — not minutes — isolating root causes. In a CI/CD world, where releases happen daily or even hourly, that is simply not a viable operating model.
At Gart, we have designed and audited monitoring stacks for SaaS platforms, healthcare systems, fintech products, and Kubernetes-native environments across AWS, Azure, and GCP. This guide distills those lessons into a practical reference: what to monitor, which frameworks to apply, which tools to choose, and what patterns to avoid.
If you are assessing your entire infrastructure health, not just monitoring, see our IT Audit Services — the starting point for many of our cloud optimization engagements.
What is DevOps Monitoring?
DevOps monitoring is the ongoing process of tracking the health, performance, and behavior of systems and software across the full DevOps lifecycle — from code commit and CI/CD pipeline to production infrastructure and end-user experience — to enable rapid detection, diagnosis, and resolution of issues.
It covers the entire technology stack: cloud resources, servers, containers, microservices, databases, networks, application code, and deployment pipelines. The goal is always the same — turn raw system data into actionable insight before a problem reaches your users.
DevOps monitoring is not a passive activity. It drives decisions: when to scale, when to roll back a deployment, when to page an engineer, and when to invest in architecture changes. In mature teams, monitoring outputs feed directly into planning — influencing sprint priorities and capacity forecasts.
DevOps Monitoring vs Observability vs SRE
These three terms are often used interchangeably, but they describe distinct — and complementary — disciplines.
ConceptCore QuestionPrimary OutputsWho Owns ItDevOps MonitoringIs the system healthy right now?Dashboards, alerts, uptime metricsDevOps / Platform teamsObservabilityWhy is the system behaving this way?Distributed traces, structured logs, high-cardinality metricsEngineering teams broadlySRE (Site Reliability Engineering)What is our acceptable risk level, and are we within it?SLOs, error budgets, runbooks, postmortemsSRE / Reliability teams
Monitoring tells you what is happening. Observability helps you understand why it is happening. SRE defines how much failure is acceptable. A mature DevOps organization needs all three working in concert. The Cloud Native Computing Foundation (CNCF) provides a useful open-source landscape for understanding how these disciplines intersect with tooling choices.
Why Monitoring Matters in a DevOps Lifecycle
The DevOps philosophy — ship fast, iterate continuously, fail safely — only holds up when you can see what is happening in production. Here is the business case, without the fluff.
Reduced MTTD and MTTR. Mean time to detect (MTTD) and mean time to resolve (MTTR) are the two most important incident metrics. Centralized monitoring with clear alerting cuts both, often dramatically. In a recent Gart engagement with a cloud-native SaaS platform, migrating from siloed per-service alerts to a unified observability stack reduced MTTD from 22 minutes to under 4.
Deployment confidence. With solid monitoring in place, teams can deploy more frequently because they know they will catch regressions immediately — before users do.
Proactive capacity planning. Trend analysis on CPU, memory, and request volume lets you scale ahead of demand rather than reacting to overloaded nodes.
Compliance and auditability. Regulatory frameworks — including HIPAA, PCI-DSS, and SOC 2 — require detailed audit logs. Monitoring infrastructure naturally produces these artefacts.
Cost control. Visibility into resource utilization reveals waste: idle EC2 instances, over-provisioned RDS clusters, log storage costs that crept up unnoticed.
Key Takeaway: DevOps monitoring is not a cost centre — it is the mechanism by which engineering teams maintain delivery speed without sacrificing reliability.
The Three Pillars: Metrics, Logs & Traces
All DevOps monitoring telemetry ultimately maps to three signal types. Understanding them is the foundation for designing any monitoring architecture. The OpenTelemetry project has made significant progress in standardizing how all three are collected and correlated.
📊
Metrics
Numerical data points sampled over time. CPU at 78%, p95 API latency at 320ms, request rate at 1,400 RPS. Ideal for alerting and trend visualization. Cheap to store and fast to query.
📄
Logs
Timestamped records of events. Application errors, user actions, deployment events. Rich in context but expensive at scale. Structured logs (JSON) are far easier to query than unstructured text.
🔗
Traces
End-to-end records of a request as it flows through distributed services. Essential for diagnosing latency in microservices where a single user action touches ten or more services.
The goal is correlation: when an alert fires, you should be able to jump from the metric spike to the relevant logs and the distributed trace for the same time window. Tools like Grafana, Datadog, and Dynatrace increasingly make this three-way correlation a single click.
Best Practices for Each Pillar
Metrics: Define which metrics map to business outcomes before wiring up dashboards. Avoid cardinality explosions — labels with unbounded values (user IDs, request IDs) can cripple Prometheus at scale.
Logs: Use structured logging (JSON) from day one. Centralize with ELK Stack(Elasticsearch, Logstash, Kibana) or Grafana Loki. Never log sensitive PII — build a scrubbing layer into your log pipeline.
Traces: Instrument with OpenTelemetry from the start — it gives you vendor-neutral traces exportable to Jaeger, Zipkin, Tempo, Datadog, or any other backend. Sample intelligently: 100% trace volume is rarely justified and gets expensive fast.
Golden Signals, RED & USE Methods
Rather than monitoring everything, mature DevOps teams use structured frameworks to pick the right metrics. These are the three most widely adopted.
FrameworkMetricsBest Applied ToGolden Signals(Google SRE Book)Latency, Traffic, Errors, SaturationUser-facing services, APIs, external endpointsRED MethodRate, Errors, DurationMicroservices, request-driven workloadsUSE MethodUtilization, Saturation, ErrorsInfrastructure resources (CPU, memory, disk, network)
In practice, most teams combine all three. Use the USE method to watch your nodes and pods, the RED method to watch your microservices, and Golden Signals to define the SLIs you report to the business.
Types of DevOps Monitoring
Effective monitoring spans every layer of the technology stack. Missing any layer creates blind spots that will eventually surface as incidents.
Cloud Level Monitoring
Tracks the health, cost, and compliance of cloud provider resources. Each major cloud offers native tooling as a baseline.
AWS: CloudWatch (metrics, logs, alarms, dashboards), X-Ray (tracing), Config (compliance), Cost Explorer (spend).
Azure: Azure Monitor (metrics + logs), Application Insights (APM), Sentinel (security), Cost Management.
GCP: Cloud Monitoring + Cloud Logging (formerly Stackdriver), Error Reporting, Cloud Trace. Detailed documentation is available in the Google Cloud Operations Suite.
Native cloud monitoring is a solid starting point, but it rarely provides a unified view across multi-cloud environments or integrates well with application-layer telemetry. Most mature teams complement it with an independent observability platform.
Infrastructure Level Monitoring
Covers physical and virtual servers, databases, networking equipment, and storage. Key metrics to track at this layer: CPU utilization, memory usage, disk I/O and capacity, network throughput and packet loss, process health, and database connection pool exhaustion. Tools like Prometheus with node_exporter are the open-source default for this layer.
Container & Orchestration Monitoring (Kubernetes)
Kubernetes environments require monitoring at multiple sub-layers simultaneously: cluster nodes, individual pods, deployments, services, and the control plane itself.
Pod restarts and OOMKill events
Node resource pressure and evictions
Deployment rollout status and error rates
Horizontal Pod Autoscaler (HPA) scaling events
Persistent volume claims and storage usage
Ingress request rates and error rates
The standard open-source stack here is kube-state-metrics + Prometheus + Grafana, often deployed via the kube-prometheus-stack Helm chart. For managed Kubernetes, native integrations (AWS EKS Container Insights, GKE Managed Prometheus) reduce the operational overhead.
Application Performance Monitoring (APM)
APM focuses on how your code behaves at runtime: response times, error rates, database query performance, external API latency, memory leaks, and thread deadlocks. It provides the application-level context that infrastructure metrics alone cannot give you. Popular APM platforms include New Relic, Datadog APM, Dynatrace, and the open-source Elastic APM.
Security Monitoring
Often treated separately, security monitoring should be an integrated layer: anomaly detection on authentication events, network traffic analysis, dependency vulnerability scanning in CI/CD, and runtime threat detection in containers (Falco is the open-source leader here).
User Experience & Synthetic Monitoring
Backend health does not guarantee good user experience. Synthetic monitoring runs scripted user journeys against your application from multiple geographic locations to measure availability and performance as users actually experience it. Combine this with Real User Monitoring (RUM) to capture field data from actual browser and mobile sessions.
How to Monitor CI/CD Pipelines
This is one of the most underserved areas in typical DevOps monitoring setups. Teams instrument their production systems carefully but leave their delivery pipelines nearly opaque. If you cannot see what is happening in your CI/CD pipelines, you cannot improve deployment velocity or catch quality regressions early.
Key CI/CD Metrics to Track
Deployment frequency: how often you successfully ship to production.
Lead time for changes: time from code commit to production deployment.
Change failure rate: percentage of deployments causing a production incident or rollback.
MTTR (Mean Time to Restore): how long it takes to recover from a production failure.
Build duration trends: slow CI is a developer experience and productivity problem.
Test flakiness rate: unreliable tests erode trust in the pipeline and get ignored.
These four metrics — frequency, lead time, failure rate, MTTR — are the DORA metrics established by the research community via the Linux Foundation and DevOps Research & Assessment group. They are the industry standard for measuring DevOps performance.
How to Implement It
Most CI platforms (GitHub Actions, GitLab CI, Jenkins, CircleCI) can export pipeline events and durations to Prometheus via exporters or webhooks. From there, Grafana dashboards surface the DORA metrics in near-real-time. If you use Datadog or New Relic, both have native CI visibility integrations.
SLIs, SLOs & Error Budgets
Without SLOs, monitoring produces data without direction. SLOs (Service Level Objectives) are the mechanism that connects your monitoring to business outcomes.
SLI (Service Level Indicator): a specific metric used to measure service health. Example: "the proportion of API requests completed in under 500ms."
SLO (Service Level Objective): the target for that metric. Example: "99.5% of API requests must complete in under 500ms, measured over a rolling 28-day window."
Error Budget: the allowable failure rate implied by the SLO. A 99.5% SLO means you have a 0.5% error budget — approximately 3.6 hours of downtime per month. When the budget is exhausted, reliability work takes priority over feature development.
SLO-based alerting is far more actionable than threshold alerting. Instead of alerting when CPU exceeds 80%, you alert when your error budget burn rate is high enough to exhaust the monthly budget within 24 hours — giving your team time to act before users are significantly impacted.
What to Monitor by Team Stage
Monitoring needs differ significantly depending on where your organization is in its DevOps maturity journey. This practical framework — based on patterns we observe in client engagements — helps teams prioritize correctly rather than trying to build enterprise-grade observability on day one.
Stage 1
Startup / Early Stage
Basic uptime checks (Uptime Robot, Freshping)
Error rate from application logs
CPU & memory per server/container
Deployment success / failure
On-call via simple alerting (Slack / PagerDuty)
Stage 2
Scale-Up
Prometheus + Grafana for metrics
Centralized log aggregation (Loki or ELK)
APM on all user-facing services
Basic SLOs defined for critical paths
CI/CD pipeline metrics & failure rates
Database slow-query monitoring
Stage 3
Enterprise / Mature
Full distributed tracing (OpenTelemetry)
SLO-based alerting with error budgets
Synthetic monitoring + RUM
Security monitoring (Falco, SIEM integration)
FinOps dashboards (cost per service)
Chaos engineering with observability validation
DevOps Monitoring Tools Compared
This guide is based on Gart's experience designing monitoring stacks for cloud and Kubernetes environments, combined with vendor documentation and public best practices. Tool selection should reflect your team's maturity, budget, and cloud footprint — there is no universally correct choice.
ToolBest ForPricing ModelStrengthsLimitationsPrometheusMetrics collection, KubernetesFREE / OSSPull-based, powerful query language (PromQL), huge ecosystemNo long-term storage natively; high cardinality causes performance issuesGrafanaVisualization & dashboardsFREE OSS + SAASMulti-source dashboards, plugins, alerting, Grafana CloudDashboard sprawl without governance; alerting UX not always intuitiveGrafana LokiLog aggregationFREE OSS + SAASCost-efficient (indexes labels, not content), Grafana-nativeFull-text search slower than Elasticsearch; less mature than ELKELK StackLog search & analyticsFREE OSS + SAASPowerful full-text search, Kibana analytics, mature ecosystemResource-heavy, operationally complex, storage costs grow fastDatadogFull-stack observabilityPER HOST / GBBest-in-class UX, unified metrics/logs/traces/APM, AI featuresExpensive at scale; vendor lock-in risk; bill shock without governanceNew RelicAPM & user monitoringPER USER / USAGEDeep transaction tracing, browser/mobile RUM, syntheticsPricing model changed significantly; can be costly for large teamsDynatraceEnterprise AI-driven monitoringPER HOST / DEM UNITAI-powered root cause analysis (Davis), auto-discovery, full-stackPremium pricing, complex licensing, steep learning curveJaeger / TempoDistributed tracingFREE / OSSOpenTelemetry-native, vendor-neutral, Grafana Tempo integrates seamlesslyJaeger: operational complexity; Tempo: queries slower without search indexOpenTelemetryInstrumentation standardFREE / OSSVendor-neutral, covers metrics/logs/traces, growing communityInstrumentation effort upfront; some language SDKs still maturingDevOps Monitoring Tools Compared
For most cloud-native teams starting out, a Prometheus + Grafana + Loki + Tempo stack provides comprehensive coverage at near-zero licensing cost. As you scale or need enterprise support, Datadog or Dynatrace become serious options — but budget accordingly.
Sample Monitoring Architecture for Kubernetes
For a production Kubernetes-based SaaS stack, this is the monitoring baseline we recommend and implement at Gart.
In practice: For a Kubernetes-based SaaS stack, the 12 signals we track in every production environment are pod restarts, OOMKill events, p95 API latency, queue depth, DB slow queries, deployment failure rate, HPA scaling events, node disk pressure, ingress error rate (5xx), trace error rate per service, log error volume, and customer-facing uptime. These map directly to the Four Golden Signals and cover the most common failure modes.
Architecture Overview
Collection layer: kube-state-metrics, node_exporter, cAdvisor → Prometheus; application logs → Promtail → Loki; traces via OpenTelemetry Collector → Grafana Tempo.
Storage layer: Prometheus with Thanos or VictoriaMetrics for long-term metrics retention; Loki for logs; S3-backed object storage for traces.
Visualization layer: Grafana with pre-built Kubernetes dashboards (Node Exporter Full, Kubernetes Cluster, per-service RED dashboards).
Alerting layer: Prometheus Alertmanager → PagerDuty / OpsGenie for on-call routing; Slack for informational alerts. Alert rules follow SLO burn rate logic, not simple thresholds.
Security layer: Falco for runtime threat detection; OPA/Kyverno for policy enforcement; audit logs shipped to the central log platform.
Common Monitoring Mistakes We See in Audits
These are the patterns that appear repeatedly in our infrastructure audits — across teams of all sizes and at all cloud maturity levels.
Monitoring only what is easy to collect, not what matters. CPU and memory metrics are collected everywhere, but deployment failure rates and user-facing latency are often absent. Start from the user and work inward.
Alert fatigue from threshold-only alerting. Setting a static alert at "CPU > 80%" generates noise during normal traffic spikes. SLO-based and anomaly-based alerting dramatically reduces false-positive rates.
No ownership of alerts. Alerts fire into a shared Slack channel with no assigned responder. Every alert needs an owner and a runbook — otherwise the team learns to ignore them.
Log volume without log value. Teams log everything at DEBUG level in production, generating gigabytes per hour of data that is never queried. Define what you actually need to debug incidents and log that, structured.
Treating monitoring as a set-and-forget task. Systems change. Deployments change the cardinality of your metrics. New services appear. Monitoring configurations need a regular review cycle — quarterly at minimum.
Cardinality explosions in Prometheus. Adding high-cardinality labels (user IDs, request IDs, session tokens) to Prometheus metrics is one of the fastest ways to crash a Prometheus instance. Label design matters as much as metric selection.
Ignoring monitoring costs. Log ingestion and storage in SaaS platforms (Datadog, Splunk) can become a significant budget item. Implement log sampling, retention policies, and cost dashboards alongside your observability stack.
Best Practices for DevOps Monitoring
Define monitoring requirements during sprint planning — not after deployment. Observability is a feature, not an afterthought.
Use the RED method for every new microservice from day one: instrument Rate, Errors, and Duration before the service goes to production.
Write runbooks for every alert that fires. If your team cannot describe what to do when an alert fires, the alert is not ready to go live.
Test your monitoring. Chaos engineering experiments (Chaos Monkey, Chaos Mesh) validate that your dashboards and alerts actually fire when something breaks.
Use OpenTelemetry for instrumentation from the start. It prevents vendor lock-in and gives you flexibility to swap backends as your needs evolve.
Implement log sampling in high-volume services. 100% log capture at 100,000 RPS is rarely necessary and is always expensive.
Review and prune dashboards regularly. A dashboard no one opens is a maintenance cost with no return.
Correlate monitoring data with deployment events. A spike in errors 3 minutes after a deployment is almost certainly caused by that deployment — your tools should surface this automatically.
Real-World Monitoring Use Cases
Music SaaS Platform: Centralized Monitoring at Scale
A B2C SaaS music platform serving millions of concurrent global users needed real-time visibility across a geographically distributed infrastructure. Gart integrated AWS CloudWatch and Grafana to deliver dashboards covering regional server performance, database query times, API error rates, and streaming latency per region. The result: proactive alerts eliminated operational interruptions during global release events, and the team gained the visibility needed to scale confidently. Read the full case study here.
Digital Landfill Platform: IoT-Scale Environmental Monitoring
The elandfill.io platform required monitoring of methane emission sensors across multiple countries, with strict regulatory compliance requirements. Gart designed a cloud-agnostic architecture using Prometheus for metrics, Grafana for per-country dashboards, and custom exporters to ingest IoT sensor data. Beyond improving emission forecasting accuracy, the monitoring infrastructure simplified regulatory compliance reporting — turning what was previously a manual audit process into an automated, continuous data stream. Read the full case study here.
Future of DevOps Monitoring
The trajectory of DevOps monitoring is moving in two parallel directions: greater automation and greater standardization.
AI-assisted anomaly detection is already commercially available in platforms like Dynatrace (Davis AI), Datadog (Watchdog), and New Relic (applied intelligence). These systems learn baseline behavior for every service and surface deviations before they breach human-defined thresholds — reducing both MTTD and alert fatigue simultaneously.
OpenTelemetry as a universal standard is accelerating. Within the next few years, proprietary instrumentation agents will likely become optional for most teams — replaced by a single OpenTelemetry SDK that exports to any backend. This fundamentally changes the vendor dynamics of the observability market.
FinOps integration is the emerging frontier: teams increasingly want to see cost data as a monitoring signal — cost per request, cost per deployment, cost per team — sitting alongside performance and reliability data in the same observability platform.
Platform Engineering is changing who owns monitoring. As internal developer platforms mature, observability is becoming a platform capability delivered to product teams — rather than something each team configures independently.
Watch the webinar about Monitoring DevOps
Gart Solutions · DevOps & Cloud Engineering
Is Your Monitoring Stack Actually Working When It Matters?
Most teams discover monitoring gaps during an incident — not before. Gart's monitoring assessment identifies blind spots, alert fatigue, and missing SLOs across your cloud environment, then delivers a concrete roadmap.
🔍
Infrastructure & observability audit across AWS, Azure, and GCP
📐
Custom monitoring architecture design for your specific stack
🛠️
Implementation: Prometheus, Grafana, Loki, OpenTelemetry
📊
SLO definition, error budget alerting, and DORA metrics
☸️
Kubernetes-native monitoring for EKS, GKE, and AKS
⚡
Incident response runbooks and on-call process design
Book a Monitoring Assessment
Explore DevOps Services →
No commitment required — we start with a free 30-minute discovery call to understand your environment.
Roman Burdiuzha
Co-founder & CTO, Gart Solutions · Cloud Architecture Expert
Roman has 15+ years of experience in DevOps and cloud architecture, with prior leadership roles at SoftServe and lifecell Ukraine. He co-founded Gart Solutions, where he leads cloud transformation and infrastructure modernization engagements across Europe and North America. In one recent client engagement, Gart reduced infrastructure waste by 38% through consolidating idle resources and introducing usage-aware automation. Read more on Startup Weekly.