Downtime costs more than money — it erodes trust. At Gart Solutions, we engineer software systems that don’t just function — they excel in reliability. Using proven DevOps and SRE practices, we ensure your digital product is fast, stable, and always ready.
When you use a software product, you expect it to work well and meet your needs. But what does it mean for software to be “high quality”? According to the ISO 9126 standard, the quality of a software product is defined by all its features and characteristics that allow it to meet the needs of its users. One key aspect of quality is how reliable the software is.
What is software reliability?
Reliability is important not just for users but also for planning and managing the software development process. By predicting reliability, developers can estimate how much more work is needed before the software reaches the desired level of reliability.
In simple terms, software reliability is the chance that the software will run without any problems for a specific time in a specific environment.
This definition, provided by Carnegie Mellon University, highlights two key aspects: the environment in which the software operates and the time frame during which it must remain functional. Unlike hardware reliability, which often depends on the perfection of manufacturing processes, software reliability is rooted in design perfection. In other words, software reliability is achieved through careful planning, design, and testing rather than through physical durability.
At Gart Solutions, we understand that software reliability isn’t just a technical goal—it’s a critical component of business success. Our approach to building reliable digital solutions leverages the best practices of DevOps and Site Reliability Engineering (SRE), ensuring that your software not only meets but exceeds industry standards for reliability.
The Importance of Reliability in Different Contexts
Software reliability is a crucial aspect of software quality, impacting both end-users and the development process itself. Reliable software maintains its performance under stated conditions, providing a consistent user experience and minimizing downtime.
Software reliability isn’t just about preventing crashes; it’s about ensuring consistent, predictable performance that builds trust with your users.
The significance of software reliability varies depending on the context in which the software operates. In life-critical systems, such as those used in aviation or healthcare, software failures can lead to catastrophic outcomes, including loss of life. A prime example is the Boeing 737 Max software defect, which resulted in two fatal crashes due to unreliable software behavior. In contrast, business-critical systems may allow for more subjective interpretations of reliability. For example, a minor software glitch in an e-commerce platform may frustrate customers but is unlikely to result in severe consequences.
In software engineering, one of the most significant challenges lies in the inherent fragility of digital systems. Unlike traditional engineering disciplines, where small mistakes often go unnoticed or cause minor issues, software errors can lead to catastrophic failures. A single oversight, such as a null pointer dereference, can crash an entire system, making the stakes in software development incredibly high. For instance, Expedia saw a $12 million revenue increase simply by removing one confusing input field from their payment form.
Regardless of the context, it is crucial for software engineers and SREs to understand that reliability is not just about the absence of bugs but also about how the software behaves under different conditions. A reliable system is one that consistently meets its performance expectations, even in the face of varying workloads or environmental changes.
Achieving Software Reliability Through Design
Achieving high levels of software reliability begins with the design phase. Design perfection is the foundation upon which reliable software is built. This involves not only the creation of robust algorithms and data structures but also careful consideration of how the software will interact with other systems and environments.
For example, a software application that runs smoothly on a local server may experience reliability issues when deployed in a cloud environment due to differences in infrastructure. Therefore, understanding the target environment and designing the software to perform well under those conditions is crucial for achieving reliability.
Another important consideration is the trade-off between availability and consistency. In highly available systems, such as those used in financial transactions, ensuring that the system is always online may come at the cost of data consistency. For instance, to ensure high availability, a system might cache data locally to reduce dependency on external systems, but this can lead to data inconsistency if the cache is not regularly updated. Additionally, as availability targets increase (e.g., moving from 99.9% to 99.999%), the complexity of the system architecture also increases exponentially.
SREs must carefully balance these trade-offs to ensure that the system remains both reliable and consistent.
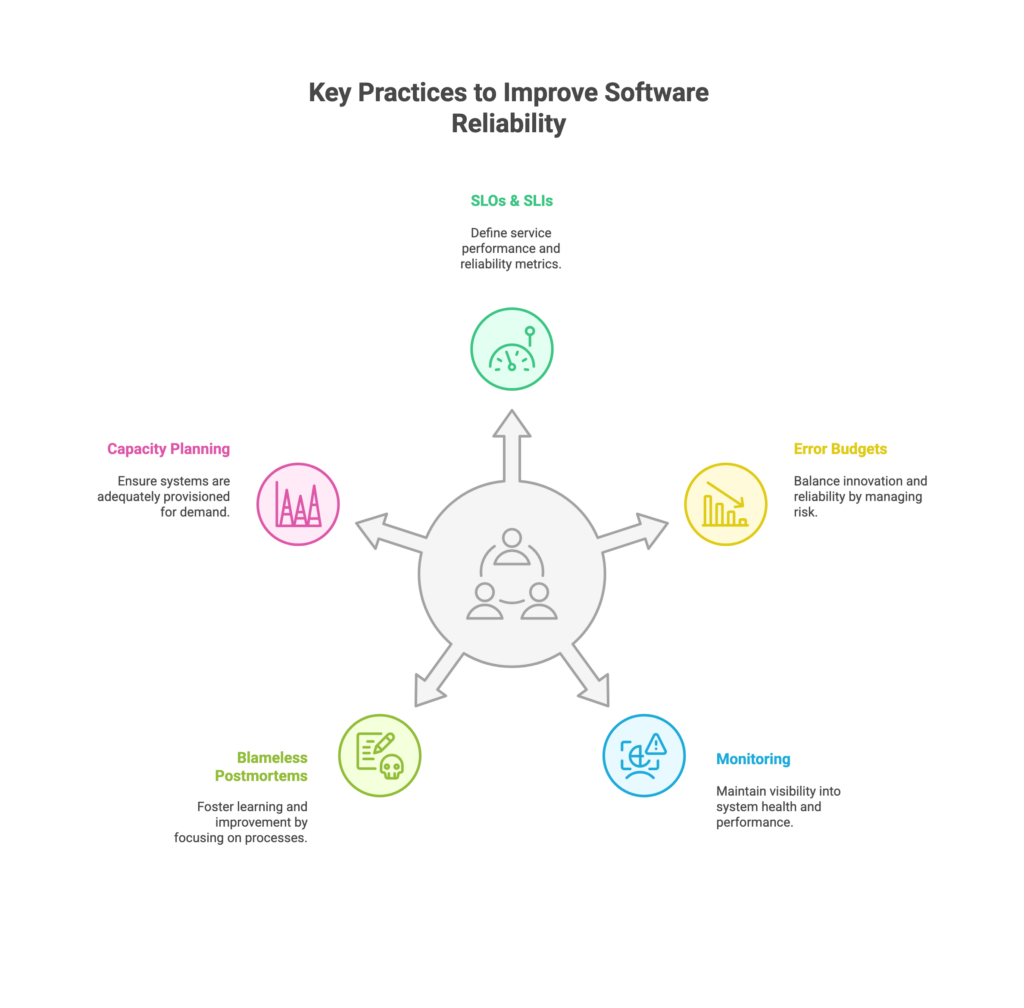
How SRE Enhances Reliability – Key Practices to Improve Software Reliability
SREs play a crucial role in maintaining and improving software reliability by implementing practices such as automation, monitoring, and incident response.
Key Practices are:
Measuring Software Reliability: SLOs and SLIs
To quantify and manage software reliability, organizations often use Service Level Objectives (SLOs) and Service Level Indicators (SLIs). SLOs are specific targets for system performance, such as the time it takes to acknowledge an order on an e-commerce platform. SLIs, on the other hand, are metrics that measure how well the system is performing against these targets.
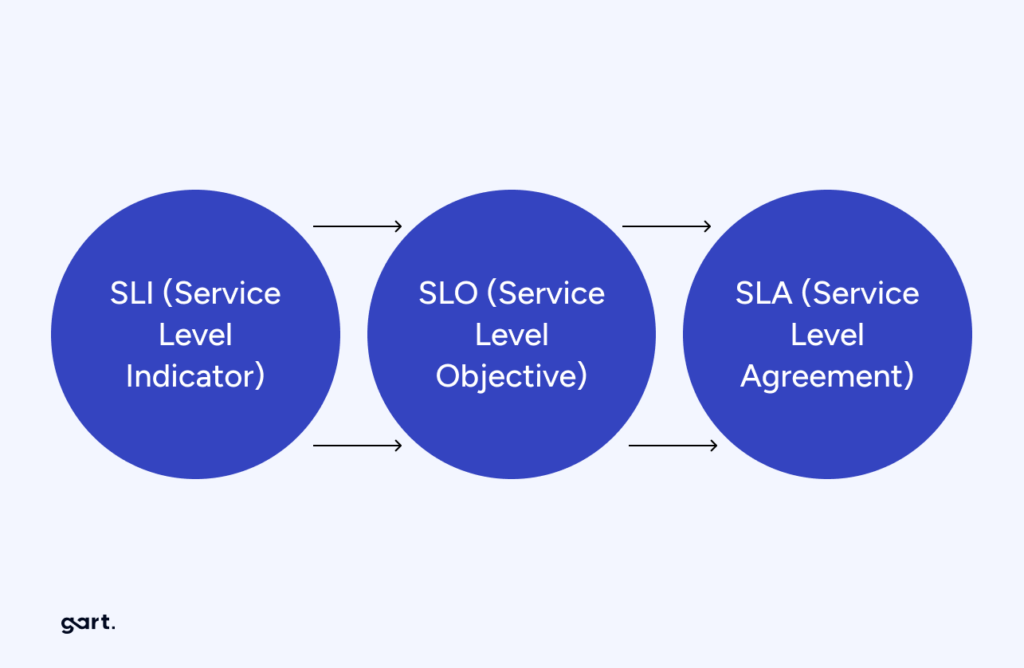
For example, an SLO might specify that 99.9% of order acknowledgments must occur within two seconds. The SLI would then measure the actual performance of the system to determine if this target is being met. If the SLI indicates that the system is failing to meet the SLO, this serves as an early warning sign that the system’s reliability is at risk, prompting further investigation and remediation.
SLOs and SLIs provide a customer-centric view of reliability, helping organizations ensure that their systems meet user expectations. They also create a feedback loop that allows teams to continuously improve their systems by making data-driven decisions based on real-world performance.
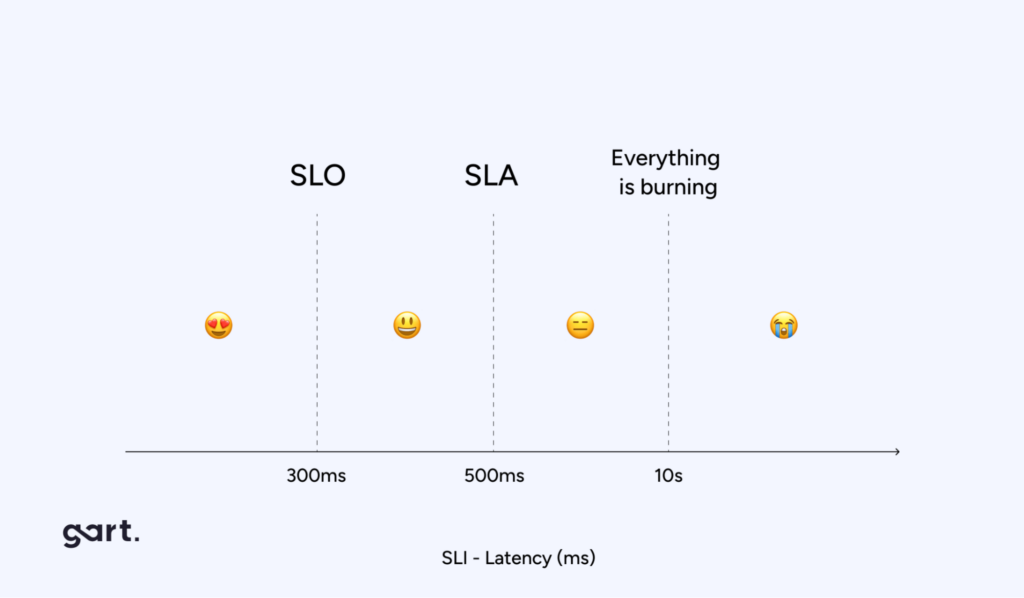
SLOs are a key component of SRE. They define the desired reliability level of a service, usually expressed in terms of availability, latency, or error rates. SLOs provide a clear target for teams to aim for and help in prioritizing efforts to improve reliability.
Error budgets
SRE introduces the concept of error budgets, which define the acceptable amount of unreliability for a given period (balance low quality releases with operational circumstances). This allows teams to balance innovation and reliability.
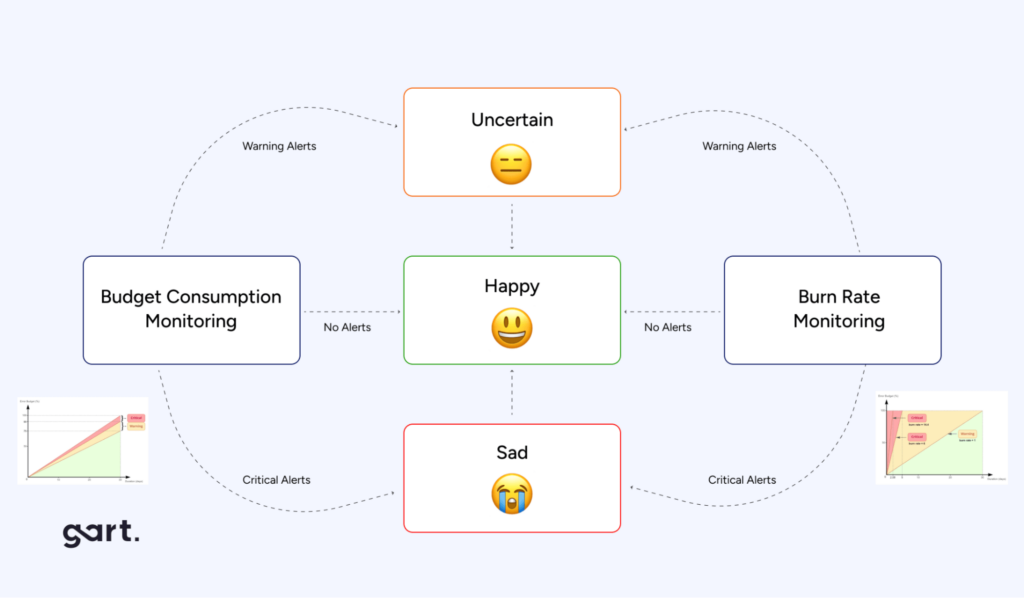
If the error budget is exceeded, development slows down, and efforts are refocused on improving stability.

Postmortems
After an incident occurs, SRE teams conduct thorough postmortems to analyze what went wrong and how it can be prevented in the future. These postmortems are blameless, focusing on learning from mistakes rather than assigning fault. The insights gained are used to improve processes and systems, reducing the likelihood of similar issues in the future.
Capacity Planning and Scaling
SRE involves proactive capacity planning to ensure that systems can handle expected and unexpected loads. This includes forecasting resource needs, monitoring system performance, and scaling infrastructure as needed to prevent bottlenecks and failures. Effective capacity planning ensures that your digital solution remains reliable even as demand grows.
Proactive Monitoring and Incident Response
SRE teams focus on proactive monitoring to detect and address issues before they escalate. They also develop well-defined incident response plans to ensure quick recovery when things go wrong, minimizing downtime and impact on users.
Business Impact of Reliable Software
Software reliability isn’t just a technical metric, it’s a critical business enabler. When your systems are consistently available and perform as expected, you gain user trust, reduce operational stress, and protect your bottom line. On the flip side, unreliable software can lead to major financial and reputational damage.
Consider Expedia: the company famously increased its annual revenue by $12 million simply by removing a confusing field from its payment form. That small improvement in reliability and user experience translated directly into higher conversions and profits. On the other end of the spectrum, Boeing’s 737 Max tragedy is a stark reminder of how critical software reliability can be. A software malfunction contributed to two fatal crashes, grounding fleets and costing the company billions, alongside immeasurable damage to its reputation.
The stakes are high. According to Gartner, the average cost of IT downtime is $5,600 per minute —that’s more than $300,000 per hour. For customer-facing platforms, each moment of unavailability can result in lost sales, churn, and negative reviews. For internal systems, downtime stalls productivity and decision-making.
This is why reliability is no longer optional. It’s a strategic necessity.
How SRE & DevOps Work Together
While DevOps and Site Reliability Engineering (SRE) share similar goals, they take distinct approaches to improving software quality and operational excellence. Together, they form a powerful combination for building and maintaining highly reliable systems.
DevOps focuses on unifying development and operations teams to enable continuous integration and delivery (CI/CD), faster releases, and automation throughout the software lifecycle. It’s about breaking silos and enabling speed without sacrificing control.
SRE, introduced by Google, brings a more metrics-driven, engineering-centric approach to reliability. It emphasizes SLOs (Service Level Objectives), error budgets, monitoring, and incident response to ensure systems meet reliability targets without slowing innovation. SRE uses engineering principles to solve operations challenges, making it a natural evolution of DevOps.
Here’s how they compare in key areas:
| Aspect | DevOps | Site Reliability Engineering (SRE) |
|---|---|---|
| Primary Focus | Automating delivery & collaboration | Ensuring system reliability and availability |
| Key Practices | CI/CD, automation, infrastructure as code | SLOs, SLIs, error budgets, monitoring, incident response |
| Goal | Fast, frequent, reliable deployments | Maintain reliability while allowing innovation |
| Approach | Cultural + tooling | Engineering + metrics |
| Metrics | Deployment frequency, lead time | Latency, availability, error rate |
Together, DevOps enables speed and agility, while SRE ensures that velocity doesn’t come at the cost of stability. When implemented side by side, they allow you to build software that’s not only fast to market but built to last.
Conclusion
Software reliability is a complex but essential aspect of modern software systems. It requires a deep understanding of the software’s design, the environment in which it operates, and the expectations of its users. By focusing on design perfection, setting clear reliability objectives, and leveraging the practices of Site Reliability Engineering, organizations can build and maintain systems that are not only functional but also reliable.
Ready to enhance your system’s reliability?
Partner with Gart to design, build, and maintain a robust digital solution that meets your business needs. Our experts are here to guide you through every step of the process, ensuring your software operates flawlessly and efficiently.
Learn more from our cases.
Get a Free Software Reliability Consultation
Whether you’re launching or scaling, our SRE experts will build a plan to help your product stay fast, reliable, and secure.
See how we can help to overcome your challenges