⚡ Key Takeaways
IT infrastructure security protects hardware, software, networks, and data from threats ranging from ransomware to insider attacks.
A mature security posture combines Zero Trust architecture, proactive monitoring, and a documented incident response plan.
Cloud and Kubernetes environments require dedicated controls—misconfigured IAM roles and exposed dashboards are among the most common attack vectors.
Frameworks such as NIST CSF, CIS Benchmarks, and ISO 27001 provide a structured roadmap for resilience.
Human error remains the root cause in ~70% of security incidents—training and culture matter as much as tooling.
IT infrastructure security is the discipline of protecting every layer of your technology stack—hardware, networks, servers, cloud environments, and the data flowing between them—from unauthorized access, disruption, and theft. In 2025, it is not optional: a single ransomware event can cost a mid-market company millions in recovery, downtime, and reputational damage.
At Gart Solutions, we have worked with dozens of engineering teams to harden their infrastructure across AWS, Azure, GCP, and hybrid on-premises setups. This article shares what actually works—combining frameworks, tooling, and first-hand operational insight—so you can build a security posture that holds up under real-world attack conditions.
What Is IT Infrastructure Security?
IT infrastructure security encompasses all the policies, technologies, and practices an organization uses to defend its physical and virtual computing resources. It spans:
Network security — firewalls, VPNs, segmentation, intrusion detection
Server and endpoint security — hardening, patch management, RBAC, endpoint detection
Cloud security — IAM policies, encryption, misconfiguration scanning, compliance posture
Data security — encryption at rest and in transit, data classification, DLP controls
Operational security — change management, logging, monitoring, incident response
According to NIST's Cybersecurity Framework, a mature approach spans five functions: Identify, Protect, Detect, Respond, and Recover. Organizations that skip any one of these are disproportionately exposed when an incident occurs.
Top Threats to IT Infrastructure Security
Ransomware & Malware
Ransomware continues to be the most financially damaging threat. Modern ransomware groups operate as businesses—with affiliates, support desks, and negotiation teams. Double-extortion tactics (encrypt + threaten to publish) mean even organizations with good backups face significant pressure.
Gart field example: During a security audit for a SaaS client, we discovered an unpatched Windows Server 2016 instance exposed to the internet on RDP port 3389. It had been compromised by a credential-stuffing bot two weeks earlier. Isolating the host, rotating all privileged credentials, and patching reduced their exploitable attack surface by an estimated 60% within 48 hours.
Cloud Misconfigurations
Cloud misconfigurations are the leading cause of data breaches in cloud environments. According to CNCF's cloud-native security research, the most dangerous misconfigurations include:
Over-permissive IAM roles granting admin access to entire accounts
Public S3 buckets containing sensitive data or configuration files
Exposed Kubernetes API servers and dashboards without authentication
Unrestricted security group rules (0.0.0.0/0 inbound on sensitive ports)
Disabled CloudTrail / logging in production accounts
Gart field example: During one infrastructure audit, we identified over-provisioned public Azure endpoints causing both cost leakage and security exposure. Migrating workloads to private networking reduced the attack surface significantly and cut network-related costs by over 90%. What looked like a billing issue turned out to be an open door for lateral movement.
Phishing & Social Engineering
Human error remains the root cause of approximately 70% of security incidents, according to published security research. Even technically robust environments are vulnerable if employees can be manipulated into clicking a link, approving an MFA push, or sharing credentials. AI-generated spear-phishing emails are making this problem harder to defend against purely through tooling.
Insider Threats
Insider threats—both malicious and unintentional—are among the hardest to detect because insiders have legitimate access. A disgruntled engineer with production database credentials, or an overly curious employee with access they never needed, can cause more damage than most external attackers.
DDoS Attacks
Distributed Denial of Service attacks have grown in scale and sophistication. Multi-vector attacks now combine volumetric floods with application-layer exploitation, making mitigation harder. Organizations without proper DDoS protection can face extended outages costing tens of thousands of dollars per hour.
How Gart Secures IT Infrastructure: Our 7-Phase Process
After dozens of security engagements, we have refined a repeatable methodology that works for both cloud-native and hybrid environments. Here is what a structured security audit and remediation cycle looks like in practice:
Discovery & Asset InventoryWe enumerate every asset: servers, containers, cloud accounts, third-party integrations, and data stores. You cannot secure what you cannot see. We use automated scanning alongside manual review to build a complete inventory.
Threat ModellingWe map realistic attack paths using the STRIDE model (Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege). This prioritizes where adversaries are most likely to gain a foothold.
Risk Assessment & ScoringEach finding is scored by exploitability, business impact, and remediation effort. We use a CVSS-aligned scoring system to produce a risk-prioritized backlog—so your team fixes the right things first, not just the easiest.
Remediation & HardeningWe address critical and high findings immediately: rotate credentials, restrict network access, apply patches, and fix IAM policies. Medium findings enter a sprint-based remediation backlog with defined owners and deadlines.
Continuous Monitoring ImplementationWe deploy or tune SIEM/alerting tooling (Datadog, Prometheus, Falco, CloudTrail Insights) to catch anomalies in real time. Dashboards and runbooks are handed to your operations team.
Incident Response PlaybookWe create or update your incident response plan, defining roles, escalation paths, communication templates, and containment procedures for the top five likely incident scenarios specific to your stack.
Continuous Optimization & Re-testingSecurity is not a project; it is a program. We schedule quarterly re-assessments, track remediation progress, and run tabletop exercises to keep readiness high as your infrastructure evolves.
Security Frameworks That Actually Drive Results
Frameworks give your security program a common language and a measurable baseline. The three we recommend most consistently are:
NIST Cybersecurity Framework (CSF 2.0)
The NIST CSF organizes security activities into six functions: Govern, Identify, Protect, Detect, Respond, Recover. It is technology-agnostic and widely recognized, making it an excellent foundation whether you are cloud-only or running a hybrid environment. See the official NIST CSF documentation for implementation tiers and profiles.
CIS Benchmarks
CIS Benchmarks provide prescriptive hardening guidance for specific technologies—Linux distributions, AWS, Azure, GCP, Kubernetes, Docker, and hundreds more. They are the closest thing to "best practice in a checklist" that exists. Automating CIS benchmark compliance checks as part of your CI/CD pipeline is one of the highest-ROI security investments an engineering team can make.
ISO 27001
ISO/IEC 27001 is the international standard for information security management systems (ISMS). It is particularly important for organizations serving enterprise or regulated-industry clients who require formal certification. ISO 27001 demands documented controls, management commitment, and regular audits—making it a robust driver of organizational security maturity.
Zero Trust Architecture: Beyond the Perimeter
The old perimeter model—"trust everything inside the firewall"—is dead. Modern environments are multi-cloud, have remote workforces, and rely on dozens of SaaS integrations. The attack surface is now everywhere.
Zero Trust architecture operates on the principle of "never trust, always verify." Every request—whether from inside or outside the network—must be authenticated, authorized, and continuously validated. Core Zero Trust pillars include:
Identity as the perimeter — MFA enforced for all accounts, including service accounts; privileged access management (PAM) for admin credentials
Least-privilege access — users and services get only the minimum permissions required; access is reviewed and revoked regularly
Micro-segmentation — workloads are isolated so a breach in one segment cannot move laterally to another
Device health verification — only compliant, managed devices can access sensitive resources
Continuous monitoring — real-time behavioral analysis to detect anomalies, not just signature-based threat detection
Kubernetes Security Best Practices
Kubernetes adoption has accelerated dramatically, and with it, a new category of infrastructure security challenges. Kubernetes clusters that are not properly hardened are a particularly attractive target because a single misconfiguration can give an attacker access to all workloads running on the cluster.
The critical Kubernetes security controls we implement for every client:
RBAC configuration — define roles at namespace level; eliminate cluster-admin bindings for non-admin users; audit service account token usage
Network Policies — restrict pod-to-pod communication to only what is explicitly required; default deny all ingress and egress at the namespace level
Pod Security Standards — enforce restricted or baseline Pod Security Standards to prevent privilege escalation and host namespace access
Image scanning in CI/CD — scan container images for known vulnerabilities before they reach production; block images above a defined severity threshold
Secrets management — never store secrets in environment variables or ConfigMaps; use Vault, AWS Secrets Manager, or Kubernetes External Secrets Operator
Runtime security — deploy Falco to detect anomalous behavior at the kernel level; alert on unexpected syscalls, privilege escalations, or outbound connections
Etcd encryption — encrypt etcd at rest; restrict etcd access to control plane nodes only
Reactive IT Support vs. Proactive Infrastructure Security
Many organizations realize they have a security gap only after an incident. Here is the structural difference between reactive IT support and a proactive IT infrastructure security program:
AreaReactive IT SupportProactive Infrastructure Security RecommendedMonitoringManual checks; problems found after users report them24/7 automated SIEM & alerting; anomalies caught in real timeThreat DetectionAfter the incident has occurredContinuous behavioral analysis & threat intelligence feedsPatch ManagementAd hoc; often delayed weeks or monthsAutomated patching with defined SLAs by severity levelAccess ControlBroad roles; access rarely reviewed or revokedLeast-privilege RBAC; quarterly access reviews; PAM for admin credentialsCompliancePeriodic point-in-time auditsContinuous compliance scanning; drift detection & remediationIncident ResponseImprovised; slow; relies on institutional memoryDocumented playbooks; defined roles; regular tabletop exercisesDisaster RecoveryBackups exist but rarely testedAutomated DR with tested, documented RTO/RPO targetsCost ProfileLow upfront, high incident cost (avg. $4.5M per data breach)Predictable investment; significantly lower incident exposure
Cloud Infrastructure Security: AWS, Azure & GCP
Figure 2: Core cloud security controls applied across multi-cloud environments.
Cloud environments introduce shared-responsibility complexity. The cloud provider secures the underlying infrastructure; you are responsible for everything you build on top of it—and most breaches happen in that "your responsibility" zone.
AWS Security Essentials
On AWS, the highest-impact controls are: enabling AWS Organizations SCPs to enforce guardrails account-wide; using AWS Security Hub with CIS Benchmark findings enabled; enabling GuardDuty for threat detection; and enforcing VPC endpoint usage to keep traffic off the public internet. Never use root credentials for day-to-day operations—create dedicated IAM users and roles with the minimum required permissions.
Azure Security Essentials
For Azure environments, Microsoft Defender for Cloud provides a unified security score and actionable recommendations. Enable Azure Policy to enforce organizational standards at scale; use Privileged Identity Management (PIM) for just-in-time admin access; and enable Diagnostic Settings on all resources so audit logs flow to a centralized Log Analytics Workspace.
Multi-Cloud Governance
In multi-cloud setups, inconsistent security policies across providers are a major risk. We recommend adopting a cloud-agnostic CSPM (Cloud Security Posture Management) tool—such as Wiz, Prisma Cloud, or open-source alternatives—that provides a unified view of misconfigurations, compliance gaps, and attack paths across all cloud accounts.
Incident Response: A Practical Playbook
Figure 3: The incident response lifecycle — from detection through post-incident review.
The difference between a contained incident and a catastrophic breach is almost always the quality of your incident response capability. An effective IR process has six phases:
Preparation — Documented playbooks, defined team roles, pre-approved communication templates, and legal/PR contacts on speed dial.
Detection & Analysis — SIEM alerts, anomaly detection, and threat intelligence feeds surface the incident. Analysts triage to confirm and scope the breach.
Containment — Short-term containment (isolate affected systems) followed by long-term containment (patch, reconfigure) to stop the bleeding without destroying forensic evidence.
Eradication — Remove malware, revoke compromised credentials, close the attack vector, and verify no persistence mechanisms remain.
Recovery — Restore systems from clean backups or known-good states. Validate system integrity before returning to production. Monitor intensively for re-compromise.
Post-Incident Review — A blameless retrospective that documents root cause, timeline, response effectiveness, and specific improvements to prevent recurrence.
Gart helps clients build and test these playbooks through tabletop exercises tailored to their stack. See our Disaster Recovery as a Service offering for organizations that need guaranteed RTO/RPO commitments.
IT Infrastructure Security Best Practices Checklist
Whether you are running a startup or an enterprise, these controls form the baseline of a defensible security posture. Use this as a starting-point checklist for your next infrastructure audit:
Control AreaWhat to ImplementPriorityIdentity & AccessMFA everywhere; least-privilege RBAC; PAM for admin credentials; quarterly access reviews🔴 CriticalPatch ManagementAutomated patching with SLAs: critical in 24h, high in 7 days, medium in 30 days🔴 CriticalNetwork SecurityMicro-segmentation; default-deny network policies; VPN or Zero Trust Network Access for remote work🔴 CriticalData EncryptionTLS 1.2+ in transit; AES-256 at rest; encrypted backups; secrets in a vault (not plaintext configs)🔴 CriticalMonitoring & LoggingSIEM with 90-day log retention; real-time alerts on privilege escalation, login anomalies, data exfiltration🟠 HighKubernetes SecurityRBAC; Network Policies; Pod Security Standards; image scanning in CI/CD; Falco for runtime detection🟠 HighCloud PostureCSPM tool enabled; CIS Benchmark compliance; no publicly accessible storage unless explicitly required🟠 HighBackup & DRAutomated daily backups; immutable backup storage; quarterly DR tests with documented RTO/RPO🟠 HighEmployee TrainingAnnual security awareness training; phishing simulations; clear incident reporting process🟡 MediumComplianceContinuous compliance scanning mapped to ISO 27001, SOC 2, GDPR, or relevant frameworks for your industry🟡 Medium
https://youtu.be/NFVCpGQFjgA?si=D8cA2q2dPR9UBpWl
Real-World Case Study: Securing a SaaS Platform's Cloud Infrastructure
SoundCampaign, an entertainment software platform, approached Gart with overlapping challenges: AWS cost overruns and fragmented CI/CD processes that were creating security gaps between development and testing teams.
Our team implemented a multi-layered solution:
Automated CI/CD pipeline using Jenkins, Docker, and Kubernetes with integrated security gates at every stage
Strict RBAC policies ensuring least-privilege access for every role in the pipeline
Encrypted secrets management—removing credentials from source code and configuration files entirely
Continuous monitoring with real-time alerting on deployment anomalies and access pattern deviations
The result: significantly reduced security exposure, elimination of inter-team conflicts caused by unclear change ownership, and measurable improvement in deployment velocity. A more secure pipeline turned out to be a faster one, too.
Gart Solutions · Infrastructure Security
Is Your IT Infrastructure Secure Enough?
Our engineering team has audited and hardened infrastructure for companies across FinTech, Healthcare, SaaS, and E-commerce—identifying critical gaps before attackers do.
What we offer:
🔍
Infrastructure Security Audit
🛡️
Zero Trust Implementation
☁️
Cloud Security Posture Management
⚙️
Kubernetes Security Hardening
📋
Compliance Readiness (ISO 27001 · SOC 2)
🚨
Incident Response Planning
99.99%
Uptime Delivered
300+
Cloud Assets Audited
45%
Avg. Incident Reduction
12+
Years of Experience
Book a Free Security Consultation →
Best Practices for IT Infrastructure Security
Good security is not only about technology. It also needs clear rules, user awareness, and regular checks. Here are the basics:
Access controls and authentication: Use strong passwords, multi-factor authentication, and manage who has access to what. This limits the risk of someone breaking in.
Updates and patches: Keep software and hardware up to date. Fixing known issues quickly reduces the chance of attacks.
Monitoring and auditing: Watch network traffic for anything unusual. Tools like SIEM can help spot problems early and limit damage.
Data encryption: Encrypt sensitive data both when stored and when sent. This keeps information safe if it gets intercepted.
Firewalls and intrusion detection: Firewalls block unwanted traffic. IDS tools alert you when something suspicious happens. Together they protect the network.
Employee training: Most attacks start with human error. Regular training helps staff avoid phishing, scams, and careless mistakes.
Backups and disaster recovery: Back up data on schedule and test recovery plans often. This ensures you can restore critical systems if something goes wrong.
Our team of experts specializes in securing networks, servers, cloud environments, and more. Contact us today to fortify your defenses and ensure the resilience of your IT infrastructure.
Network Infrastructure
A strong network is key to protecting business systems. Here are the main steps:
Secure wireless networks: Use WPA2 or WPA3 encryption, change default passwords, and turn off SSID broadcasting. Add MAC filtering and always keep access points updated.
Use VPNs: VPNs create an encrypted tunnel for remote access. This keeps data private when employees connect over public networks.
Segment and isolate networks: Split the network into smaller parts based on roles or functions. This limits how far an attacker can move if one system is breached. Each segment should have its own rules and controls.
Monitor and log activity: Watch network traffic for unusual behavior. Keep logs of events to help with investigations and quick response to incidents.
Server Infrastructure
Servers run the core systems of any organization, so they need strong protection. Key practices include:
Harden server settings: Turn off unused services and ports, limit permissions, and set firewalls to only allow needed traffic. This reduces the attack surface.
Strong authentication and access control: Use unique, complex passwords and multi-factor authentication. Apply role-based access control (RBAC) so only the right people can reach sensitive resources.
Keep servers updated: Apply patches and firmware updates as soon as vendors release them. Staying current helps block known exploits and emerging threats.
Monitor logs and activity: Collect and review server logs to spot unusual activity or failed access attempts. Real-time monitoring helps catch and respond to threats faster.
Cloud Infrastructure Security
By choosing a reputable cloud service provider, implementing strong access controls and encryption, regularly monitoring and auditing cloud infrastructure, and backing up data stored in the cloud, organizations can enhance the security of their cloud infrastructure. These measures help protect sensitive data, maintain data availability, and ensure the overall integrity and resilience of cloud-based systems and applications.
Choosing a reputable and secure cloud service provider is a critical first step in ensuring cloud infrastructure security. Organizations should thoroughly assess potential providers based on their security certifications, compliance with industry standards, data protection measures, and track record for security incidents. Selecting a trusted provider with robust security practices helps establish a solid foundation for securing data and applications in the cloud.
Implementing strong access controls and encryption for data in the cloud is crucial to protect against unauthorized access and data breaches. This includes using strong passwords, multi-factor authentication, and role-based access control (RBAC) to ensure that only authorized users can access cloud resources. Additionally, sensitive data should be encrypted both in transit and at rest within the cloud environment to safeguard it from potential interception or compromise.
Regular monitoring and auditing of cloud infrastructure is vital to detect and respond to security incidents promptly. Organizations should implement tools and processes to monitor cloud resources, network traffic, and user activities for any suspicious or anomalous behavior. Regular audits should also be conducted to assess the effectiveness of security controls, identify potential vulnerabilities, and ensure compliance with security policies and regulations.
Backing up data stored in the cloud is essential for ensuring business continuity and data recoverability in the event of data loss, accidental deletion, or cloud service disruptions. Organizations should implement regular data backups and verify their integrity to mitigate the risk of permanent data loss. It is important to establish backup procedures and test data recovery processes to ensure that critical data can be restored effectively from the cloud backups.
Are you concerned about the security of your IT infrastructure? Protect your valuable digital assets by partnering with Gart, your trusted IT security provider.
Incident Response and Recovery
A well-prepared and practiced incident response capability enables timely response, minimizes the impact of incidents, and improves overall resilience in the face of evolving cyber threats.
Developing an Incident Response Plan
Developing an incident response plan is crucial for effectively handling security incidents in a structured and coordinated manner. The plan should outline the roles and responsibilities of the incident response team, the procedures for detecting and reporting incidents, and the steps to be taken to mitigate the impact and restore normal operations. It should also include communication protocols, escalation procedures, and coordination with external stakeholders, such as law enforcement or third-party vendors.
Detecting and Responding to Security Incidents
Prompt detection and response to security incidents are vital to minimize damage and prevent further compromise. Organizations should deploy security monitoring tools and establish real-time alerting mechanisms to identify potential security incidents. Upon detection, the incident response team should promptly assess the situation, contain the incident, gather evidence, and initiate appropriate remediation steps to mitigate the impact and restore security.
Conducting Post-Incident Analysis and Implementing Improvements
After the resolution of a security incident, conducting a post-incident analysis is crucial to understand the root causes, identify vulnerabilities, and learn from the incident. This analysis helps organizations identify weaknesses in their security posture, processes, or technologies, and implement improvements to prevent similar incidents in the future. Lessons learned should be documented and incorporated into updated incident response plans and security measures.
Testing Incident Response and Recovery Procedures
Regularly testing incident response and recovery procedures is essential to ensure their effectiveness and identify any gaps or shortcomings. Organizations should conduct simulated exercises, such as tabletop exercises or full-scale incident response drills, to assess the readiness and efficiency of their incident response teams and procedures. Testing helps uncover potential weaknesses, validate response plans, and refine incident management processes, ensuring a more robust and efficient response during real incidents.
IT Infrastructure Security
AspectDescriptionThreatsCommon threats include malware/ransomware, phishing/social engineering, insider threats, DDoS attacks, data breaches/theft, and vulnerabilities in software/hardware.Best PracticesImplementing strong access controls, regularly updating software/hardware, conducting security audits/risk assessments, encrypting sensitive data, using firewalls/intrusion detection systems, educating employees, and regularly backing up data/testing disaster recovery plans.Network SecuritySecuring wireless networks, implementing VPNs, network segmentation/isolation, and monitoring/logging network activities.Server SecurityHardening server configurations, implementing strong authentication/authorization, regularly updating software/firmware, and monitoring server logs/activities.Cloud SecurityChoosing a reputable cloud service provider, implementing strong access controls/encryption, monitoring/auditing cloud infrastructure, and backing up data stored in the cloud.Incident Response/RecoveryDeveloping an incident response plan, detecting/responding to security incidents, conducting post-incident analysis/implementing improvements, and testing incident response/recovery procedures.Emerging Trends/TechnologiesArtificial Intelligence (AI)/Machine Learning (ML) in security, Zero Trust security model, blockchain technology for secure transactions, and IoT security considerations.Here's a table summarizing key aspects of IT infrastructure security
Emerging Trends and Technologies in IT Infrastructure Security
Artificial Intelligence (AI) and Machine Learning (ML) in Security
Artificial Intelligence (AI) and Machine Learning (ML) are emerging trends in IT infrastructure security. These technologies can analyze vast amounts of data, detect patterns, and identify anomalies or potential security threats in real-time. AI and ML can be used for threat intelligence, behavior analytics, user authentication, and automated incident response. By leveraging AI and ML in security, organizations can enhance their ability to detect and respond to sophisticated cyber threats more effectively.
Zero Trust Security Model
The Zero Trust security model is gaining popularity as a comprehensive approach to IT infrastructure security. Unlike traditional perimeter-based security models, Zero Trust assumes that no user or device should be inherently trusted, regardless of their location or network. It emphasizes strong authentication, continuous monitoring, and strict access controls based on the principle of "never trust, always verify." Implementing a Zero Trust security model helps organizations reduce the risk of unauthorized access and improve overall security posture.
Blockchain Technology for Secure Transactions
Blockchain technology is revolutionizing secure transactions by providing a decentralized and tamper-resistant ledger. Its cryptographic mechanisms ensure the integrity and immutability of transaction data, reducing the reliance on intermediaries and enhancing trust. Blockchain can be used in various industries, such as finance, supply chain, and healthcare, to secure transactions, verify identities, and protect sensitive data. By leveraging blockchain technology, organizations can enhance security, transparency, and trust in their transactions.
Internet of Things (IoT) Security Considerations
As the Internet of Things (IoT) continues to proliferate, securing IoT devices and networks is becoming a critical challenge. IoT devices often have limited computing resources and may lack robust security features, making them vulnerable to exploitation. Organizations need to consider implementing strong authentication, encryption, and access controls for IoT devices. They should also ensure that IoT networks are separate from critical infrastructure networks to mitigate potential risks. Proactive monitoring, patch management, and regular updates are crucial to address IoT security vulnerabilities and protect against potential IoT-related threats.
These advancements enable organizations to proactively address evolving threats, enhance data protection, and improve overall resilience in the face of a dynamic and complex cybersecurity landscape.
Supercharge your IT landscape with our Infrastructure Consulting! We specialize in efficiency, security, and tailored solutions. Contact us today for a consultation – your technology transformation starts here.
Fedir Kompaniiets
Co-founder & CEO, Gart Solutions · Cloud Architect & DevOps Consultant
Fedir is a technology enthusiast with over a decade of diverse industry experience. He co-founded Gart Solutions to address complex tech challenges related to Digital Transformation, helping businesses focus on what matters most — scaling. Fedir is committed to driving sustainable IT transformation, helping SMBs innovate, plan future growth, and navigate the "tech madness" through expert DevOps and Cloud managed services. Connect on LinkedIn.

Infrastructure scalability is no longer a luxury — it's the architectural foundation that separates businesses that survive growth from those that collapse under it. This guide covers everything from fundamental scaling concepts to modern auto-scaling patterns, hybrid strategies, and real-world decision frameworks used by engineering teams at scale.
What Is Infrastructure Scalability?
Infrastructure scalability is the capacity of an IT system to handle increasing workloads by adding resources — without requiring a fundamental redesign. A scalable infrastructure maintains performance, reliability, and cost-efficiency as demand grows, whether that growth is gradual or sudden.
Scalability is often confused with related concepts. Understanding the distinctions matters for architectural decision-making:
ConceptDefinitionKey DifferenceScalabilityAbility to handle growing workload by adding resourcesManual or planned expansionElasticityAutomatic, real-time scaling up and down based on demandDynamic, reactive to load changesAvailabilitySystem uptime and accessibility under normal and abnormal conditionsReliability focus, not capacityPerformanceSpeed and efficiency of a specific workload at a given momentMeasured now, not under future loadResilienceAbility to recover from failures quicklyPost-failure recovery, not capacity growthWhat Is Infrastructure Scalability?
Usually, scaling does not involve rewriting the code, but either adding servers or increasing the resources of the existing one. According to this type, vertical and horizontal scaling are distinguished.
💡 Key InsightEven a company that isn't growing still faces increasing infrastructure demands over time. Data accumulates, systems become more complex, and technical debt compounds — making infrastructure scalability planning essential regardless of business growth trajectory.
20×
Hardware cost reduction possible with horizontal scaling vs. single high-end server
99.99%
Uptime achievable with distributed horizontal architecture and proper fault tolerance
40–65%
Typical infrastructure cost reduction from auto-scaling and rightsizing
Vertical Scaling (Scale Up): Deep Dive
Vertical scaling — also called scaling up — means increasing the capacity of a single existing server: adding more CPU cores, RAM, faster storage, or a more powerful GPU. The machine becomes more powerful, but it remains one machine.
Architecture Patterns
Vertical Scaling (Scale Up)
Before
🖥️
Standard Server
4 vCPU / 16 GB
UPGRADE
After
🚀
High-End Server
32 vCPU / 256 GB
Result: Same machine, significantly more resources. No distribution complexity, but a hard ceiling exists.
Advantages of Vertical Scaling
No code changes required. Applications don't need to be redesigned for distributed execution. The upgrade is transparent at the software level.
Operational simplicity. A single server environment is easier to manage, monitor, and debug than a distributed cluster of nodes.
Lower latency for tightly coupled workloads. Intra-process communication on one machine is dramatically faster than inter-node network calls.
Familiar tooling. Teams experienced in single-server environments can scale up without new infrastructure tooling or orchestration skills.
Immediate performance gain. Adding RAM or CPU cores takes effect upon restart — no migration, reconfiguration, or code deployment required.
Limitations of Vertical Scaling
Hard ceiling on capacity. Every server has a physical maximum. Eventually there is no larger instance to upgrade to, forcing a disruptive migration.
Single point of failure. If the server goes down, the entire application goes with it. No horizontal redundancy means downtime equals total outage.
Expensive at high tiers. The highest-spec servers command enormous price premiums. The cost-per-unit-of-compute rises sharply as you move up the hardware tier.
Downtime during upgrades. Physical or hypervisor-level resource additions often require a maintenance window, even if brief.
⚠️ Common MistakeMany teams choose vertical scaling as the default response to performance problems because it feels simpler. But repeatedly scaling up without addressing architectural inefficiencies leads to escalating costs and increasing migration risk as hardware tiers are exhausted.
When Vertical Scaling Is the Right Choice
Vertical scaling delivers the most value in specific scenarios. It is not inherently inferior to horizontal scaling — for the right workload, it is precisely correct:
Scale Up
Monolithic Legacy Applications
Applications with deep internal state dependencies or a tightly coupled codebase that cannot be easily distributed across nodes.
Scale Up
High-Frequency Trading Platforms
Latency-sensitive systems where microseconds matter and inter-node network latency would violate SLAs. A single powerful machine is optimal.
Scale Up
In-Memory Databases
Redis, Memcached, or in-memory OLAP databases benefit enormously from large RAM configurations. Adding RAM scales capacity linearly and immediately.
Scale Up
Predictable, Bounded Workloads
Applications with stable, predictable load that will not exceed known limits within the infrastructure lifecycle. Simpler and cheaper than distributed overhead.
Horizontal Scaling (Scale Out): Deep Dive
Horizontal scaling — also called scaling out — means adding more servers (nodes) to distribute the workload. Instead of one increasingly powerful machine, you have many smaller, cooperating machines with load distributed across them.
Scalability Patterns
Horizontal Scaling (Scale Out)
Traffic Manager
⚖️
Load Balancer
🖥️
Node 1
4 vCPU / 16 GB
🖥️
Node 2
4 vCPU / 16 GB
🖥️
Node 3
4 vCPU / 16 GB
➕
Node N
On Demand
Result: Traffic is distributed. Any node can fail without total outage. Add more nodes as demand grows — theoretically without limit.
Advantages of Horizontal Scaling
Theoretically unlimited capacity. Add nodes indefinitely as demand grows. No hard ceiling on the total capacity of the cluster.
Fault tolerance & high availability. If one node fails, the load redistributes to remaining nodes. No single point of failure exists by design.
Cost-efficient commodity hardware. Many mid-tier servers cost a fraction of an equivalent high-spec single server, often reducing hardware costs by up to 20×.
Zero-downtime scaling. Add or remove nodes while the application continues serving traffic. No maintenance windows required for capacity changes.
Geographic distribution. Nodes can be placed in multiple regions, reducing latency for global users and satisfying data residency requirements.
Enables auto-scaling. Horizontal architectures are the foundation for dynamic, demand-driven auto-scaling in cloud environments.
Challenges of Horizontal Scaling
Application must support distribution. Stateful applications storing data on individual nodes require significant rearchitecting before they can scale horizontally.
Increased operational complexity. Managing clusters, load balancers, service discovery, inter-node communication, and distributed tracing requires dedicated tooling and expertise.
Data consistency challenges. Maintaining consistency across distributed nodes requires careful design — particularly for databases and shared state.
Network overhead. Inter-node calls add latency compared to in-process function calls. This is acceptable for most workloads but problematic for ultra-low-latency requirements.
When Horizontal Scaling Is the Right Choice
Scale Out
SaaS Applications with Variable Load
Web apps and APIs experiencing unpredictable or seasonal demand spikes. Auto-scaling adds nodes during peaks and removes them during troughs.
Scale Out
Microservices Architectures
Each service can be scaled independently based on its own demand profile — eliminating the waste of scaling the entire application for bottlenecks in one component.
Scale Out
Big Data Processing Pipelines
Distributed computing frameworks like Apache Spark or Hadoop are purpose-built for horizontal scaling, splitting large jobs across many worker nodes in parallel.
Scale Out
Content Delivery Networks
CDNs distribute content to edge servers globally. Adding nodes in new regions reduces latency for regional users and increases total throughput capacity.
Head-to-Head Comparison: Horizontal vs. Vertical Scaling
DimensionVertical Scaling (Scale Up)Horizontal Scaling (Scale Out)How it worksIncrease resources on existing serverAdd more servers to the poolCapacity ceilingHard ceiling (max hardware spec)Theoretically unlimitedFault toleranceLow — single point of failureHigh — redundant nodesDowntime riskPossible during upgradesMinimal — nodes added liveImplementation complexityLow — no code changes neededHigh — requires distributed architectureCost at scaleExpensive at high tiersCost-efficient with commodity hardwareAuto-scaling supportLimitedNative in cloud environmentsBest forMonolithic apps, low-latency, legacy systemsDistributed apps, microservices, variable loadData consistencySimple — single data storeComplex — requires distributed consistency patternsGeographic distributionNot possible by designNative support for multi-regionHorizontal vs. Vertical Scaling
Auto-Scaling: The Evolution of Infrastructure Scalability
Manual scaling — whether vertical or horizontal — requires human decisions and action. Auto-scaling removes the human from the loop, automatically adjusting infrastructure capacity based on real-time demand signals. It is the operationalization of horizontal scalability in cloud environments.
Modern infrastructure scalability strategies are built around three auto-scaling approaches:
1. Reactive Auto-Scaling
The most common form. The system monitors metrics (CPU utilization, memory, request queue depth, response time) and triggers scaling actions when thresholds are crossed. AWS Auto Scaling Groups, Azure Virtual Machine Scale Sets, and Kubernetes Horizontal Pod Autoscaler (HPA) all operate reactively.
Example
A web application scales from 3 to 12 pods when average CPU utilization across the cluster exceeds 70% for 2 consecutive minutes. When utilization drops below 30%, it scales back to 3 pods over a cooldown period.
2. Predictive Auto-Scaling
Machine learning models analyze historical load patterns to predict future demand and pre-provision resources ahead of anticipated traffic spikes. AWS Predictive Scaling uses this approach, training on your application's historical CloudWatch metrics.
Predictive scaling is particularly valuable for workloads with consistent patterns — e-commerce sites with known peak shopping hours, SaaS tools with business-hours usage patterns, or media platforms with event-driven traffic surges.
3. Scheduled Auto-Scaling
For completely predictable load patterns, scheduled scaling sets specific capacity values at specific times. A company that knows from experience that traffic triples at 9 AM UTC every weekday can pre-scale at 8:45 AM — eliminating the cold-start lag of reactive scaling.
Kubernetes and Container-Native Scalability
Kubernetes has become the de facto infrastructure scalability platform for containerized workloads. It provides three complementary scaling mechanisms that work together:
Horizontal Pod Autoscaler (HPA): Scales the number of pod replicas based on CPU, memory, or custom metrics. This is horizontal scaling at the application layer.
Vertical Pod Autoscaler (VPA): Adjusts CPU and memory requests/limits for containers based on historical usage. This is vertical scaling at the container layer.
Cluster Autoscaler: Adds or removes worker nodes from the cluster itself based on pod scheduling pressure. This is horizontal scaling at the infrastructure layer.
Kubernetes Scalability Architecture
A production-grade Kubernetes deployment combining all three autoscalers achieves both vertical efficiency (VPA right-sizes containers) and horizontal resilience (HPA + Cluster Autoscaler handle demand spikes) — representing the state of the art in modern infrastructure scalability.
Hybrid Scaling: The Production Reality
Real-world infrastructure scalability is rarely purely horizontal or purely vertical. Most mature production architectures combine both approaches, applying the right strategy at each layer of the stack:
Stack LayerCommon Scaling ApproachRationaleWeb/API tierHorizontal (auto-scaling)Stateless; auto-scaling trivially adds/removes instancesApplication logicHorizontal (microservices)Independent services scale based on individual demandPrimary databaseVertical first, then read replicasWrite path benefits from powerful single instance; read scaling via replicasCache layerVertical (larger RAM instances)In-memory cache performance scales directly with RAMMessage queuesHorizontal (partitioning)Kafka/RabbitMQ throughput scales by adding partitions/consumersObject storageHorizontal (managed service)S3/Azure Blob scales infinitely; abstracted by providerBatch processingHorizontal (worker pools)Jobs parallelized across many workers; ephemeral scaling idealHybrid Scaling: The Production Reality
"The question is never 'which scaling approach is better?' — it's 'which scaling approach is right for this workload, at this tier, at this stage of growth?' Mature infrastructure scalability requires architectural nuance, not dogma." — Fedir Kompaniiets, Co-founder, Gart Solutions
Infrastructure Scalability Decision Framework
The right scaling strategy is not a matter of preference — it follows from the specific characteristics of your workload, team, and growth trajectory. Use this decision framework before committing to a scaling approach:
5-Question Scalability Decision Framework
Is the workload stateful or stateless?Stateless → horizontal scaling is straightforward. Stateful → evaluate distributed state management complexity before choosing horizontal, or favor vertical for simplicity.
Is demand predictable or variable?Predictable & bounded → vertical scaling may be sufficient and more cost-effective. Variable or spiky → horizontal scaling with auto-scaling is essential to avoid over-provisioning.
What are the latency requirements?Ultra-low latency (<1ms) → vertical scaling or co-located horizontal nodes. Standard web latency → horizontal scaling with load balancing works well.
What is the fault tolerance requirement?Mission-critical, zero downtime → horizontal scaling with redundancy is mandatory. Scheduled maintenance acceptable → vertical scaling may be viable.
What is the growth trajectory?Limited, known growth → vertical scaling handles this cleanly. Rapid or unbounded growth → horizontal scaling prevents the escalating cost and disruption of repeated hardware upgrades.
Industry-Specific Scalability Patterns
E-Commerce
E-commerce platforms face the classic variable load problem: normal traffic during weekdays, massive spikes during sales events and holidays. The optimal infrastructure scalability pattern is horizontal for the web/application tier with reactive auto-scaling, combined with vertical for the primary transactional database, supplemented by read replicas for product catalog queries.
Financial Services
Payment processing and trading platforms have extreme reliability and latency requirements. vertical scaling with premium hardware for the critical transaction path, horizontal for fraud detection microservices and reporting workloads, with active-active geographic redundancy for business continuity.
Healthcare Technology
Healthcare platforms combine predictable baseline load (scheduled appointments, EHR access) with unpredictable spikes (emergency systems). Hybrid approach: vertically scaled core clinical databases (consistency and latency critical), horizontally scaled patient-facing APIs, with strict data sovereignty controls limiting geographic distribution options.
SaaS Platforms
Multi-tenant SaaS products are the native home of horizontal scaling. Tenant workloads are isolated, stateless application tiers scale out during business hours, and per-tenant database strategies (shared vs. dedicated) allow granular infrastructure scalability at the data layer.
Infrastructure Scalability and Cost Optimization
Scaling decisions have direct financial consequences. An infrastructure that scales incorrectly — either under-provisioned or over-provisioned — causes measurable business harm. Building cost awareness into scalability strategy is non-negotiable.
The Over-Provisioning Problem
Traditional on-premise infrastructure forces teams to size for peak load. A server cluster capable of handling Black Friday traffic sits at 10–15% utilization for 350 days of the year. This is structural waste embedded in the infrastructure design.
Cloud-native horizontal scaling solves this: auto-scaling groups provision capacity on demand and deprovision it when the spike passes. Done well, this eliminates the peak-sizing premium entirely.
Reserved vs. On-Demand Capacity
A mature infrastructure scalability cost strategy combines three capacity tiers:
Reserved instances (1–3 year commitments) for predictable baseline load — delivering 30–60% savings vs. on-demand pricing.
On-demand instances for the variable load band between baseline and peak — paying only for what is used.
Spot/preemptible instances for fault-tolerant batch workloads and non-critical processing — up to 90% cost reduction vs. on-demand.
💰 Cost ImpactOrganizations that implement proper horizontal auto-scaling with a tiered capacity purchasing strategy consistently report 40–65% reductions in compute costs compared to statically provisioned vertical infrastructure sized for peak load.
FinOps and Scalability
Infrastructure scalability and cloud financial management (FinOps) are deeply interconnected. Scaling decisions that look technically correct can be financially destructive without proper cost governance:
Tag all scaling groups with team, service, and environment to attribute costs accurately
Set budget alerts that trigger at 80% of monthly targets — before costs spiral
Review scaling policies monthly; demand patterns evolve and policies become stale
Measure cost-per-unit-of-value (cost per transaction, cost per user) not just absolute spend
Run rightsizing analysis quarterly — vertical over-provisioning compounds silently
Modern Infrastructure Scalability: Serverless and Beyond
The horizontal/vertical dichotomy is evolving. A new generation of infrastructure abstractions removes scaling decisions from the operator entirely:
Serverless Computing
AWS Lambda, Azure Functions, and Google Cloud Run abstract infrastructure scaling completely. The platform scales from zero to thousands of concurrent executions automatically. The developer writes functions; the cloud manages provisioning. This is the logical endpoint of horizontal scaling taken to its extreme — infinite theoretical scale, zero operational overhead for capacity management.
The tradeoff: cold starts, execution time limits, and architectural constraints make serverless unsuitable for long-running, stateful, or latency-critical workloads. It is optimal for event-driven, short-duration, stateless functions.
Database Scalability Patterns
Databases are traditionally the hardest layer to scale horizontally. Modern approaches include:
Read replicas: Horizontal read scaling — offload read queries to replicas while writes hit the primary instance.
Sharding: Partition data across multiple database nodes based on a shard key. Enables horizontal scaling of writes but adds application-level complexity.
NewSQL databases (CockroachDB, PlanetScale, Vitess): Combine SQL semantics with distributed horizontal scalability — the best of both worlds for transactional workloads.
CQRS + Event Sourcing: Architectural patterns that separate read and write models, enabling each to scale independently and asymmetrically.
Infrastructure Scalability in Kubernetes
Kubernetes has become the standard runtime for horizontally scalable workloads. Key scalability capabilities include:
Horizontal Pod Autoscaler
Vertical Pod Autoscaler
Cluster Autoscaler
KEDA (Event-Driven Autoscaling)
Pod Disruption Budgets
Node Affinity Rules
Topology Spread Constraints
Resource Quotas
KEDA (Kubernetes Event-Driven Autoscaling) extends HPA to scale based on external event sources — queue depth in SQS, topics in Kafka, or custom metrics from Prometheus. This enables true demand-driven scalability beyond CPU/memory thresholds.
Choosing the Right Infrastructure Scalability Strategy
The decision between horizontal and vertical scaling — or a hybrid approach — should be based on a systematic assessment of your workload, not intuition or convention. The right answer varies by application, by layer, by growth stage, and by team capability.
Start Small, Monitor, Then Scale
The single most valuable infrastructure scalability practice is instrumentation before scaling decisions. You cannot optimize what you cannot measure. Before choosing how to scale, establish:
Baseline performance metrics under normal load (p50, p95, p99 latencies)
Resource utilization patterns over time (CPU, memory, disk I/O, network)
Identified bottlenecks — is performance limited by compute, memory, I/O, or network?
User-facing SLOs and how current headroom compares to them
This data transforms scaling from guesswork into an evidence-based engineering decision.
Scalability Is an Architecture Concern, Not an Operations Reaction
The most expensive infrastructure scalability scenarios are those that require urgent reactive decisions under pressure. Teams that build scalability thinking into their architecture from the start — designing for statelessness, separating concerns, building in observability — avoid the costly, risky emergency retrofits that plague systems designed without growth in mind.
Best Practices Summary
Design stateless where possible — it unlocks horizontal scalability. Scale databases last, and carefully — data layer scaling is hardest. Combine vertical baseline with horizontal peak handling — hybrid architectures are the production norm. Automate scaling decisions — human reaction time is too slow for modern traffic patterns. Monitor cost alongside performance — scalability without financial governance is waste.
How Gart Can Help You with Cloud Scalability
Ultimately, the determining factors are your cloud needs and cost structure. Without the ability to predict the true aspects of these components, each business can fall into the trap of choosing the wrong scaling strategy for them. Therefore, cost assessment should be a priority. Additionally, optimizing cloud costs remains a complex task regardless of which scaling system you choose.
Here are some ways Gart can help you with cloud scalability:
Assess your cloud needs and cost structure: We can help you understand your current cloud usage and identify areas where you can optimize your costs.
Develop a cloud scaling strategy: We can help you choose the right scaling approach for your specific needs and budget.
Implement your cloud scaling strategy: We can help you implement your chosen scaling strategy and provide ongoing support to ensure that it meets your needs.
Optimize your cloud costs: We can help you identify and implement cost-saving measures to reduce your cloud bill.
Gart has a team of experienced cloud experts who can help you with all aspects of cloud scalability. We have a proven track record of helping businesses optimize their cloud costs and improve their cloud performance.
Contact Gart today to learn more about how we can help you with cloud scalability.
We look forward to hearing from you!
Fedir Kompaniiets
Co-founder & CEO, Gart Solutions · Cloud Architect & DevOps Consultant
Fedir is a technology enthusiast with over a decade of diverse industry experience. He co-founded Gart Solutions to address complex tech challenges related to Digital Transformation, helping businesses focus on what matters most — scaling. Fedir is committed to driving sustainable IT transformation, helping SMBs innovate, plan future growth, and navigate the "tech madness" through expert DevOps and Cloud managed services. Connect on LinkedIn.

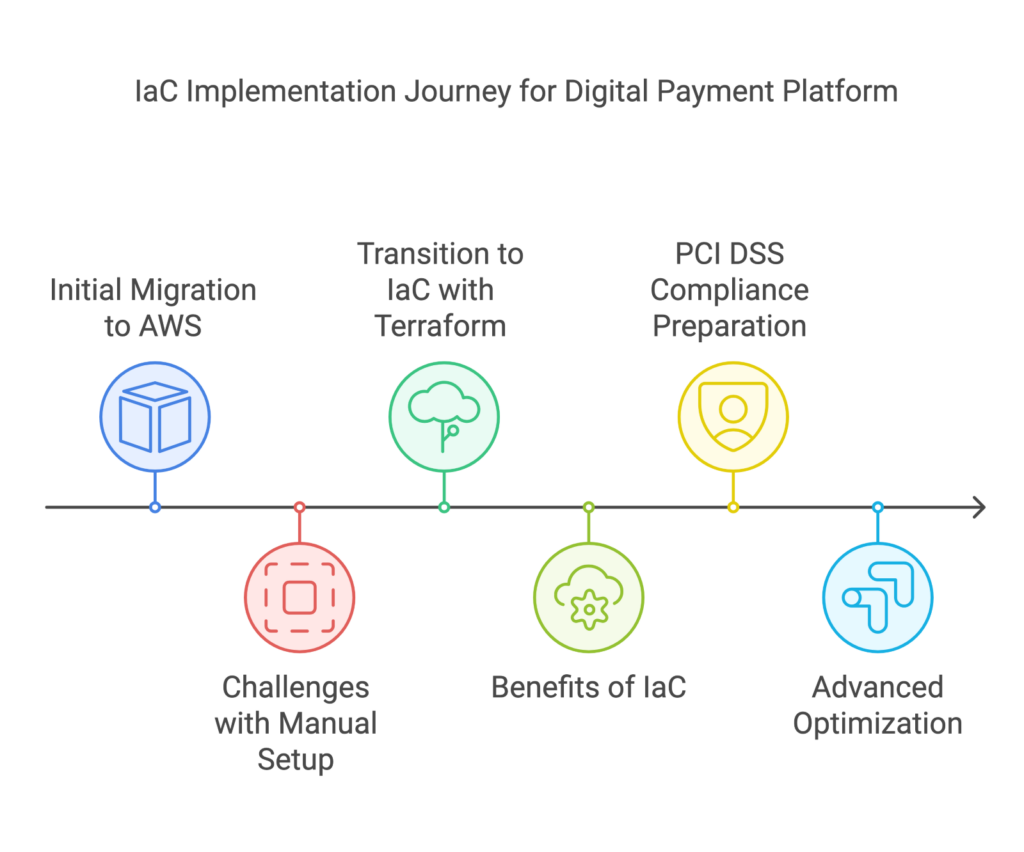
By treating infrastructure as software code, IaC empowers teams to leverage the benefits of version control, automation, and repeatability in their cloud deployments.
This article explores the key concepts and benefits of IaC, shedding light on popular tools such as Terraform, Ansible, SaltStack, and Google Cloud Deployment Manager. We'll delve into their features, strengths, and use cases, providing insights into how they enable developers and operations teams to streamline their infrastructure management processes.
IaC Tools Comparison Table
IaC ToolDescriptionSupported Cloud ProvidersTerraformOpen-source tool for infrastructure provisioningAWS, Azure, GCP, and moreAnsibleConfiguration management and automation platformAWS, Azure, GCP, and moreSaltStackHigh-speed automation and orchestration frameworkAWS, Azure, GCP, and morePuppetDeclarative language-based configuration managementAWS, Azure, GCP, and moreChefInfrastructure automation frameworkAWS, Azure, GCP, and moreCloudFormationAWS-specific IaC tool for provisioning AWS resourcesAmazon Web Services (AWS)Google Cloud Deployment ManagerInfrastructure management tool for Google Cloud PlatformGoogle Cloud Platform (GCP)Azure Resource ManagerAzure-native tool for deploying and managing resourcesMicrosoft AzureOpenStack HeatOrchestration engine for managing resources in OpenStackOpenStackInfrastructure as a Code Tools Table
Exploring the Landscape of IaC Tools
The IaC paradigm is widely embraced in modern software development, offering a range of tools for deployment, configuration management, virtualization, and orchestration. Prominent containerization and orchestration tools like Docker and Kubernetes employ YAML to express the desired end state. HashiCorp Packer is another tool that leverages JSON templates and variables for creating system snapshots.
The most popular configuration management tools, namely Ansible, Chef, and Puppet, adopt the IaC approach to define the desired state of the servers under their management.
Ansible functions by bootstrapping servers and orchestrating them based on predefined playbooks. These playbooks, written in YAML, outline the operations Ansible will execute and the targeted resources it will operate on. These operations can include starting services, installing packages via the system's package manager, or executing custom bash commands.
Both Chef and Puppet operate through central servers that issue instructions for orchestrating managed servers. Agent software needs to be installed on the managed servers. While Chef employs Ruby to describe resources, Puppet has its own declarative language.
Terraform seamlessly integrates with other IaC tools and DevOps systems, excelling in provisioning infrastructure resources rather than software installation and initial server configuration.
Unlike configuration management tools like Ansible and Chef, Terraform is not designed for installing software on target resources or scheduling tasks. Instead, Terraform utilizes providers to interact with supported resources.
Terraform can operate on a single machine without the need for a master or managed servers, unlike some other tools. It does not actively monitor the actual state of resources and automatically reapply configurations. Its primary focus is on orchestration. Typically, the workflow involves provisioning resources with Terraform and using a configuration management tool for further customization if necessary.
For Chef, Terraform provides a built-in provider that configures the client on the orchestrated remote resources. This allows for automatic addition of all orchestrated servers to the master server and further customization using Chef cookbooks (Chef's infrastructure declarations).
Optimize your infrastructure management with our DevOps expertise. Harness the power of IaC tools for streamlined provisioning, configuration, and orchestration. Scale efficiently and achieve seamless deployments. Contact us now.
Popular Infrastructure as Code Tools
Terraform
Terraform, introduced by HashiCorp in 2014, is an open-source Infrastructure as Code (IaC) solution. It operates based on a declarative approach to managing infrastructure, allowing you to define the desired end state of your infrastructure in a configuration file. Terraform then works to bring the infrastructure to that desired state. This configuration is applied using the PUSH method. Written in the Go programming language, Terraform incorporates its own language known as HashiCorp Configuration Language (HCL), which is used for writing configuration files that automate infrastructure management tasks.
Download: https://github.com/hashicorp/terraform
Terraform operates by analyzing the infrastructure code provided and constructing a graph that represents the resources and their relationships. This graph is then compared with the cached state of resources in the cloud. Based on this comparison, Terraform generates an execution plan that outlines the necessary changes to be applied to the cloud in order to achieve the desired state, including the order in which these changes should be made.
Within Terraform, there are two primary components: providers and provisioners. Providers are responsible for interacting with cloud service providers, handling the creation, management, and deletion of resources. On the other hand, provisioners are used to execute specific actions on the remote resources created or on the local machine where the code is being processed.
Terraform offers support for managing fundamental components of various cloud providers, such as compute instances, load balancers, storage, and DNS records. Additionally, Terraform's extensibility allows for the incorporation of new providers and provisioners.
In the realm of Infrastructure as Code (IaC), Terraform's primary role is to ensure that the state of resources in the cloud aligns with the state expressed in the provided code. However, it's important to note that Terraform does not actively track deployed resources or monitor the ongoing bootstrapping of prepared compute instances. The subsequent section will delve into the distinctions between Terraform and other tools, as well as how they complement each other within the workflow.
Real-World Examples of Terraform Usage
Terraform has gained immense popularity across various industries due to its versatility and user-friendly nature. Here are a few real-world examples showcasing how Terraform is being utilized:
CI/CD Pipelines and Infrastructure for E-Health Platform
For our client, a development company specializing in Electronic Medical Records Software (EMRS) for government-based E-Health platforms and CRM systems in medical facilities, we leveraged Terraform to create the infrastructure using VMWare ESXi. This allowed us to harness the full capabilities of the local cloud provider, ensuring efficient and scalable deployments.
Implementation of Nomad Cluster for Massively Parallel Computing
Our client, S-Cube, is a software development company specializing in creating a product based on a waveform inversion algorithm for building Earth models. They sought to enhance their infrastructure by separating the software from the underlying infrastructure, allowing them to focus solely on application development without the burden of infrastructure management.
To assist S-Cube in achieving their goals, Gart Solutions stepped in and leveraged the latest cloud development techniques and technologies, including Terraform. By utilizing Terraform, Gart Solutions helped restructure the architecture of S-Cube's SaaS platform, making it more economically efficient and scalable.
The Gart Solutions team worked closely with S-Cube to develop a new approach that takes infrastructure management to the next level. By adopting Terraform, they were able to define their infrastructure as code, enabling easy provisioning and management of resources across cloud and on-premises environments. This approach offered S-Cube the flexibility to run their workloads in both containerized and non-containerized environments, adapting to their specific requirements.
Streamlining Presale Processes with ChatOps Automation
Our client, Beyond Risk, is a dynamic technology company specializing in enterprise risk management solutions. They faced several challenges related to environmental management, particularly in managing the existing environment architecture and infrastructure code conditions, which required significant effort.
To address these challenges, Gart implemented ChatOps Automation to streamline the presale processes. The implementation involved utilizing the Slack API to create an interactive flow, AWS Lambda for implementing the business logic, and GitHub Action + Terraform Cloud for infrastructure automation.
One significant improvement was the addition of a Notification step, which helped us track the success or failure of Terraform operations. This allowed us to stay informed about the status of infrastructure changes and take appropriate actions accordingly.
Unlock the full potential of your infrastructure with our DevOps expertise. Maximize scalability and achieve flawless deployments. Drop us a line right now!
AWS CloudFormation
AWS CloudFormation is a powerful Infrastructure as Code (IaC) tool provided by Amazon Web Services (AWS). It simplifies the provisioning and management of AWS resources through the use of declarative CloudFormation templates. Here are the key features and benefits of AWS CloudFormation, its declarative infrastructure management approach, its integration with other AWS services, and some real-world case studies showcasing its adoption.
Key Features and Advantages:
Infrastructure as Code: CloudFormation enables you to define and manage your infrastructure resources using templates written in JSON or YAML. This approach ensures consistent, repeatable, and version-controlled deployments of your infrastructure.
Automation and Orchestration: CloudFormation automates the provisioning and configuration of resources, ensuring that they are created, updated, or deleted in a controlled and predictable manner. It handles resource dependencies, allowing for the orchestration of complex infrastructure setups.
Infrastructure Consistency: With CloudFormation, you can define the desired state of your infrastructure and deploy it consistently across different environments. This reduces configuration drift and ensures uniformity in your infrastructure deployments.
Change Management: CloudFormation utilizes stacks to manage infrastructure changes. Stacks enable you to track and control updates to your infrastructure, ensuring that changes are applied consistently and minimizing the risk of errors.
Scalability and Flexibility: CloudFormation supports a wide range of AWS resource types and features. This allows you to provision and manage compute instances, databases, storage volumes, networking components, and more. It also offers flexibility through custom resources and supports parameterization for dynamic configurations.
Case studies showcasing CloudFormation adoption
Netflix leverages CloudFormation for managing their infrastructure deployments at scale. They use CloudFormation templates to provision resources, define configurations, and enable repeatable deployments across different regions and accounts.
Yelp utilizes CloudFormation to manage their AWS infrastructure. They use CloudFormation templates to provision and configure resources, enabling them to automate and simplify their infrastructure deployments.
Dow Jones, a global news and business information provider, utilizes CloudFormation for managing their AWS resources. They leverage CloudFormation to define and provision their infrastructure, enabling faster and more consistent deployments.
Ansible
Perhaps Ansible is the most well-known configuration management system used by DevOps engineers. This system is written in the Python programming language and uses a declarative markup language to describe configurations. It utilizes the PUSH method for automating software configuration and deployment.
What are the main differences between Ansible and Terraform? Ansible is a versatile automation tool that can be used to solve various tasks, while Terraform is a tool specifically designed for "infrastructure as code" tasks, which means transforming configuration files into functioning infrastructure.
Use cases highlighting Ansible's versatility
Configuration Management: Ansible is commonly used for configuration management, allowing you to define and enforce the desired configurations across multiple servers or network devices. It ensures consistency and simplifies the management of configuration drift.
Application Deployment: Ansible can automate the deployment of applications by orchestrating the installation, configuration, and updates of application components and their dependencies. This enables faster and more reliable application deployments.
Cloud Provisioning: Ansible integrates seamlessly with various cloud providers, enabling the provisioning and management of cloud resources. It allows you to define infrastructure in a cloud-agnostic way, making it easy to deploy and manage infrastructure across different cloud platforms.
Continuous Delivery: Ansible can be integrated into a continuous delivery pipeline to automate the deployment and testing of applications. It allows for efficient and repeatable deployments, reducing manual errors and accelerating the delivery of software updates.
Google Cloud Deployment Manager
Google Cloud Deployment Manager is a robust Infrastructure as Code (IaC) solution offered by Google Cloud Platform (GCP). It empowers users to define and manage their infrastructure resources using Deployment Manager templates, which facilitate automated and consistent provisioning and configuration.
By utilizing YAML or Jinja2-based templates, Deployment Manager enables the definition and configuration of infrastructure resources. These templates specify the desired state of resources, encompassing various GCP services, networks, virtual machines, storage, and more. Users can leverage templates to define properties, establish dependencies, and establish relationships between resources, facilitating the creation of intricate infrastructures.
Deployment Manager seamlessly integrates with a diverse range of GCP services and ecosystems, providing comprehensive resource management capabilities. It supports GCP's native services, including Compute Engine, Cloud Storage, Cloud SQL, Cloud Pub/Sub, among others, enabling users to effectively manage their entire infrastructure.
Puppet
Puppet is a widely adopted configuration management tool that helps automate the management and deployment of infrastructure resources. It provides a declarative language and a flexible framework for defining and enforcing desired system configurations across multiple servers and environments.
Puppet enables efficient and centralized management of infrastructure configurations, making it easier to maintain consistency and enforce desired states across a large number of servers. It automates repetitive tasks, such as software installations, package updates, file management, and service configurations, saving time and reducing manual errors.
Puppet operates using a client-server model, where Puppet agents (client nodes) communicate with a central Puppet server to retrieve configurations and apply them locally. The Puppet server acts as a repository for configurations and distributes them to the agents based on predefined rules.
Pulumi
Pulumi is a modern Infrastructure as Code (IaC) tool that enables users to define, deploy, and manage infrastructure resources using familiar programming languages. It combines the concepts of IaC with the power and flexibility of general-purpose programming languages to provide a seamless and intuitive infrastructure management experience.
Pulumi has a growing ecosystem of libraries and plugins, offering additional functionality and integrations with external tools and services. Users can leverage existing libraries and modules from their programming language ecosystems, enhancing the capabilities of their infrastructure code.
There are often situations where it is necessary to deploy an application simultaneously across multiple clouds, combine cloud infrastructure with a managed Kubernetes cluster, or anticipate future service migration. One possible solution for creating a universal configuration is to use the Pulumi project, which allows for deploying applications to various clouds (GCP, Amazon, Azure, AliCloud), Kubernetes, providers (such as Linode, Digital Ocean), virtual infrastructure management systems (OpenStack), and local Docker environments.
Pulumi integrates with popular CI/CD systems and Git repositories, allowing for the creation of infrastructure as code pipelines.
Users can automate the deployment and management of infrastructure resources as part of their overall software delivery process.
SaltStack
SaltStack is a powerful Infrastructure as Code (IaC) tool that automates the management and configuration of infrastructure resources at scale. It provides a comprehensive solution for orchestrating and managing infrastructure through a combination of remote execution, configuration management, and event-driven automation.
SaltStack enables remote execution across a large number of servers, allowing administrators to execute commands, run scripts, and perform tasks on multiple machines simultaneously. It provides a robust configuration management framework, allowing users to define desired states for infrastructure resources and ensure their continuous enforcement.
SaltStack is designed to handle massive infrastructures efficiently, making it suitable for organizations with complex and distributed environments.
The SaltStack solution stands out compared to others mentioned in this article. When creating SaltStack, the primary goal was to achieve high speed. To ensure high performance, the architecture of the solution is based on the interaction between the Salt-master server components and Salt-minion clients, which operate in push mode using Salt-SSH.
The project is developed in Python and is hosted in the repository at https://github.com/saltstack/salt.
The high speed is achieved through asynchronous task execution. The idea is that the Salt Master communicates with Salt Minions using a publish/subscribe model, where the master publishes a task and the minions receive and asynchronously execute it. They interact through a shared bus, where the master sends a single message specifying the criteria that minions must meet, and they start executing the task. The master simply waits for information from all sources, knowing how many minions to expect a response from. To some extent, this operates on a "fire and forget" principle.
In the event of the master going offline, the minion will still complete the assigned work, and upon the master's return, it will receive the results.
The interaction architecture can be quite complex, as illustrated in the vRealize Automation SaltStack Config diagram below.
When comparing SaltStack and Ansible, due to architectural differences, Ansible spends more time processing messages. However, unlike SaltStack's minions, which essentially act as agents, Ansible does not require agents to function. SaltStack is significantly easier to deploy compared to Ansible, which requires a series of configurations to be performed. SaltStack does not require extensive script writing for its operation, whereas Ansible is quite reliant on scripting for interacting with infrastructure.
Additionally, SaltStack can have multiple masters, so if one fails, control is not lost. Ansible, on the other hand, can have a secondary node in case of failure. Finally, SaltStack is supported by GitHub, while Ansible is supported by Red Hat.
SaltStack integrates seamlessly with cloud platforms, virtualization technologies, and infrastructure services.
It provides built-in modules and functions for interacting with popular cloud providers, making it easier to manage and provision resources in cloud environments.
SaltStack offers a highly extensible framework that allows users to create custom modules, states, and plugins to extend its functionality.
It has a vibrant community contributing to a rich ecosystem of Salt modules and extensions.
Chef
Chef is a widely recognized and powerful Infrastructure as Code (IaC) tool that automates the management and configuration of infrastructure resources. It provides a comprehensive framework for defining, deploying, and managing infrastructure across various platforms and environments.
Chef allows users to define infrastructure configurations as code, making it easier to manage and maintain consistent configurations across multiple servers and environments.
It uses a declarative language called Chef DSL (Domain-Specific Language) to define the desired state of resources and systems.
Chef Solo
Chef also offers a standalone mode called Chef Solo, which does not require a central Chef server.
Chef Solo allows for the local execution of cookbooks and recipes on individual systems without the need for a server-client setup.
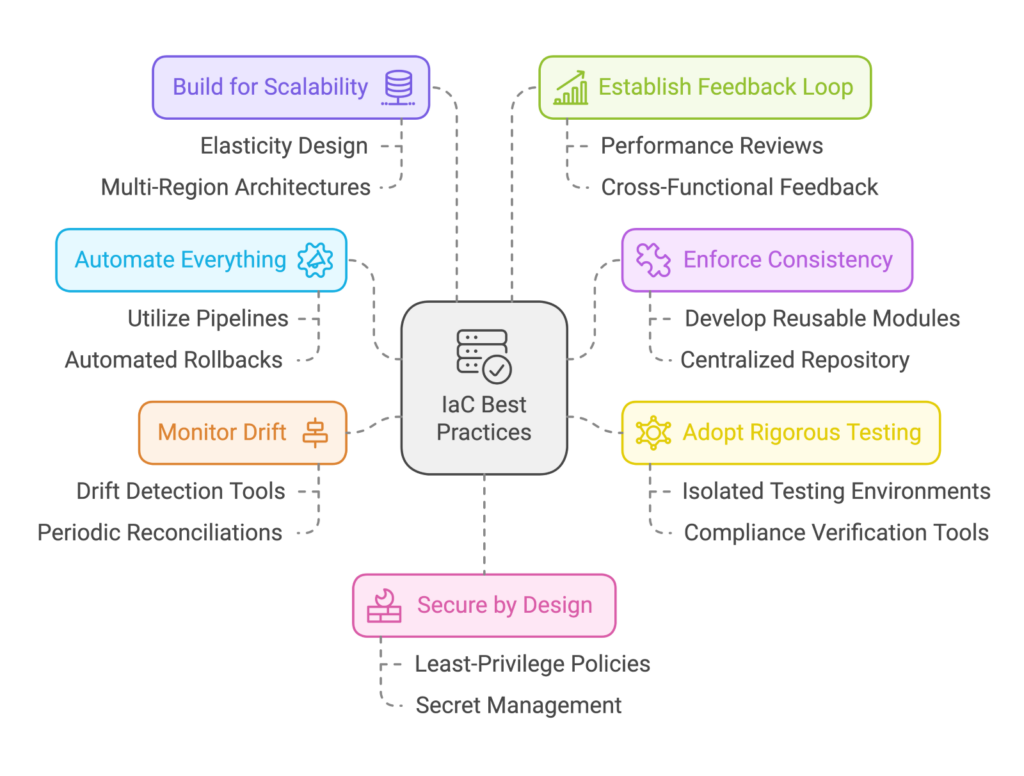
Benefits of Infrastructure as Code Tools
Infrastructure as Code (IaC) tools offer numerous benefits that contribute to efficient, scalable, and reliable infrastructure management.
IaC tools automate the provisioning, configuration, and management of infrastructure resources. This automation eliminates manual processes, reducing the potential for human error and increasing efficiency.
With IaC, infrastructure configurations are defined and deployed consistently across all environments. This ensures that infrastructure resources adhere to desired states and defined standards, leading to more reliable and predictable deployments.
IaC tools enable easy scalability by providing the ability to define infrastructure resources as code. Scaling up or down becomes a matter of modifying the code or configuration, allowing for rapid and flexible infrastructure adjustments to meet changing demands.
Infrastructure code can be stored and version-controlled using tools like Git. This enables collaboration among team members, tracking of changes, and easy rollbacks to previous configurations if needed.
Infrastructure code can be structured into reusable components, modules, or templates. These components can be shared across projects and environments, promoting code reusability, reducing duplication, and speeding up infrastructure deployment.
Infrastructure as Code tools automate the provisioning and deployment processes, significantly reducing the time required to set up and configure infrastructure resources. This leads to faster application deployment and delivery cycles.
Infrastructure as Code tools provide an audit trail of infrastructure changes, making it easier to track and document modifications. They also assist in achieving compliance by enforcing predefined policies and standards in infrastructure configurations.
Infrastructure code can be used to recreate and recover infrastructure quickly in the event of a disaster. By treating infrastructure as code, organizations can easily reproduce entire environments, reducing downtime and improving disaster recovery capabilities.
IaC tools abstract infrastructure configurations from specific cloud providers, allowing for portability across multiple cloud platforms. This flexibility enables organizations to leverage different cloud services based on specific requirements or to migrate between cloud providers easily.
Infrastructure as Code tools provide visibility into infrastructure resources and their associated costs. This visibility enables organizations to optimize resource allocation, identify unused or underutilized resources, and make informed decisions for cost optimization.
Considerations for Choosing an IaC Tool
When selecting an Infrastructure as Code (IaC) tool, it's essential to consider various factors to ensure it aligns with your specific requirements and goals.
Compatibility with Infrastructure and Environments
Determine if the IaC tool supports the infrastructure platforms and technologies you use, such as public clouds (AWS, Azure, GCP), private clouds, containers, or on-premises environments.
Check if the tool integrates well with existing infrastructure components and services you rely on, such as databases, load balancers, or networking configurations.
Supported Programming Languages
Consider the programming languages supported by the IaC tool. Choose a tool that offers support for languages that your team is familiar with and comfortable using.
Ensure that the tool's supported languages align with your organization's coding standards and preferences.
Learning Curve and Ease of Use
Evaluate the learning curve associated with the IaC tool. Consider the complexity of its syntax, the availability of documentation, tutorials, and community support.
Determine if the tool provides an intuitive and user-friendly interface or a command-line interface (CLI) that suits your team's preferences and skill sets.
Declarative or Imperative Approach
Decide whether you prefer a declarative or imperative approach to infrastructure management.
Declarative tools focus on defining the desired state of infrastructure resources, while imperative Infrastructure as Code tools allow more procedural control over infrastructure changes.
Consider which approach aligns better with your team's mindset and infrastructure management style.
Extensibility and Customization
Evaluate the extensibility and customization options provided by the IaC tool. Check if it allows the creation of custom modules, plugins, or extensions to meet specific requirements.
Consider the availability of a vibrant community and ecosystem around the tool, providing additional resources, libraries, and community-contributed content.
Collaboration and Version Control
Assess the tool's collaboration features and support for version control systems like Git.
Determine if it allows multiple team members to work simultaneously on infrastructure code, provides conflict resolution mechanisms, and supports code review processes.
Security and Compliance
Examine the tool's security features and its ability to meet security and compliance requirements.
Consider features like access controls, encryption, secrets management, and compliance auditing capabilities to ensure the tool aligns with your organization's security standards.
Community and Support
Evaluate the size and activity of the tool's community, as it can greatly impact the availability of resources, forums, and support.
Consider factors like the frequency of updates, bug fixes, and the responsiveness of the tool's maintainers to address issues or feature requests.
Cost and Licensing
Assess the licensing model of the IaC tool. Some Infrastructure as Code Tools may have open-source versions with community support, while others offer enterprise editions with additional features and support.
Consider the total cost of ownership, including licensing fees, training costs, infrastructure requirements, and ongoing maintenance.
Roadmap and Future Development
Research the tool's roadmap and future development plans to ensure its continued relevance and compatibility with evolving technologies and industry trends.
By considering these factors, you can select Infrastructure as Code Tools that best fits your organization's needs, infrastructure requirements, team capabilities, and long-term goals.