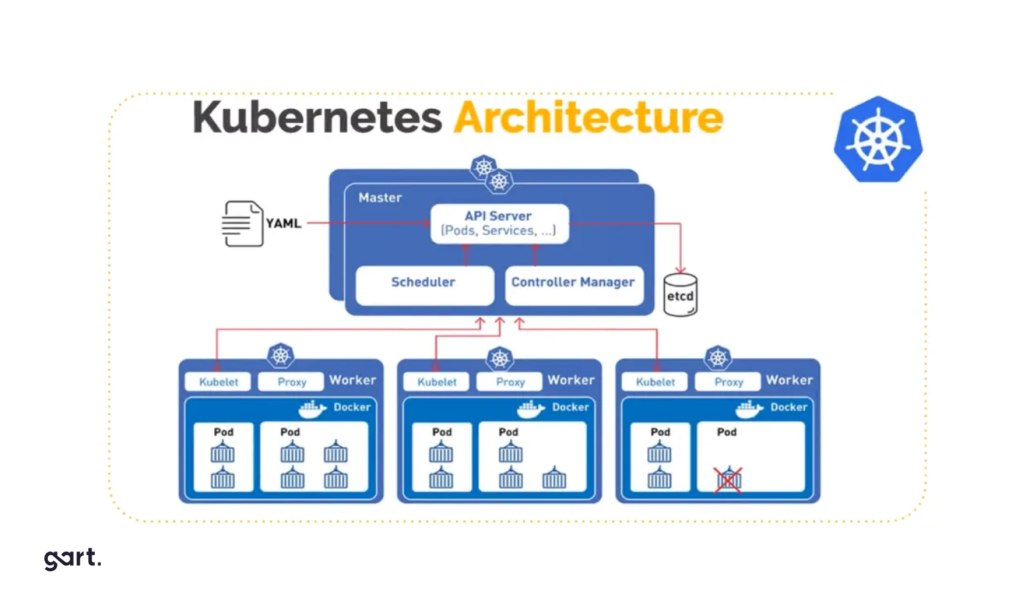
Kubernetes trends in 2026 will be driven by its increasing maturity and complex use cases like AI/ML. Almost half of organizations surveyed expect over 50% growth in Kubernetes clusters. The skills shortage will lead to more outsourcing and a shift toward platform engineering replacing DevOps. Centralized management platforms will be crucial for consistency across decentralized environments. With growing security threats, cloud-native and Kubernetes security will receive great attention, favoring platforms with built-in security tools enabled by default. Cost optimization through FinOps principles and tools like Kubecost integrating into Kubernetes platforms is also predicted. Emerging areas include widespread SBOM adoption for software supply chain security.
[lwptoc]
Kubernetes has become a cornerstone of the cloud ecosystem, and its importance continues to grow with each passing year. The community's efforts are paying off – now it's not just tech giants with huge operations teams that can take advantage, but also relatively smaller companies.
This has partly become possible thanks to the rise of managed solutions and platforms like OpenShift and Deckhouse, which combine all the necessary tools for deploying, managing, and securing a cluster.
Unfortunately, the Kubernetes ecosystem still suffers from a number of issues (just think of the security threats). So what can we expect this year? What will it be like for the orchestrator?
Many industry experts believe 2026 will be another turning point. Kubernetes' maturity and ability to handle increasingly complex use cases is perhaps most obvious in the AI and machine learning space.
Almost half (48%) of the specialists surveyed by VMware predict the number of Kubernetes clusters will grow by over 50% this year; another 28% expect a significant increase (20-50%).
The shortage of skilled professionals will lead organizations to prefer simple, low-maintenance technologies. Many will start outsourcing to companies like GART Solutions.
Kubernetes and Containerization Trends
Platform Engineering
Platform engineering will replace DevOps. The lack of specialists doesn't allow DevOps practices to fully realize their potential. With this in mind, many organizations may revisit the DevOps model this year and turn to platform engineering as an alternative. The rapid development of cloud-native apps will lead to this new approach gradually replacing DevOps in many organizations.
Centralized Management Platform
With increasing decentralization, centralized management will become crucial. A centralized management platform will ensure consistency and reduce the time and effort spent managing distributed locations, devices and data.
Cloud-Native and Kubernetes Security
Great attention will be paid to the security of cloud-native and Kubernetes projects. Given that Kubernetes clusters aren't secure by default, and the rise in threats and sophisticated attacks, companies in 2026 will increasingly need to re-evaluate their security approaches. Kubernetes platforms with built-in (and enabled by default) security tools will be popular.
These security threats can occur throughout the application lifecycle:
Nearly 45% of vulnerabilities occur during these stages, alongside runtime (49%).
A troubling 45% of respondents admitted to misconfiguration incidents, highlighting the need for strong security practices.
Another 42% discovered major vulnerabilities, indicating a lack of thorough security testing.
FinOps and Kubernetes
The issue of controlling cloud and Kubernetes costs will be addressed through automation and centralized management. FinOps cost control tools like Kubecost will increasingly integrate into Kubernetes platforms, enabling real-time cost monitoring and analysis in distributed environments.
Roman Burdiuzha, Co-Founder & CTO at Gart Solutions, shared his predictions for 2026. He believes this could be a key year for FinOps, as cloud spending has been growing rapidly in recent years and is gradually becoming a major expense for companies, second only to salaries.
FinOps practices will help optimize cloud spending. Additionally, cost management and FinOps are expected to become a default part of observability solutions.
Software Bill of Materials
Another major innovation, according to Roman Burdiuzha, will be the widespread adoption of SBOM (Software Bill of Materials) standards for software delivery. These include detailed information on the relationships between various components used in software, including libraries and modules from open and closed source, free and paid, publicly and privately available.
Here are a few more predictions
GitOps will reach maturity and "enter the plateau of productivity", aided in part by the Argo and Flux projects reaching "graduated" status. Interestingly, these are among the fastest developing projects in the CNCF ecosystem.
OpenTelemetry is another promising area expected to make great strides in 2026. Recent open source velocity data shows OpenTelemetry ranks second only to Kubernetes, incredibly impressive for such a young project. It's expected not just leading tech companies but many traditional enterprises will leverage this technology's benefits.
WASM is projected to "become the dominant form of compute" in the near future. This will be driven by the technology's use cases beyond browsers (e.g. edge compute, server workloads), including in the cloud ecosystem.
Kubernetes will experience a "Linux-style maturity moment". There was a time when Linux was the domain of geeks only. But over time, the OS made its way to smartphones, cars, real-time systems and other devices. Kubernetes is undergoing a similar evolution, gradually migrating to new environment types it wasn't originally intended for (e.g. embedded devices). New use cases drive innovation in Kubernetes and its ecosystem, just like with Linux.
Read more: Will Kubernetes Still Be Popular in 5-10 Years?
Conclusion
Looking further ahead, Gartner estimates that by 2026, over 90% of global organizations will run containerized applications in production, up from less than 40% in 2020. And by 2026, over 95% of new workloads will be deployed on cloud-native platforms, a significant increase from 30% in 2021.

Kubernetes has become the de facto standard for container orchestration, revolutionizing the way applications are deployed and managed. However, as with any technology, the question arises: will it remain relevant in the years to come, or will new, more advanced solutions emerge to take its place? In this article, we'll explore the potential future of Kubernetes and the factors that could shape its trajectory.
#1: Kubernetes is Overly Complex and a New Layer of Abstraction Will Emerge
While Kubernetes has successfully solved many challenges in the IT industry, its current form is arguably overcomplicated, attempting to address every modern IT problem. As a result, it is logical to expect the emergence of a new layer of abstraction that could simplify the application of this technology for ordinary users.
Tired of Complex Deployments? Streamline Your Apps with Gart's Kubernetes Solutions. Get a Free Consultation!s
#2: Kubernetes Solved an Industry Problem, but More Efficient Alternatives May Arise
Kubernetes provided a clear and convenient way to package, run, and orchestrate applications, addressing a significant industry problem. Currently, there are no worthy alternative solutions. However, it is possible that in the next 5-10 years, new solutions may emerge to address the same challenges as Kubernetes, but in a faster, more efficient, and simpler manner.
#3: Kubernetes Will Become More Complex and Customizable
As Kubernetes evolves, it is becoming increasingly complex and customizable. For each specific task, there is a set of plugins through which Kubernetes will continue to develop. In the future, competition will likely arise among different distributions and platforms based on Kubernetes.
#4: Focus Will Shift to Security and Infrastructure Management
More attention will be given to the security of clusters and applications running within them. Tools for managing infrastructure and third-party services through Kubernetes, such as Crossplane, will also evolve.
#5: Integration of ML and AI for Better Resource Management
It is likely that machine learning (ML) and artificial intelligence (AI) tools will be integrated into Kubernetes to better predict workloads, detect anomalies faster, and assist in the operation and utilization of clusters.
#6: Kubernetes Won't Go Away, but Worthy Competitors May Emerge
Kubernetes won't disappear because the problem it tries to solve won't go away either. While many large companies will continue to use Kubernetes in the next 5 years, it is possible that a worthy competitor may emerge within the next 10 years.
#7: Kubernetes Will Remain Popular and Ubiquitous
Kubernetes has proven its usefulness and is now in the "adult league." It is expected to follow a path similar to virtualization or Docker, becoming increasingly adopted by companies and transitioning from a novelty to an expected standard.
#8: Kubernetes Will Evolve, but Alternatives May Be Elusive
While Kubernetes faces challenges, particularly in terms of complexity, there are currently no clear technologies poised to replace it. Instead, Kubernetes itself is likely to evolve to address these challenges.
Unlock Scalability & Efficiency. Harness the Power of Kubernetes with Gart's Expert Services. Boost Your ROI Today!
Perspective 9: Kubernetes as the New "Linux" for Distributed Applications
Kubernetes has essentially become the new "Linux" – an operating system for distributed applications – and is therefore likely to remain popular.
Kubernetes has rapidly evolved from a tool for container orchestration to something much more foundational and far-reaching. In many ways, it is becoming the new operating system for the cloud-native era – providing a consistent platform and set of APIs for deploying, managing, and scaling modern distributed applications across hybrid cloud environments.
Just as Linux democratized operating systems in the early days of the internet, abstracting away underlying hardware complexities, Kubernetes is abstracting away the complexities of executing workloads across diverse infrastructures. It provides a declarative model for describing desired application states and handles all the underlying work of making it happen automatically.
The core value proposition of Linux was portability across different hardware architectures. Similarly, Kubernetes enables application portability across any infrastructure - public clouds, private clouds, bare metal, etc. Containerized apps packaged to run on Kubernetes can truly run anywhere Kubernetes runs.
Linux also opened the door for incredible community innovation at the application layer by standardizing core OS interfaces. Analogously, Kubernetes is enabling a similar flourishing of creativity and innovation in cloud-native applications, services, and tooling by providing standardized interfaces for cloud infrastructure.↳
As Kubernetes ubiquity grows, it is becoming the new common denominator platform that both cloud providers and enterprises are standardizing on. Much like Linux became the standard operating system underlying the internet, Kubernetes is positioning itself as the standard operating system underlying the cloud era. Its popularity and permanence seem virtually assured at this point based on how broadly and deeply it is becoming embedded into cloud computing.
Perspective 10: Kubernetes Will Become More Commonplace
Kubernetes has taught developers and operations engineers to speak the same language, but developers still find it somewhat foreign. New solutions will emerge to abstract away Kubernetes' complexity, allowing developers to focus on business tasks. However, Kubernetes itself will not disappear; it will continue to evolve and be used as a foundation for these new technologies.
Conclusion
In conclusion, while Kubernetes may face challenges and competition in the future, its core functionality and the problem it solves are unlikely to become obsolete. As new technologies emerge, Kubernetes will likely adapt and evolve, potentially becoming a foundational layer for more specialized solutions. Its staying power will depend on its ability to simplify and address emerging complexities in the ever-changing IT landscape.

Kubernetes is becoming the standard for development, while the entry barrier remains quite high. We've compiled a list of recommendations for application developers who are migrating their apps to the orchestrator. Knowing the listed points will help you avoid potential problems and not create limitations where Kubernetes has advantages. Kubernetes Migration.
Who is this text for?
It's for developers who don't have DevOps expertise in their team – no full-time specialists. They want to move to Kubernetes because the future belongs to microservices, and Kubernetes is the best solution for container orchestration and accelerating development through code delivery automation to environments. At the same time, they may have locally run something in Docker but haven't developed anything for Kubernetes yet.
Such a team can outsource Kubernetes support – hire a contractor company, an individual specialist, or, for example, use the relevant services of an IT infrastructure provider. For instance, Gart Solutions offers DevOps as a Service – a service where the company's experienced DevOps specialists will take on any infrastructure project under full or partial supervision: they'll move your applications to Kubernetes, implement DevOps practices, and accelerate your time-to-market.
Regardless, there are nuances that developers should be aware of at the architecture planning and development stage – before the project falls into the hands of DevOps specialists (and they force you to modify the code to work in the cluster). We highlight these nuances in the text.
The text will be useful for those who are writing code from scratch and planning to run it in Kubernetes, as well as for those who already have a ready application that needs to be migrated to Kubernetes. In the latter case, you can go through the list and understand where you should check if your code meets the orchestrator's requirements.
The Basics
At the start, make sure you're familiar with the "golden" standard The Twelve-Factor App. This is a public guide describing the architectural principles of modern web applications. Most likely, you're already applying some of the points. Check how well your application adheres to these development standards.
The Twelve-Factor App
Codebase: One codebase, tracked in a version control system, serves all deployments.
Dependencies: Explicitly declare and isolate dependencies.
Configuration: Store configuration in the environment - don't embed in code.
Backing Services: Treat backing services as attached resources.
Build, Release, Run: Strictly separate the build, release, and run stages.
Processes: Run the application as one or more stateless processes.
Port Binding: Expose services through port binding.
Concurrency: Scale the application by adding processes.
Disposability: Maximize reliability with fast startup and graceful shutdown.
Dev/Prod Parity: Keep development, staging, and production environments as similar as possible.
Logs: Treat logs as event streams.
Admin Processes: Run administrative tasks as one-off processes.
Now let's move on to the highlighted recommendations and nuances.
Prefer Stateless Applications
Why?
Implementing fault tolerance for stateful applications will require significantly more effort and expertise.
Normal behavior for Kubernetes is to shut down and restart nodes. This happens during auto-healing when a node stops responding and is recreated, or during auto-scaling down (e.g., some nodes are no longer loaded, and the orchestrator excludes them to save resources).
Since nodes and pods in Kubernetes can be dynamically removed and recreated, the application should be ready for this. It should not write any data that needs to be preserved to the container it is running in.
What to do?
You need to organize the application so that data is written to databases, files to S3 storage, and, say, cache to Redis or Memcache. By having the application store data "on the side," we significantly facilitate cluster scaling under load when additional nodes need to be added, and replication.
In a stateful application where data is stored in an attached Volume (roughly speaking, in a folder next to the application), everything becomes more complicated. When scaling a stateful application, you'll have to order "volumes," ensure they're properly attached and created in the right zone. And what do you do with this "volume" when a replica needs to be removed?
Yes, some business applications should be run as stateful. However, in this case, they need to be made more manageable in Kubernetes. You need an Operator, specific agents inside performing the necessary actions... A prime example here is the postgres-operator. All of this is far more labor-intensive than simply throwing the code into a container, specifying five replicas, and watching it all work without additional dancing.
Ensure Availability of Endpoints for Application Health Checks
Why?
We've already noted that Kubernetes itself ensures the application is maintained in the desired state. This includes checking the application's operation, restarting faulty pods, disabling load, restarting on less loaded nodes, terminating pods exceeding the set resource consumption limits.
For the cluster to correctly monitor the application's state, you should ensure the availability of endpoints for health checks, the so-called liveness and readiness probes. These are important Kubernetes mechanisms that essentially poke the container with a stick – check the application's viability (whether it's working properly).
What to do?
The liveness probes mechanism helps determine when it's time to restart the container so the application doesn't get stuck and continues to work.
Readiness probes are not so radical: they allow Kubernetes to understand when the container is ready to accept traffic. In case of an unsuccessful check, the pod will simply be excluded from load balancing – no new requests will reach it, but no forced termination will occur.
You can use this capability to allow the application to "digest" the incoming stream of requests without pod failure. Once a few readiness checks pass successfully, the replica pod will return to load balancing and start receiving requests again. From the nginx-ingress side, this looks like excluding the replica's address from the upstream.
Such checks are a useful Kubernetes feature, but if liveness probes are configured incorrectly, they can harm the application's operation. For example, if you try to deploy an application update that fails the liveness/readiness checks, it will roll back in the pipeline or lead to performance degradation (in case of correct pod configuration). There are also known cases of cascading pod restarts, when Kubernetes "collapses" one pod after another due to liveness probe failures.
You can disable checks as a feature, and you should do so if you don't fully understand their specifics and implications. Otherwise, it's important to specify the necessary endpoints and inform DevOps about them.
If you have an HTTP endpoint that can be an exhaustive indicator, you can configure both liveness and readiness probes to work with it. By using the same endpoint, make sure your pod will be restarted if this endpoint cannot return a correct response.
Aim for More Predictable and Uniform Application Resource Consumption
Why?
Almost always, containers inside Kubernetes pods are resource-limited within certain (sometimes quite small) values. Scaling in the cluster happens horizontally by increasing the number of replicas, not the size of a single replica. In Kubernetes, we deal with memory limits and CPU limits. Mistakes in CPU limits can lead to throttling, exhausting the available CPU time allotted to the container. And if we promise more memory than is available, as the load increases and hits the ceiling, Kubernetes will start evicting the lowest priority pods from the node. Of course, limits are configurable. You can always find a value at which Kubernetes won't "kill" pods due to memory constraints, but nevertheless, more predictable resource consumption by the application is a best practice. The more uniform the application's consumption, the tighter you can schedule the load.
What to do
Evaluate your application: estimate approximately how many requests it processes, how much memory it occupies. How many pods need to be run for the load to be evenly distributed among them? A situation where one pod consistently consumes more than the others is unfavorable for the user. Such a pod will be constantly restarted by Kubernetes, jeopardizing the application's fault-tolerant operation. Expanding resource limits for potential peak loads is also not an option. In that case, resources will remain idle whenever there is no load, wasting money. In parallel with setting limits, it's important to monitor pod metrics. This could be kube-Prometheus-Stack, VictoriaMetrics, or at least Metrics Server (more suitable for very basic scaling; in its console, you can view stats from kubelet—how much pods are consuming). Monitoring will help identify problem areas in production and reconsider the resource distribution logic.
There is a rather specific nuance regarding CPU time that Kubernetes application developers should keep in mind to avoid deployment issues and having to rewrite code to meet SRE requirements. Let's say a container is allocated 500 milli-CPUs—roughly 0.5 CPU time of a single core over 100 ms of real time. Simplified, if the application utilizes CPU time in several continuous threads (let's say four) and "eats up" all 500 milli-CPUs in 25 ms, it will be frozen by the system for the remaining 75 ms until the next quota period. Staging databases run in Kubernetes with small limits exemplify this behavior: under load, queries that would normally take 5 ms plummet to 100 ms. If the response graphs show load continuously increasing and then latency spiking, you've likely encountered this nuance. Address resource management—give more resources to replicas or increase the number of replicas to reduce load on each one.
Get a sample of IT Audit
Sign up now
Get on email
Loading...
Thank you!
You have successfully joined our subscriber list.
Leverage Kubernetes ConfigMaps, Secrets, and Environment Variables
Kubernetes has several objects that can greatly simplify life for developers. Study them to save yourself time in the future.
ConfigMaps are Kubernetes objects used to store non-confidential data as key-value pairs. Pods can use them as environment variables or as configuration files in volumes. For example, you're developing an application that can run locally (for direct development) and, say, in the cloud. You create an environment variable for your app—e.g., DATABASE_HOST—which the app will use to connect to the database. You set this variable locally to localhost. But when running the app in the cloud, you need to specify a different value—say, the hostname of an external database.
Environment variables allow using the same Docker image for both local use and cloud deployment. No need to rebuild the image for each individual parameter. Since the parameter is dynamic and can change, you can specify it via an environment variable.
The same applies to application config files. These files store certain settings for the app to function correctly. Usually, when building a Docker image, you specify a default config or a config file to load into Docker. Different environments (dev, prod, test, etc.) require different settings that sometimes need to be changed, for testing, for example.
Instead of building separate Docker images for each environment and config, you can mount config files into Docker when starting the pod. The app will then pick up the specified configuration files, and you'll use one Docker image for the pods.
Typically, iftheconfig files are large,youuse a Volume to mount them into Docker as files. If the config files contain short values, environment variables are more convenient. It all depends on yourapplication's requirements.
Another useful Kubernetes abstraction is Secrets. Secrets are similar to ConfigMaps but are meant for storing confidential data—passwords, tokens, keys, etc. Using Secrets means you don't need to include secret data in your application code. They can be created independently of the pods that use them, reducing the risk of data exposure. Secrets can be used as files in volumes mounted in one or multiple pod containers. They can also serve as environment variables for containers.
Disclaimer: In this point, we're only describing out-of-the-box Kubernetes functionality. We're not covering more specialized solutions for working with secrets, such as Vault.
Knowing about these Kubernetes features, a developer won't need to rebuild the entire container if something changes in the prepared configuration, for example, a password change.
Ensure Graceful Container Shutdown with SIGTERM
Why?
There are situations where Kubernetes "kills" an application before it has a chance to release resources. This is not an ideal scenario. It's better if the application can respond to incoming requests without accepting new ones, complete a transaction, or save data to a database before shutting down.
What to Do
A successful practice here is for the application to handle the SIGTERM signal. When a container is being terminated, the PID 1 process first receives the SIGTERM signal, and then the application is given some time for graceful termination (the default is 30 seconds). Subsequently, if the container has not terminated itself, it receives SIGKILL—the forced termination signal. The application should not continue accepting connections after receiving SIGTERM.
Many frameworks (e.g., Django) can handle this out of the box. Your application may already handle SIGTERM appropriately. Ensure that this is the case.
Here are a few more important points:
The Application Should Not Depend on Which Pod a Request Goes To
When moving an application to Kubernetes, we expectedly encounter auto-scaling—you may have migrated for this very reason. Depending on the load, the orchestrator adds or removes application replicas. The application mustn't depend on which pod a client request goes to, for example, static pods. Either the state needs to be synchronized to provide an identical response from any pod, or your backend should be able to work across multiple replicas without corrupting data.
Your Application Should Be Behind a Reverse Proxy and Serve Links Over HTTPS
Kubernetes has the Ingress entity, which essentially provides a reverse proxy for the application, typically an nginx with cluster automation. For the application, it's enough to work over HTTP and understand that the external link will be over HTTPS. Remember that in Kubernetes, the application is behind a reverse proxy, not directly exposed to the internet, and links should be served over HTTPS. When the application returns an HTTP link, Ingress rewrites it to HTTPS, which can lead to looping and a redirect error. Usually, you can avoid such a conflict by simply toggling a parameter in the library you're using, checking that the application is behind a reverse proxy. But if you're writing an application from scratch, it's important to remember how Ingress works as a reverse proxy.
Leave SSL Certificate Management to Kubernetes
Developers don't need to think about how to "hook up" certificate addition in Kubernetes. Reinventing the wheel here is unnecessary and even harmful. For this, a separate service is typically used in the orchestrator — cert-manager, which can be additionally installed. The Ingress Controller in Kubernetes allows using SSL certificates for TLS traffic termination. You can use both Let's Encrypt and pre-issued certificates. If needed, you can create a special secret for storing issued SSL certificates.