Every enterprise running digital operations is carrying a hidden liability. It doesn’t appear on balance sheets. It rarely surfaces in quarterly reviews. Yet it compounds quietly in server rooms, cloud environments, and configuration files — and by 2026, it is costing U.S. organizations an estimated $1.52 trillion every single year.
That liability is infrastructure debt — and it may be the most underestimated threat to your organization’s ability to innovate, scale, and compete.
Unlike the day-to-day friction of software bugs or poor UX, infrastructure debt operates beneath the surface of your digital estate. It lives in outdated hardware, fragile network configurations, manually patched servers, and cloud environments that have drifted far from any documented standard. It grows silently between sprints, accumulates across cloud migrations, and reveals itself at the worst possible moments: when you’re trying to scale an AI workload, when a critical system fails at 2 a.m., or when a security audit uncovers configuration gaps that have existed for years.
This guide is for the CTO who suspects their cloud environment has grown beyond control, the platform engineer frustrated by recurring incidents that trace back to the same aging components, and the IT leader who needs a language — and a framework — for communicating infrastructure risk to the board.
We will cover what infrastructure debt is, how it differs from other forms of technical debt, how to measure it rigorously, and — most importantly — how to build a sustainable strategy for managing it before it manages you.
What Is Infrastructure Debt? A Precise Definition
Infrastructure debt is a specific category within the broader landscape of technical debt — a term originally coined by software engineer Ward Cunningham to describe the rework costs that accumulate when speed is prioritized over quality. While technical debt as a concept typically conjures images of messy codebases and missing unit tests, infrastructure debt specifically targets the environmental layers that support software: physical and virtual servers, network topologies, storage systems, cloud configurations, and the automation pipelines that manage them.
Where code debt manifests as poor documentation or fragile logic inside a single application, infrastructure debt is systemic. It affects every service that runs on top of it. A single misconfigured Kubernetes cluster or an unpatched on-premises database server doesn’t just create one problem — it creates a category of risk across every workload that depends on that environment.
At Gart Solutions, we define infrastructure debt as:
The cumulative cost — financial, operational, and strategic — of suboptimal decisions made during the design, deployment, and maintenance of the underlying systems that support software applications. These costs manifest as increased operational risk, reduced system reliability, higher maintenance overhead, and constrained organizational agility.
This definition is important because it frames infrastructure debt not as a purely technical concern but as a business risk with measurable financial consequences.
The Full Taxonomy of Digital Debt: Where Infrastructure Fits
To manage infrastructure debt effectively, it helps to understand how it relates to the other categories of liability that accumulate across modern digital organizations. Each type has a distinct domain, manifestation, and detection mechanism:
| Category of Debt | Domain of Impact | Primary Manifestation | Detection Mechanism |
|---|---|---|---|
| Code Debt | Application Layer | Fragile logic, poor maintainability, “code smells” | Static analysis, peer reviews |
| Infrastructure Debt | Environment Layer | Manual patches, outdated hardware, configuration drift | Infrastructure audits, automated drift detection |
| Architecture Debt | Systemic Layer | Monolithic silos, rigid integrations, scalability caps | Portfolio analysis, architecture reviews |
| Data Debt | Intelligence Layer | Schema mismatches, poor partitioning, replication lags | Latency monitoring, data quality audits |
| Cultural Debt | Human Layer | Knowledge silos, fear of failure, resistance to change | Qualitative surveys, team dynamic observation |
Infrastructure debt and architecture debt are frequently confused — and conflated — by engineering teams. The distinction matters operationally. Architecture debt arises from flawed structural decisions at the system level: fragile point-to-point integrations, duplicated platforms, monolithic designs that prevent horizontal scaling. Infrastructure debt is more immediate: it’s the outdated AMI on your EC2 instance, the manually edited security group, the storage volume no one has touched in three years but everyone is afraid to delete.
Architecture debt is often invisible during standard code reviews or pull requests. It only reveals itself during critical transformation phases — such as a cloud migration or the scaling of an AI initiative — when the underlying inconsistencies prevent adoption of modern operational patterns.
How Infrastructure Debt Accumulates: The Root Causes
Understanding where infrastructure debt comes from is the first step toward preventing its accumulation. The genesis is rarely accidental — it is the predictable outcome of identifiable operational pressures.
1. Time-to-Market Pressure: The Velocity-Quality Trade-off
The most pervasive driver of infrastructure debt is the tension between delivery speed and structural quality. When sprint goals demand a working data pipeline by Friday, the engineer who knows it won’t scale to projected volumes in Q3 often has no choice but to ship it anyway. This is the “Velocity-Quality Trade-off” in its most common form: an organization intentionally borrows against the future to achieve short-term business objectives.
This is not inherently wrong. Taking on calculated debt to accelerate a market opportunity can be a rational strategic decision. The problem arises when the “repayment plan” never materializes — when the temporary solution becomes permanent infrastructure, and the team that built it has long since moved on.
2. The Skill and Knowledge Gap
As organizations adopt complex cloud-native technologies — Kubernetes, Terraform, service meshes, event-driven architectures — the expertise required to manage these systems often lags significantly behind their deployment. Inexperienced engineers may introduce infrastructure debt through poor Kafka broker configurations, misconfigured cloud security groups, or Terraform modules that lack the state management practices required for safe, collaborative use.
This gap is not a reflection of talent shortages alone. It is also a governance failure: organizations are deploying technology faster than they are training the people responsible for operating it.
3. Legacy System Inertia and the Brownfield Burden
Many enterprises are burdened by what practitioners call “brownfield” applications — systems that have passed through multiple development teams over decades. Each handover introduces inconsistencies in standards and design patterns, leading to fragmented, tightly coupled architectures that are extraordinarily difficult to modernize. Documentation debt — where critical system paths and API specifications are either missing or dangerously outdated — compounds this problem, causing new teams to reimplement existing functionality rather than reusing it.
The result is a digital environment where no one has a complete map, and where every infrastructure change carries an asymmetric risk: a small modification can trigger cascading failures in systems that were never properly documented.
4. “Dark Debt”: The Underinvestment in Testing and Observability
Perhaps the most dangerous category of infrastructure debt is the kind that remains invisible until it isn’t. Dark debt emerges from underinvestment in testing and observability infrastructure — the monitoring, tracing, and alerting systems that make the health of your environment legible. When these systems are absent or inadequate, debt hides in the complex interactions between system components, accumulating silently until a catastrophic failure forces it into view.
Dark debt is particularly common in fast-growing organizations that scaled rapidly and “bolted on” observability after the fact, or in enterprises where observability was deprioritized during cloud migrations in favor of raw lift-and-shift speed.
5. Cultural Debt: The Human Amplifier
Technical debt and cultural debt exist in a destructive feedback loop. A dysfunctional culture — characterized by unclear ownership, misaligned incentives, and a pervasive “fear of failure” — leads teams to avoid touching fragile infrastructure components. This avoidance allows debt to compound undisturbed. The resulting brittleness then reinforces team silos, as engineers become increasingly reluctant to take responsibility for systems they don’t feel safe modifying.
Breaking this cycle requires more than technical solutions. It requires deliberate cultural intervention.
The Real Cost of Infrastructure Debt: By the Numbers
The financial case for addressing infrastructure debt has never been clearer — or more urgent.
- The total annual cost of technical debt in the United States reached $2.41 trillion, with infrastructure debt accounting for $1.52 trillion of that figure.
- This represents a near-doubling of these liabilities over the past decade, driven by the accelerating adoption of cloud-native technologies and the complexity they introduce.
- Organizations managing below-average levels of technical debt demonstrate a revenue growth rate of 5.3%, significantly outperforming high-debt peers who struggle at 4.4% — a gap that compounds meaningfully over time.
- Cloud waste alone — driven by unattached storage volumes, idle instances, and over-provisioned resources — can inflate cloud budgets by up to 30% annually.
- Organizations that invest in remediation typically see a 300% ROI through reduced maintenance costs and increased developer throughput.
- By 2026, 75% of technology decision-makers expect technical debt to rise to moderate or high severity, driven primarily by the demands of generative AI adoption.
These figures underscore a fundamental strategic reality: infrastructure debt is not a technology problem.
It is a business risk with a balance sheet.
How to Measure Infrastructure Debt: The Quantitative Framework
Moving from intuition to action requires rigorous measurement. Technical leaders who can quantify their infrastructure debt are far better positioned to prioritize remediation investments and communicate risk to executive stakeholders.
The Technical Debt Ratio (TDR)
The industry-standard formula for assessing the viability of remediation versus replacement is the Technical Debt Ratio:
TDR = (Remediation Cost ÷ Development Cost) × 100
- A TDR below 5% is generally indicative of a healthy system.
- Ratios exceeding 5% suggest escalating operational risk.
- When TDR approaches 100%, the cost of fixing the system equals the cost of a complete rebuild — often making modernization the more cost-effective choice.
This formula provides a defensible, quantitative basis for the “fix vs. replace” conversation that infrastructure teams regularly face — and struggle to win — with finance and executive leadership.
The Seven Core Infrastructure Health Metrics
In 2025, DevOps and platform engineers focus on seven metrics to monitor structural decay and resource pressure in real time:
1. Saturation
Measures the pressure on compute resources: CPU, memory, thread pools. High saturation (consistently above 85% CPU) can lead to pod evictions and latency spikes, signaling that infrastructure is no longer appropriately sized for its workload.
2. Infrastructure Drift and Change Frequency
Tracks how often manual edits are made outside of the Infrastructure as Code (IaC) pipeline. Frequent drift is a direct measure of infrastructure debt accumulation — every manual change is an undocumented deviation from the desired state, increasing the risk of unexpected outages during routine deployments.
3. Latency Percentiles (P95 and P99)
Reveals performance bottlenecks that averages systematically hide. If your P99 latency is 10x your P50, you have significant infrastructure issues — potentially cache misses, database query delays, or network congestion — that aggregate metrics will never surface.
4. Cloud Waste Metrics
Monitors the cost and stability impact of “zombie” resources: unattached storage volumes, idle compute instances, oversized reserved capacity. These resources represent pure, recoverable infrastructure debt — paying for something that provides no value while adding management complexity.
5. Mean Time to Resolve (MTTR) and Mean Time to Detect (MTTD)
Evaluates the effectiveness of the monitoring and incident response stack. High MTTR is often a direct consequence of infrastructure debt: brittle systems are harder to diagnose, and fragmented observability makes root cause analysis slow and uncertain.
6. Disk I/O and Storage Latency
Identifies “silent bottlenecks” where applications degrade due to exhausted IOPS, even when CPU usage appears normal. Storage performance issues are a classic symptom of infrastructure debt that has been deferred through repeated patching rather than architectural remediation.
7. Network Saturation and Retransmits
Monitors packet loss and congestion within Virtual Private Clouds (VPCs) that lead to request timeouts. Network debt — the accumulation of undocumented routing rules, legacy security groups, and ad-hoc peering configurations — is among the most complex and dangerous forms of infrastructure debt to remediate.
DORA Metrics: The Organizational Diagnostic
Beyond infrastructure-specific metrics, the DORA (DevOps Research and Assessment) framework provides a powerful organizational diagnostic for infrastructure health:
| DORA Metric | High Performance (Elite) | Low Performance | Strategic Implication |
|---|---|---|---|
| Deployment Frequency | Multiple times per day | Once per month or less | High frequency reduces risk per release |
| Lead Time for Changes | Less than one hour | More than six months | Long lead times indicate workflow bottlenecks |
| Change Failure Rate | 0%–15% | Above 45% | High failure rates signal inadequate quality gates |
| Mean Time to Recovery | Less than one hour | More than one week | Fast recovery indicates system resilience |
Organizations with high infrastructure debt consistently perform in the “low performance” tier across these metrics — particularly on Change Failure Rate and MTTR, which are most directly influenced by the quality and reliability of the underlying infrastructure.
Infrastructure as Code: The Primary Technical Remedy
The single most impactful technical strategy for preventing and remediating infrastructure debt is the adoption of Infrastructure as Code (IaC) — the practice of defining, versioning, and managing infrastructure through declarative or procedural code rather than manual configuration.
By treating infrastructure as versioned code, organizations can eliminate the “snowflake” configurations — unique, manually configured environments that cannot be reliably reproduced or audited — that define legacy environments and represent the densest concentrations of infrastructure debt.
Choosing the Right IaC Tool
| IaC Tool | Philosophy | Language Support | Key Advantage |
|---|---|---|---|
| Terraform | Declarative | HCL | Massive ecosystem, mature state management |
| Pulumi | Hybrid | Python, TypeScript, Go, C# | General-purpose programming for complex logic |
| Ansible | Procedural | YAML | Excellence in configuration management |
| OpenTofu | Declarative | HCL | Open-source, community-driven Terraform alternative |
| AWS CloudFormation | Declarative | JSON, YAML | Native AWS integration and stack management |
The choice of IaC tool is secondary to the discipline of using it consistently. A robust IaC strategy requires twelve operational best practices: automating the creation of IaC from existing cloud accounts, ensuring modularity through reusable templates, integrating policy-as-code guardrails, enforcing peer reviews before any infrastructure change reaches production, and making console-only changes a policy violation rather than a convenience.
The IaC Anti-Patterns That Create New Debt
IaC is not a silver bullet. Without discipline, it becomes a new source of infrastructure debt. The most common IaC anti-patterns include:
- Hardcoded secrets embedded in configuration files, creating security debt that compounds with every commit
- Copy-paste configurations that replicate errors across environments and make refactoring exponentially more complex
- Console-only changes made during incidents that are never reflected in the IaC repository, creating drift from day one
- Monolithic modules that bundle unrelated infrastructure components, making testing and rollback difficult
- Missing remote state management, which allows multiple engineers to apply conflicting changes simultaneously
Policy as Code: Automating Compliance
A critical evolution of IaC practice is policy as code — the use of tools like Open Policy Agent (OPA) or Kyverno to automate the enforcement of security and compliance rules before infrastructure is provisioned. Policy as code can block unencrypted storage buckets, flag oversized instance types, and enforce tagging standards automatically, preventing entire categories of infrastructure debt from being introduced at the source.
Immutable Infrastructure: Replacing Instead of Patching
The most advanced IaC organizations have moved beyond configuration management to immutable infrastructure — an approach where components are replaced rather than patched in place. Every deployment produces a new, clean environment from a known, versioned artifact. This approach eliminates configuration drift by design, simplifies vulnerability management, and dramatically reduces the operational complexity that accumulates through repeated in-place patching.
GitOps: Making the Desired State Non-Negotiable
GitOps extends the principles of IaC by establishing Git as the single source of truth for the entire infrastructure state. In a GitOps model, every infrastructure change is a pull request. Every deployment is a reconciliation between the Git repository and the live environment. Every deviation from the desired state is automatically detected and remediated.
This model provides three capabilities that are directly relevant to infrastructure debt management:
1. Complete Audit Trail
Because every change is recorded in Git, organizations gain a complete, immutable history of their infrastructure state. This is invaluable for compliance audits, incident post-mortems, and the forensic analysis of debt accumulation patterns.
2. Automated Drift Remediation
GitOps controllers — ArgoCD, Flux, and similar tools — continuously reconcile the live state of infrastructure with the desired state defined in the repository. When drift is detected (as it inevitably will be, particularly after manual interventions during incidents), the controller can automatically revert the deviation and restore the known good state. This “self-healing” capability is essential for managing large-scale, multi-cluster environments where manual oversight is operationally impossible.
3. Security Through Pull Request Governance
By requiring peer reviews, automated policy checks, and branch protection rules before any change merges to the main branch, GitOps creates multiple opportunities to catch errors and security vulnerabilities before they reach production. Combined with secrets management platforms like HashiCorp Vault or Sealed Secrets, this model ensures that sensitive data is encrypted at rest and accessible only to authorized services during runtime.
Auditing Your Infrastructure: Where to Start
Before any remediation can begin, you need a complete and honest picture of what you have. A rigorous infrastructure audit is the foundation of effective debt management.
At Gart Solutions, our infrastructure audit process addresses four domains:
Asset Inventory and End-of-Life Assessment
A comprehensive catalog of all hardware and software assets, cross-referenced against vendor support lifecycles. End-of-life (EOL) equipment — operating systems, databases, network appliances, and cloud services past their supported maintenance windows — represents concentrated infrastructure debt because it receives no security patches and is typically excluded from vendor SLA commitments.
Network Topology Review
Evaluation of network architecture to identify single points of failure, undocumented routing rules, legacy security groups, and peering configurations that have accumulated over years of ad-hoc modification. Network topology debt is among the most dangerous to carry because network failures have the broadest blast radius of any infrastructure component.
Reliability and Resilience Assessment
Systematic testing of failover mechanisms, backup and recovery procedures, and disaster recovery capabilities. This assessment frequently surfaces “dark debt” — resilience assumptions that were documented but never tested, or that were valid at one point in the system’s lifecycle but have since been invalidated by configuration changes.
Cloud Architecture Review
Validation that cloud configurations are optimized for scalability, security, and cost efficiency. This includes analysis of IAM policies, VPC configurations, storage lifecycle rules, instance sizing, and Reserved Instance coverage — all common sources of cloud-specific infrastructure debt.
Observability: Making Infrastructure Debt Visible in Real Time
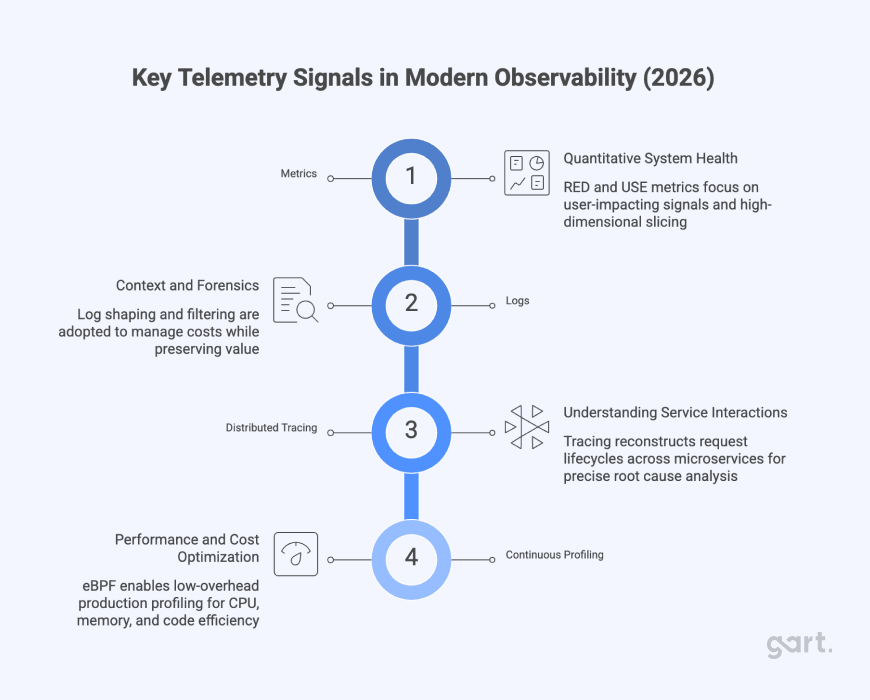
Audits provide a point-in-time snapshot. Observability provides the continuous visibility required to detect infrastructure debt as it accumulates and to correlate infrastructure health with application performance and business outcomes.
Modern observability platforms connect logs, metrics, and traces into unified views that enable faster root cause analysis and more confident infrastructure changes. Leading infrastructure monitoring solutions in 2025 include Datadog, New Relic, and Grafana — each offering real-time dashboards, intelligent alerting, and root cause analysis capabilities that transform raw infrastructure data into actionable operational intelligence.
For data infrastructure specifically, data observability tools like Monte Carlo and SYNQ track “data downtime” — periods when data is inaccurate, missing, or inconsistent — using AI-powered anomaly detection to identify schema changes, volume discrepancies, and pipeline failures before they affect downstream consumers.
The key observability signals for infrastructure debt monitoring include:
- Anomalous latency patterns that indicate degrading infrastructure components
- Increasing error rates correlated with specific infrastructure changes or configurations
- Rising resource saturation trends that signal approaching capacity limits
- Drift detection alerts from GitOps controllers that indicate unauthorized manual changes
- Cost anomalies that reveal zombie resources and inefficient provisioning patterns
Strategic Remediation: A Prioritization Framework
Remediating infrastructure debt is not a sprint — it is a sustained strategic program. The organizations that succeed treat it as liability management, not a one-time cleanup project.
The foundational principle of effective remediation is the 80/20 rule of technical debt: 20% of your infrastructure debt is causing 80% of your operational problems. Identifying and targeting that 20% — the highest-impact, highest-risk debt clusters — delivers disproportionate operational improvement and builds organizational momentum for deeper remediation work.
Four Proven Remediation Patterns
1. Tactical Reengineering
Upgrading systems and refactoring infrastructure “low-and-slow” — making incremental improvements that avoid downtime while delivering faster return on investment. This approach is best suited for systems with high operational dependency that cannot tolerate the disruption of a wholesale replacement.
2. Cloud-Native Refactoring
Adopting microservices, containerization, and serverless patterns to modularize functionality and isolate problematic infrastructure components. This approach addresses architecture debt and infrastructure debt simultaneously, replacing monolithic environments with loosely coupled services that can be upgraded, scaled, and replaced independently.
3. Lift-and-Shift to Modern Platforms
Transitioning away from brittle on-premises databases and aging infrastructure to managed cloud services that reduce operational overhead and eliminate entire categories of patching and maintenance debt. This approach delivers the fastest time-to-value for organizations with significant on-premises legacy debt.
4. Resource Optimization and Right-Sizing
Implementing automated right-sizing, storage lifecycle policies, and Reserved Instance planning to eliminate cloud waste and deliver immediate cost savings. This is often the fastest-returning remediation investment available and provides the budget justification for deeper, longer-cycle modernization work.
The Modernization Scorecard
For organizations with complex legacy estates, modernization scorecards provide a structured methodology for prioritizing remediation investment. By mapping debt density against business value for each system in the portfolio, enterprise architects can ensure that remediation efforts are aligned with the strategic roadmap — investing most heavily in modernizing the systems that are both highly indebted and strategically critical.
Organizational Enablement: Addressing Cultural Debt
No technical framework for managing infrastructure debt will succeed in an organization where the culture works against it. The most sophisticated GitOps workflow is useless if engineers are afraid to touch the infrastructure it manages. The most comprehensive monitoring platform is irrelevant if no one is empowered to act on what it reveals.
The Cloud Center of Excellence (CCoE)
Establishing a Cloud Center of Excellence provides the multi-disciplinary governance required to scale modern infrastructure practices. A CCoE focuses on creating repeatable patterns, training engineering personnel, establishing architectural standards, and — critically — preventing the accumulation of new infrastructure debt through proactive governance rather than reactive cleanup.
Blame-Free Incident Culture
Fostering a “blame-free” culture during incident retrospectives encourages transparency and allows teams to identify the systemic root causes of failures rather than focusing on individual human error. This is essential for surfacing infrastructure debt that would otherwise remain hidden, as engineers in blame-heavy cultures routinely avoid reporting problems with systems they didn’t create and can’t easily fix.
Developer Experience as a Leading Indicator
Developer Experience (DX) is a powerful qualitative measure of infrastructure debt’s organizational impact. When engineers spend more time fighting legacy systems than building new features — navigating brittle deployment pipelines, waiting for slow test environments, manually intervening in processes that should be automated — it manifests as friction, frustration, and ultimately burnout.
Research increasingly shows that top engineering talent actively avoids organizations with outdated technology stacks. Infrastructure debt is not just a technology problem — it is a talent retention problem and, consequently, a competitive disadvantage.
Emerging Frontiers: AI Debt and Multi-Cloud Complexity
The infrastructure debt challenge is not static. Two emerging trends are poised to significantly expand its scope and complexity.
AI and GenAI Infrastructure Debt
The rapid adoption of generative AI is introducing a new category of infrastructure debt: the accumulated cost of AI implementation shortcuts and the scaling challenges of compute-intensive AI workloads. AI places extreme demands on global infrastructure — data center power, GPU availability, networking bandwidth, and storage throughput — and organizations that scaled their AI initiatives without proportional infrastructure investment are now discovering significant structural debt in their AI platforms.
By 2025, 75% of technology decision-makers expect technical debt to rise to moderate or high severity, with AI adoption cited as a primary driver. The organizations that address this proactively — building AI infrastructure on well-governed, IaC-managed, observable foundations — will have a significant operational advantage as AI workloads continue to scale.
Multi-Cloud Complexity
While 89% of enterprises have embraced multi-cloud strategies to avoid vendor lock-in and optimize for specific workload requirements, this diversification increases infrastructure debt through fragmented governance and the need for specialized expertise across multiple cloud ecosystems. Each cloud provider introduces its own configuration syntax, security model, networking constructs, and operational tooling — and the gaps between them become repositories for undocumented, inconsistently managed infrastructure.
The multi-cloud networking market is projected to reach $13.14 billion by 2033, reflecting the scale of investment organizations will need to make in automation and observability capabilities that can span these distributed environments effectively.
ESG and the Carbon Cost of Infrastructure Debt
Aging, energy-inefficient data centers consume significant power and cooling resources, often falling well short of modern environmental standards. As ESG commitments move from aspirational to board-level priority, the carbon impact of legacy infrastructure is becoming a concrete driver for modernization. Organizations carrying significant on-premises infrastructure debt are increasingly discovering that their environmental compliance obligations provide an additional, non-technical justification for cloud migration and data center consolidation programs.
The Gart Solutions Approach: from Assessment to Resilience
At Gart Solutions, we approach infrastructure debt management as a strategic advisory engagement — not a one-time fix. Our framework combines the quantitative rigor of infrastructure audits and health metrics with the operational expertise to translate findings into prioritized, actionable remediation roadmaps.
Our engagements typically follow four phases:
Phase 1: Discovery and Baseline
Comprehensive infrastructure audit covering asset inventory, network topology, cloud architecture, and reliability posture. We establish baseline metrics — TDR, DORA performance tier, drift frequency, cloud waste — that provide the quantitative foundation for prioritization decisions.
Phase 2: Debt Mapping and Business Impact Analysis
Using modernization scorecard methodology, we map debt density against business value across the infrastructure portfolio. This produces a prioritized debt register that connects technical findings to business risk, enabling executive-level prioritization conversations grounded in operational reality.
Phase 3: Remediation Architecture
Development of a phased modernization roadmap aligned with the organization’s strategic priorities, budget cycles, and risk tolerance. This includes IaC migration planning, GitOps implementation, observability platform selection, and cloud optimization strategies.
Phase 4: Continuous Governance
Establishment of the governance structures, tooling, and cultural practices required to prevent infrastructure debt from reaccumulating: IaC standards, policy-as-code guardrails, drift detection automation, regular audit cadences, and CCoE enablement.
Conclusion: Infrastructure Debt Is a Strategic Choice
Infrastructure debt is inevitable. Every organization operating at speed will accumulate some degree of structural compromise in its digital estate. The question is never whether you have infrastructure debt — it’s whether you are managing it deliberately or letting it manage you.
The organizations that will lead their industries through the next wave of digital transformation — AI adoption, multi-cloud optimization, global scaling — are the ones that treat infrastructure debt as a strategic liability: auditing it regularly, measuring it rigorously, prioritizing its remediation through the 80/20 rule, and building the cultural and governance foundations that prevent its uncontrolled accumulation.
The technical tools exist. GitOps, IaC, policy as code, observability platforms, and cloud-native architectures have matured to the point where any organization can deploy them effectively with the right guidance. The harder work — and the more valuable work — is building the operational discipline and organizational culture that makes these tools effective over time.
In 2026 and beyond, a healthy infrastructure debt ratio will be the defining characteristic of elite technology organizations. It will determine who can move fast without breaking things, who can adopt AI at scale, and who can attract and retain the engineering talent necessary to compete.
The debt is already on your books. The question is what you do about it.
Interested in understanding your organization’s infrastructure debt position? Contact the Gart Solutions team to schedule an Infrastructure Audit — the first step toward a resilient, high-performance digital foundation.
See how we can help to overcome your challenges