

- What is DevSecOps?
- DevSecOps vs DevOps: What’s the Difference?
- How DevSecOps Works in a CI/CD Pipeline
- Shift-Left Security: Why Catching Bugs Earlier Changes Everything
- DevSecOps Tools: A Practical Comparison
- DevSecOps for Kubernetes: Securing Container Workloads
- Business Benefits of DevSecOps
- DevSecOps Adoption Challenges (and How to Solve Them)
- DevSecOps Best Practices
- DevSecOps Practices in the Context of Modern Challenges
- The Path of Application Security Practices Transformation
- DevSecOps in the Current Landscape
- Practices of DevSecOps in the Context of Modern Challenges
- Triggers for Implementation and Recommendations
- When Should Your Organization Start With DevSecOps?
The bigger your product and the more companies it serves, the more attractive a target it becomes for attackers. They might degrade your system performance, steal user data, or silently compromise your supply chain for months before detection. Traditional approaches — adding security reviews at the end of a release cycle — simply cannot keep pace with modern development velocity.
DevSecOps is the answer. It is a methodology that embeds security as a continuous, automated responsibility shared by development, operations, and security teams — not a final gate before deployment. At Gart Solutions, we implement DevSecOps pipelines for clients across FinTech, Healthcare, SaaS, and cloud-native environments. This guide distils what we have learned from dozens of real-world implementations.
⚡ Key Takeaways
- DevSecOps integrates security into every stage of the software development lifecycle — not just at the end.
- Shift-left security catches vulnerabilities earlier, when they cost 6–100× less to fix than in production.
- The core DevSecOps toolchain covers SAST, secrets scanning, container image scanning, IaC analysis, and runtime monitoring.
- DevSecOps is now a mainstream practice adopted by more than 50% of enterprise teams (Gartner).
- Teams of 50+ developers, microservices architectures, and regulated industries are the strongest candidates for DevSecOps adoption.
What is DevSecOps?
DevSecOps (Development, Security, and Operations) is an approach to software delivery that integrates automated security controls into every phase of the CI/CD pipeline — from the first line of code to production runtime. The goal is to make security a shared, continuous responsibility rather than a handoff that happens after development is complete.
Think of it like building fire suppression into a skyscraper’s architecture from the blueprint stage, rather than bolting extinguishers to the walls once the building is finished. DevSecOps embeds the equivalent of smoke detectors, sprinkler systems, and evacuation routes directly into your development process.
According to Gartner’s Hype Cycle for Application Security, DevSecOps has reached the Plateau of Productivity — meaning it is now a mature, mainstream practice adopted by more than 50% of enterprise engineering teams. It is no longer an experiment; it is a competitive baseline.
Definition: DevSecOps = continuous security automation integrated across the entire software development lifecycle (SDLC), with shared ownership across Dev, Sec, and Ops teams.
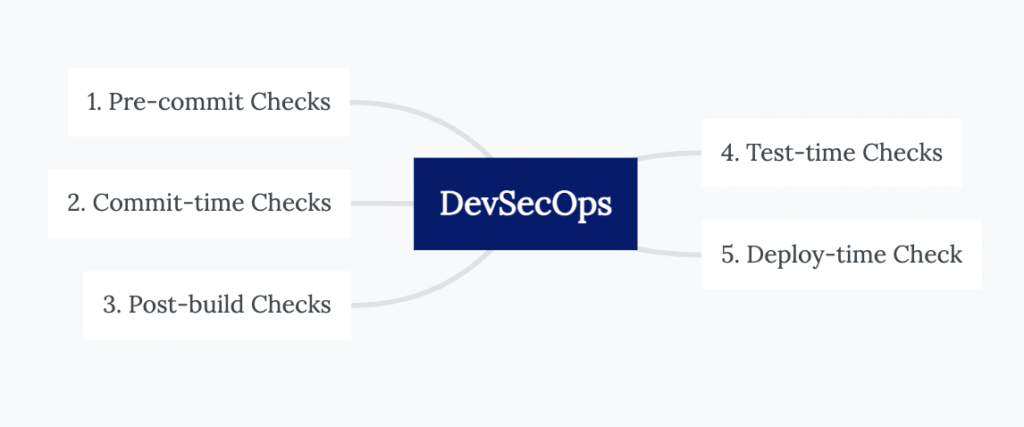
Pre-commit Checks. Code inspection to detect the presence of sensitive information (such as passwords, secrets, tokens, etc.) that should not be included in the Git history.
Commit-time Checks. Checks performed during the commit process to ensure the correctness and security of the code in the repository.
Post-build Checks. Checks carried out after the application has been built, including artifact testing (e.g., docker images).
Test-time Checks. Vulnerability testing of the deployed application (e.g., API scanning for common vulnerabilities).
Deploy-time Checks. Checks performed during the application deployment to assess the infrastructure for vulnerabilities.
A few years ago, DevSecOps was primarily relevant for large companies with numerous products and extensive development teams. However, today, its importance is gradually extending to smaller players in the industry.
Previously, development efforts prioritized swiftly creating a pilot version and dealing with security concerns later. Yet, investors now grasp the significance of airtight security and raise their inquiries. As a result, DevSecOps becomes increasingly relevant for a broader audience. However, for teams with fewer than 50 developers, security concerns may not be as pressing, and they are often handled through simpler, standard methods (in practice). Their main focus is on business functionality, with security addressed in fragments after product creation. Vulnerabilities are often identified in finished products using free scanners and penetration testing, and then remedied. As businesses grow and demand higher quality, security gains paramount importance and becomes deeply ingrained in the development process.
Consequently, companies reach a new level with their unique requirements. The market demands faster responses, driving the significance of the Time To Market metric. This urges the automation of every feasible aspect. Code is written, built, and deployed swiftly, showcasing DevOps in full effect – automating build, delivery, and deployment processes. As the transition to a pipeline-driven development occurs, security becomes a critical concern, leading us to the world of DevSecOps.
DevSecOps vs DevOps: What’s the Difference?
DevOps improved software delivery by breaking down the wall between development and operations teams. DevSecOps takes that one step further by dissolving the wall between engineering and security. Here is how they compare:
| Area | DevOps | DevSecOps |
|---|---|---|
| Security timing | Post-build security review | Security at every pipeline stage |
| Responsibility | Separate security team | Shared across Dev, Sec & Ops |
| Vulnerability detection | Late-stage (often post-release) | Early-stage (pre-commit / CI) |
| Security testing | Manual penetration tests | Automated SAST, DAST, SCA in pipeline |
| Compliance | Periodic audits | Continuous compliance-as-code |
| Remediation cost | High (post-release fixes) | Low (caught during development) |
| Speed impact | Security as a bottleneck | Security automated into the flow |
How DevSecOps Works in a CI/CD Pipeline
DevSecOps maps specific security controls to each stage of your CI/CD pipeline. Here is what a mature implementation looks like in practice:
- Pre-commit: Developer’s IDE runs a secrets scanner (e.g., GitGuardian or TruffleHog) to catch hardcoded API keys, tokens, and passwords before they ever reach the Git repository.
- Commit / PR: Static Application Security Testing (SAST) runs on the pull request — Semgrep or SonarQube scans code for injection flaws, insecure deserialization, and OWASP Top 10 issues. The PR cannot merge if critical findings are open.
- Build: Software Composition Analysis (SCA) checks all third-party dependencies and open-source libraries against known CVE databases. A container image is built and immediately scanned with Trivy or Aqua for OS and package vulnerabilities.
- Infrastructure scan: If Terraform, Helm, or CloudFormation templates are changed, IaC scanning tools (Checkov, tfsec) validate them against CIS Benchmarks and OWASP IaC security guidelines before any infrastructure is provisioned.
- Deploy to staging: Dynamic Application Security Testing (DAST) runs against the deployed application — OWASP ZAP probes live endpoints for injection, authentication bypass, and exposed admin interfaces.
- Production deployment: Policy-as-Code gates (OPA/Gatekeeper or Kyverno) validate that deployments meet your security standards. Images must be signed; privileged containers are blocked.
- Runtime: Falco monitors kernel-level system calls inside containers, alerting on unexpected privilege escalations, reverse shell activity, or abnormal outbound connections — 24/7, in real time.
Gart field example: During a Kubernetes migration for a FinTech client, we integrated Trivy image scanning into GitLab CI as a required pipeline gate. Within the first sprint, we blocked 14 critical vulnerabilities from reaching production — including an outdated base image with a known remote code execution CVE. The fix cost 20 minutes of developer time. The equivalent post-release patch would have required a maintenance window, customer notification, and potential regulatory disclosure.
Shift-Left Security: Why Catching Bugs Earlier Changes Everything
“Shift left” means moving security testing earlier in the development timeline — toward the left side of the pipeline diagram. The business case is compelling: according to research cited by the NIST Secure Software Development Framework (SSDF), a vulnerability fixed during design costs roughly $80 to address. The same vulnerability found post-release can cost $7,600 — a 95× difference.
Shift-left security is not just about tooling. It requires that developers understand secure coding practices — OWASP guidelines, input validation, least-privilege API design — so security becomes a first-class concern during implementation, not a checklist item at release.
DevSecOps Tools: A Practical Comparison
Choosing the right tools for each pipeline stage is one of the most common stumbling blocks during DevSecOps adoption. Here is a pragmatic overview of the categories and leading tools our team has used in production environments:
| Category | Tools | What it detects | When it runs |
|---|---|---|---|
| Secrets Scanning | GitGuardian, TruffleHog, Gitleaks | API keys, tokens, passwords in code | Pre-commit & CI |
| SAST | Semgrep, SonarQube, Checkmarx | Code-level vulnerabilities (injection, XSS, insecure logic) | Pull request / CI |
| SCA (dependency) | Snyk, OWASP Dependency-Check, Trivy | Vulnerable open-source libraries and CVEs | Build stage |
| Container Security | Trivy, Aqua Security, Grype | OS packages, app packages, misconfigurations in images | Build & deploy |
| IaC Scanning | Checkov, tfsec, KICS | Terraform / Helm / CloudFormation misconfigurations | Pre-deploy |
| DAST | OWASP ZAP, Burp Suite (Enterprise) | Live API and web app vulnerabilities | Staging / pre-prod |
| Runtime Security | Falco, Aqua Runtime, Sysdig | Anomalous container behavior, privilege escalation | Production |
| Policy-as-Code | OPA/Gatekeeper, Kyverno | Policy violations at Kubernetes admission | Deploy gate |
You do not need every tool simultaneously. A practical starting point is: secrets scanning + SAST + container image scanning. That combination alone, integrated into your pull request workflow, eliminates the most common high-severity findings before they reach staging.
DevSecOps for Kubernetes: Securing Container Workloads
Kubernetes amplifies both the power and the attack surface of modern applications. A misconfigured cluster can expose every workload running on it to lateral movement — meaning a single compromised pod can become the foothold for a full environment takeover.
The CNCF and NSA/CISA Kubernetes Hardening Guide outlines the essential controls. In our client implementations, we prioritize:
- Image scanning in CI/CD — block images with critical CVEs before they can be deployed. We set severity thresholds (e.g., CRITICAL = build fails; HIGH = warning + ticket created) to avoid alert fatigue.
- RBAC at namespace level — eliminate
cluster-adminbindings for non-platform roles. Every application team gets scoped permissions for their namespace only. - Network Policies — default deny all ingress and egress. Whitelist only the traffic paths your application explicitly requires. This prevents lateral movement between workloads.
- Pod Security Standards — enforce the Restricted profile in production: no privilege escalation, no hostPath mounts, no host network access.
- Secrets management — never use Kubernetes Secrets alone for sensitive values; integrate HashiCorp Vault or AWS Secrets Manager via the External Secrets Operator. Secrets in etcd must be encrypted at rest.
- Runtime detection with Falco — monitor syscalls at the kernel level. Alert on shell execution inside containers, unexpected outbound connections, or writes to sensitive paths like
/etc/passwd.
Gart field example:
For a SaaS client running 40+ microservices on Kubernetes, we introduced Kyverno policies that blocked privileged containers and enforced image signing via Sigstore/Cosign. In the first month, 6 deployments were automatically rejected that would have introduced privilege escalation paths. Zero manual security reviews were required — the policy ran automatically on every deployment.
Business Benefits of DevSecOps
Security is often positioned as a cost centre. DevSecOps reframes it as an accelerator. Here is what organizations consistently gain after a mature DevSecOps implementation:
| Benefit | What it means in practice |
|---|---|
| Faster remediation | Bugs caught during development take minutes to fix. The same bug caught post-release can take weeks and cost tens of thousands in patches, hotfixes, and customer communication. |
| Reduced breach risk | Automated scanning across every commit dramatically narrows the window during which a vulnerability exists in your codebase undetected. |
| Compliance confidence | Continuous policy enforcement makes SOC 2, ISO 27001, PCI DSS, and HIPAA readiness an ongoing state rather than a last-minute scramble before an audit. |
| Investor & enterprise readiness | Enterprise buyers and security-conscious investors increasingly require evidence of secure development practices as part of vendor due diligence. |
| Developer confidence | When security feedback is automated and immediate, developers build security intuition over time — reducing repeat patterns of insecure code. |
| Improved Time-to-Market | Paradoxically, security automation speeds up delivery by removing the “big security review” bottleneck before each release. |
DevSecOps Adoption Challenges (and How to Solve Them)
After working with dozens of engineering teams on DevSecOps transitions, the failure patterns are remarkably consistent. Here are the most common — and how to avoid them:
1. Alert fatigue from misconfigured scanners
A SAST tool configured without tuning will flood developers with hundreds of false positives per day. Within a week, engineers start ignoring the scanner entirely. The fix: start with a narrow set of high-confidence rules, tune aggressively for your codebase in the first sprint, and add rules incrementally.
2. Security as a developer bottleneck
When security gates block PRs without clear remediation guidance, developers perceive security as an obstacle rather than a shared goal. The fix: every scanner finding must include a remediation suggestion, a severity classification, and an escalation path for false positives.
3. Developers lacking security context
Most developers are not trained in application security. They may not understand why a finding is dangerous, leading to superficial fixes that address the symptom but not the root cause. The fix: short, role-specific security training sessions, and in-line documentation within your pipeline that explains why a rule exists, not just what it flagged.
4. Underestimating the toolchain integration effort
Modern CI/CD pipelines already have 10–20 integrated tools. Adding 5 security tools without a deliberate integration strategy creates maintenance overhead that kills adoption. The fix: prioritize tools with native CI/CD platform integrations (GitHub Actions, GitLab CI, Jenkins), and adopt a platform approach — a single policy engine rather than per-tool configurations.
5. Treating DevSecOps as a one-time project
Security is not a destination. New CVEs are published daily, new attack techniques emerge quarterly, and your codebase evolves constantly. The fix: treat DevSecOps as an ongoing program with quarterly security posture reviews, tool version updates, and pipeline audits — not a project with a completion date.
DevSecOps Best Practices
Based on our implementation experience across cloud-native environments, these are the practices that consistently deliver the highest return:
- Start with secrets scanning — the fastest, lowest-friction win. Secrets in Git history cause some of the highest-severity breaches and are trivially preventable.
- Make security gates informative, not just blocking — every failed gate should explain the issue and link to remediation guidance.
- Codify policies as Infrastructure as Code — use OPA, Kyverno, or Terraform policies so security rules go through the same review process as application code. See our guide on Policy-as-Code.
- Implement RBAC across your entire pipeline — who can trigger a production deployment? Who can read secrets? Follow our detailed guide on RBAC in CI/CD pipelines.
- Run runtime monitoring in production — static analysis finds known issues; runtime monitoring catches the unknown. Falco in a Kubernetes cluster is a non-negotiable for any production workload handling sensitive data.
- Generate and maintain an SBOM — a Software Bill of Materials gives you an inventory of every library in your application. When a new CVE is published (e.g., a Log4Shell-level event), you can immediately determine whether you are affected.
- Track security metrics — Mean Time to Remediate (MTTR) for critical findings, number of vulnerabilities introduced per sprint vs. resolved, and open critical CVE age are the KPIs that tell you whether your program is improving.
DevSecOps Practices in the Context of Modern Challenges
The application security landscape has expanded significantly. Beyond the classic SAST/DAST pair, a mature DevSecOps program addresses the following practice areas:
- SCA (Software Composition Analysis) — continuously monitors third-party and open-source dependencies for newly disclosed CVEs, license violations, and dependency confusion attacks.
- Container Security — scans images at build time and monitors container runtime behavior. Given that most modern applications run in containers, this is now a core (not optional) capability.
- IaC Security — ensures that Terraform, Helm, and CloudFormation templates follow security best practices before infrastructure is ever provisioned. Misconfigured IaC is responsible for the majority of cloud data breaches.
- API Security Testing — APIs are now the primary attack vector for web applications. Dedicated API security testing (beyond traditional DAST) is required to catch authentication bypass, excessive data exposure, and broken object-level authorization (BOLA) issues.
- MAST (Mobile Application Security Testing) — for teams with mobile surfaces: iOS and Android applications require platform-specific security assessments beyond web-focused tooling.
- SBOM (Software Bill of Materials) — required by US Executive Order 14028 for federal software suppliers and increasingly expected by enterprise buyers as part of vendor security questionnaires.
- Chaos Engineering — proactively tests system resilience by simulating failures. From a security perspective, chaos engineering validates that your incident detection and response capabilities work under real-world conditions.
The Path of Application Security Practices Transformation
Application Security has gained widespread acceptance as a mainstream concern in the cybersecurity landscape. The evolving market demands more innovative and efficient solutions, especially with the rise in API attacks and software supply chain vulnerabilities. As technology advances and market requirements change, new tools and modifications in the cybersecurity toolkit are emerging. To understand the current trends and the level of development in cybersecurity tools, we can refer to the Gartner Hype Cycle for Application Security, 2023 report.
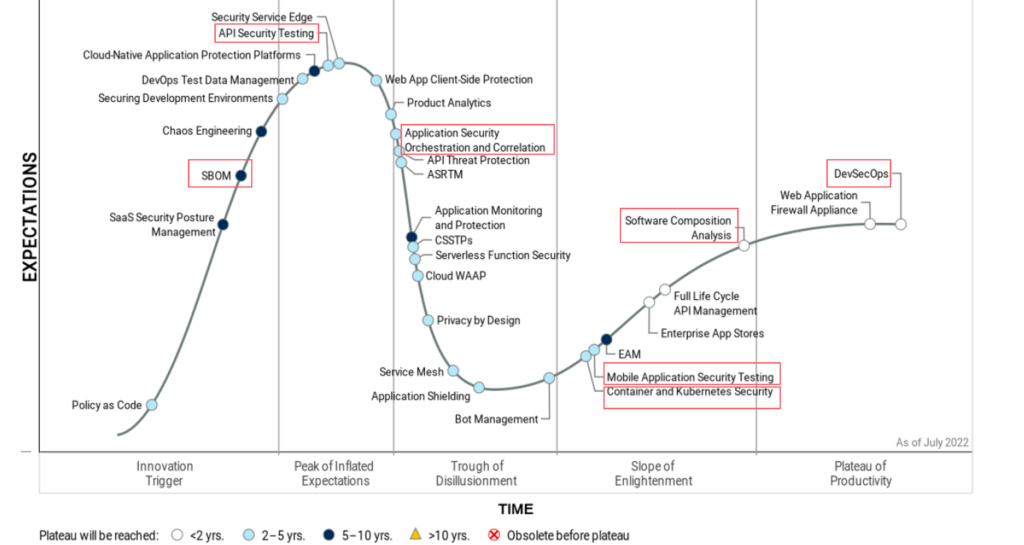
The cycle comprises five distinct phases:
- Innovation Trigger: This phase marks the introduction of technologies in the cybersecurity domain, just starting their journey.
- Peak of Inflated Expectations: Technologies in this phase demonstrate some successful use cases but also experience setbacks. Companies strive to tailor these practices to their specific needs, but widespread adoption is yet to be achieved.
- Trough of Disillusionment: Interest in technologies of this phase begins to decline as their implementation doesn’t always yield desired results.
- Slope of Enlightenment: At this stage, technologies have a solid track record of being beneficial to companies, leading to new generations of tools and an increase in demand.
- Plateau of Productivity: In this final stage, technologies have well-defined tasks and applications, gaining momentum as mainstream cybersecurity solutions.
Now, let’s explore DevSecOps and delve into the most impactful and compelling secure development practices, considering their implications on businesses, technological complexities, and geopolitical implications.
DevSecOps in the Current Landscape
As per Gartner’s assessment, DevSecOps has reached the “Plateau of Productivity” phase. It has now become a mature mainstream approach, adopted by over 50% of the target audience. This methodology allows security teams to stay in sync with development and operations units during the creation of modern applications. The model ensures seamless integration of security tools into DevOps and automates all processes involved in developing secure software. Consequently, DevSecOps aids businesses in elevating product security, aligning applications and processes with industrial and regulatory standards, reducing vulnerability remediation costs, improving Time-to-Market metrics, and enhancing developers’ expertise.
While striving to establish an effective secure development process, companies face several challenges:
- Improper implementation of AppSec practices and poorly structured security processes can create a contradiction with DevOps, leading developers to perceive security tools as hindrances to their work.
- The wide variety of tools used in modern CI/CD pipelines complicates the smooth integration of DevSecOps.
- Many developers lack expertise in security, resulting in a lack of understanding of potential risks in their code. They may be hesitant to leave the CI/CD pipeline for security testing or scan results and may encounter difficulties with false positives from SAST and DAST tools.
- Open-source security solutions may contain malicious code, and there is a risk that such tools may become unavailable for Russian users at any moment.
Despite these challenges, implementing DevSecOps can greatly benefit organizations by enhancing their security practices and ensuring the safety and compliance of their applications and processes.
Practices of DevSecOps in the Context of Modern Challenges
- SCA (Software Composition Analysis): SCA involves analyzing the components and dependencies in software applications to identify and address vulnerabilities in third-party libraries or open-source code. With the increasing use of external libraries, SCA helps ensure that potential security risks from these components are mitigated.
- MAST (Mobile Application Security Testing): MAST focuses on evaluating the security of mobile applications across various platforms. It involves conducting comprehensive security assessments to identify weaknesses and vulnerabilities specific to mobile app development.
- Container Security: Containerization has become prevalent in modern application deployment. Container Security practices involve scanning container images for potential security flaws and continuously monitoring container runtime environments to prevent unauthorized access and data breaches.
- ASOC (Application Security Orchestration & Correlation): ASOC is about streamlining and automating security practices throughout the software development lifecycle. It includes integrating various security tools, orchestrating their actions, and correlating their findings to improve the efficiency and effectiveness of security assessments.
- API Security Testing: With the increasing use of APIs in modern applications, API security testing is crucial. It involves evaluating the security of APIs, ensuring they are protected against potential attacks, and safeguarding sensitive data exchanged through these interfaces.
- Securing Development Environments: Securing development environments involves implementing robust security measures to protect the tools, platforms, and repositories used by developers during the software development process. This ensures that the codebase remains secure from the very beginning.
- Chaos Engineering: Chaos Engineering is a proactive approach to testing system resilience. It involves simulating real-world scenarios and failures to identify potential weaknesses in applications and infrastructure and enhance their overall resilience.
- SBOM (Software Bill of Materials): SBOM is a detailed inventory of all software components used in an application. It helps organizations track and manage their software supply chain, facilitating vulnerability management and risk assessment.
- Policy-as-a-Code: Policy-as-a-Code involves codifying security policies and compliance requirements into the software development process. By integrating policy checks into the CI/CD pipeline, organizations can ensure that applications adhere to security standards and regulatory guidelines.
- RBAC stands for Role-Based Access Control, a method of restricting system access based on user roles. In CI/CD pipelines, RBAC ensures that only authorized individuals have access to specific stages of the pipeline, enhancing security and control.
Implementing these DevSecOps practices can significantly enhance application security, address modern challenges, and foster a proactive approach to safeguarding software throughout its lifecycle.
Triggers for Implementation and Recommendations
Knowing when to prioritize the security of your products and embark on serious DevSecOps implementation can be a crucial decision. It depends on your industry, market position, and the demands of your audience. Compliance with regulators and the assessment of potential risks act as significant drivers for security. DevSecOps has become a mature mainstream technology embraced by over 50% of the target audience. It enables security teams to align with development and operations units, fostering the creation of modern applications. Deep integration of security tools into DevOps and automation of secure software development processes help businesses elevate product security levels, comply with industry standards, reduce vulnerability fixing costs, improve Time-to-Market metrics, and enhance developer expertise.
Several triggers can prompt the adoption of DevSecOps practices:
- A development team comprising more than 50 members.
- The implementation of process automation in development, such as CI/CD and DevOps.
- An emphasis on microservices architecture.
- The need for post-implementation improvements in application security practices.
For companies with large development teams and multiple products, introducing DevSecOps should be a gradual process, involving the team in decision-making. Though initial challenges may arise, once the process functions efficiently, developers, other team members, investors, and stakeholders will recognize the benefits of these changes.
Before proceeding, it’s wise to seek guidance from successful implementations, consult with experts, and evaluate the advantages gained by companies that have already adopted DevSecOps, making informed decisions backed by data.
When Should Your Organization Start With DevSecOps?
DevSecOps scales from startup to enterprise, but the triggers for serious implementation are predictable. You should prioritize it when:
- Your development team has grown beyond 50 engineers (coordination of manual security reviews becomes impossible)
- You have adopted CI/CD and automated deployments (the pipeline is the right place to embed security controls)
- Your architecture is moving toward microservices or Kubernetes (the attack surface expands faster than manual reviews can cover)
- You serve regulated industries — FinTech, Healthcare, or any segment requiring SOC 2, PCI DSS, or HIPAA compliance
- Enterprise clients or investors are conducting security due diligence as part of onboarding
For teams with fewer than 50 developers focused primarily on business functionality, a pragmatic starting point is: automated secrets scanning + dependency scanning + a quarterly manual penetration test. As the team and codebase grow, the full DevSecOps pipeline becomes the natural evolution — not a separate initiative.
Our engineering team has designed and implemented DevSecOps programs for FinTech, Healthcare, and cloud-native SaaS companies — integrating automated security into pipelines without slowing down delivery.







