

- What Is Infrastructure Scalability?
- Vertical Scaling (Scale Up): Deep Dive
- Horizontal Scaling (Scale Out): Deep Dive
- When Horizontal Scaling Is the Right Choice
- Head-to-Head Comparison: Horizontal vs. Vertical Scaling
- Auto-Scaling: The Evolution of Infrastructure Scalability
- Hybrid Scaling: The Production Reality
- Infrastructure Scalability Decision Framework
- Industry-Specific Scalability Patterns
- Infrastructure Scalability and Cost Optimization
- Modern Infrastructure Scalability: Serverless and Beyond
- Choosing the Right Infrastructure Scalability Strategy
- Best Practices Summary
- How Gart Can Help You with Cloud Scalability
Infrastructure scalability is no longer a luxury — it’s the architectural foundation that separates businesses that survive growth from those that collapse under it. This guide covers everything from fundamental scaling concepts to modern auto-scaling patterns, hybrid strategies, and real-world decision frameworks used by engineering teams at scale.
What Is Infrastructure Scalability?
Infrastructure scalability is the capacity of an IT system to handle increasing workloads by adding resources — without requiring a fundamental redesign. A scalable infrastructure maintains performance, reliability, and cost-efficiency as demand grows, whether that growth is gradual or sudden.
Scalability is often confused with related concepts. Understanding the distinctions matters for architectural decision-making:
| Concept | Definition | Key Difference |
|---|---|---|
| Scalability | Ability to handle growing workload by adding resources | Manual or planned expansion |
| Elasticity | Automatic, real-time scaling up and down based on demand | Dynamic, reactive to load changes |
| Availability | System uptime and accessibility under normal and abnormal conditions | Reliability focus, not capacity |
| Performance | Speed and efficiency of a specific workload at a given moment | Measured now, not under future load |
| Resilience | Ability to recover from failures quickly | Post-failure recovery, not capacity growth |
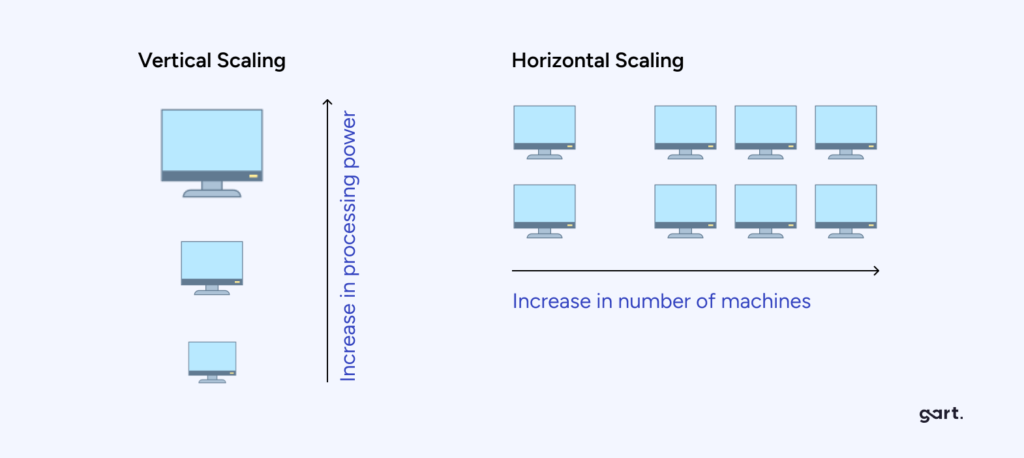
Usually, scaling does not involve rewriting the code, but either adding servers or increasing the resources of the existing one. According to this type, vertical and horizontal scaling are distinguished.
💡 Key Insight
Even a company that isn’t growing still faces increasing infrastructure demands over time. Data accumulates, systems become more complex, and technical debt compounds — making infrastructure scalability planning essential regardless of business growth trajectory.
Hardware cost reduction possible with horizontal scaling vs. single high-end server
Uptime achievable with distributed horizontal architecture and proper fault tolerance
Typical infrastructure cost reduction from auto-scaling and rightsizing
Vertical Scaling (Scale Up): Deep Dive
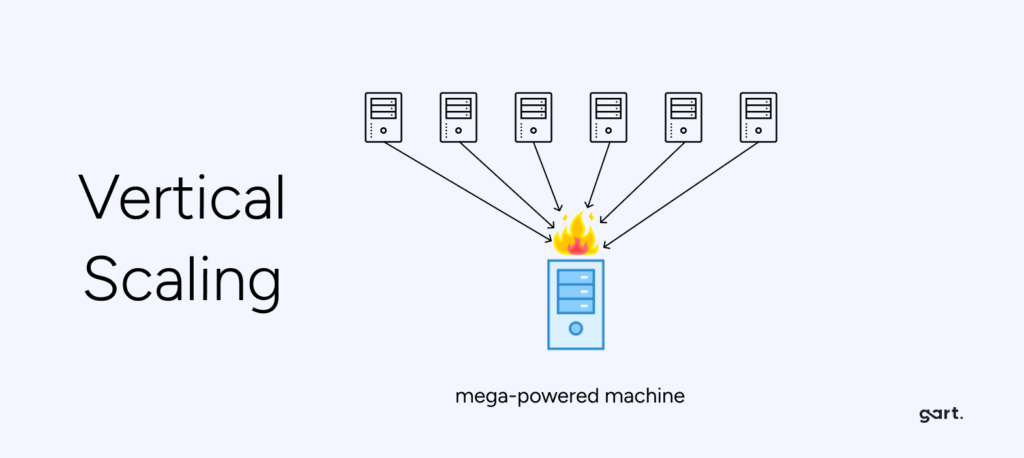
Vertical scaling — also called scaling up — means increasing the capacity of a single existing server: adding more CPU cores, RAM, faster storage, or a more powerful GPU. The machine becomes more powerful, but it remains one machine.
Vertical Scaling (Scale Up)
Advantages of Vertical Scaling
- No code changes required. Applications don’t need to be redesigned for distributed execution. The upgrade is transparent at the software level.
- Operational simplicity. A single server environment is easier to manage, monitor, and debug than a distributed cluster of nodes.
- Lower latency for tightly coupled workloads. Intra-process communication on one machine is dramatically faster than inter-node network calls.
- Familiar tooling. Teams experienced in single-server environments can scale up without new infrastructure tooling or orchestration skills.
- Immediate performance gain. Adding RAM or CPU cores takes effect upon restart — no migration, reconfiguration, or code deployment required.
Limitations of Vertical Scaling
- Hard ceiling on capacity. Every server has a physical maximum. Eventually there is no larger instance to upgrade to, forcing a disruptive migration.
- Single point of failure. If the server goes down, the entire application goes with it. No horizontal redundancy means downtime equals total outage.
- Expensive at high tiers. The highest-spec servers command enormous price premiums. The cost-per-unit-of-compute rises sharply as you move up the hardware tier.
- Downtime during upgrades. Physical or hypervisor-level resource additions often require a maintenance window, even if brief.
⚠️ Common Mistake
Many teams choose vertical scaling as the default response to performance problems because it feels simpler. But repeatedly scaling up without addressing architectural inefficiencies leads to escalating costs and increasing migration risk as hardware tiers are exhausted.
When Vertical Scaling Is the Right Choice
Vertical scaling delivers the most value in specific scenarios. It is not inherently inferior to horizontal scaling — for the right workload, it is precisely correct:
Monolithic Legacy Applications
Applications with deep internal state dependencies or a tightly coupled codebase that cannot be easily distributed across nodes.
High-Frequency Trading Platforms
Latency-sensitive systems where microseconds matter and inter-node network latency would violate SLAs. A single powerful machine is optimal.
In-Memory Databases
Redis, Memcached, or in-memory OLAP databases benefit enormously from large RAM configurations. Adding RAM scales capacity linearly and immediately.
Predictable, Bounded Workloads
Applications with stable, predictable load that will not exceed known limits within the infrastructure lifecycle. Simpler and cheaper than distributed overhead.
Horizontal Scaling (Scale Out): Deep Dive
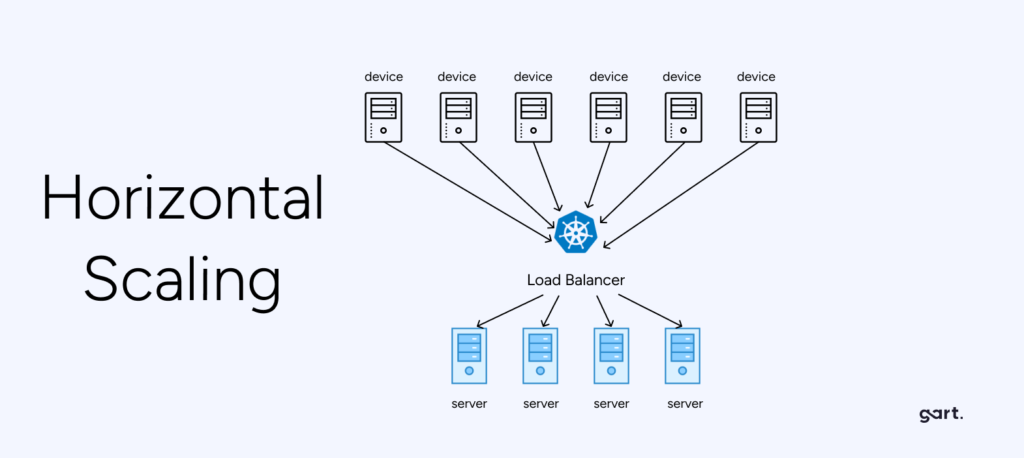
Horizontal scaling — also called scaling out — means adding more servers (nodes) to distribute the workload. Instead of one increasingly powerful machine, you have many smaller, cooperating machines with load distributed across them.
Horizontal Scaling (Scale Out)
Advantages of Horizontal Scaling
- Theoretically unlimited capacity. Add nodes indefinitely as demand grows. No hard ceiling on the total capacity of the cluster.
- Fault tolerance & high availability. If one node fails, the load redistributes to remaining nodes. No single point of failure exists by design.
- Cost-efficient commodity hardware. Many mid-tier servers cost a fraction of an equivalent high-spec single server, often reducing hardware costs by up to 20×.
- Zero-downtime scaling. Add or remove nodes while the application continues serving traffic. No maintenance windows required for capacity changes.
- Geographic distribution. Nodes can be placed in multiple regions, reducing latency for global users and satisfying data residency requirements.
- Enables auto-scaling. Horizontal architectures are the foundation for dynamic, demand-driven auto-scaling in cloud environments.
Challenges of Horizontal Scaling
- Application must support distribution. Stateful applications storing data on individual nodes require significant rearchitecting before they can scale horizontally.
- Increased operational complexity. Managing clusters, load balancers, service discovery, inter-node communication, and distributed tracing requires dedicated tooling and expertise.
- Data consistency challenges. Maintaining consistency across distributed nodes requires careful design — particularly for databases and shared state.
- Network overhead. Inter-node calls add latency compared to in-process function calls. This is acceptable for most workloads but problematic for ultra-low-latency requirements.
When Horizontal Scaling Is the Right Choice
SaaS Applications with Variable Load
Web apps and APIs experiencing unpredictable or seasonal demand spikes. Auto-scaling adds nodes during peaks and removes them during troughs.
Microservices Architectures
Each service can be scaled independently based on its own demand profile — eliminating the waste of scaling the entire application for bottlenecks in one component.
Big Data Processing Pipelines
Distributed computing frameworks like Apache Spark or Hadoop are purpose-built for horizontal scaling, splitting large jobs across many worker nodes in parallel.
Content Delivery Networks
CDNs distribute content to edge servers globally. Adding nodes in new regions reduces latency for regional users and increases total throughput capacity.
Head-to-Head Comparison: Horizontal vs. Vertical Scaling
| Dimension | Vertical Scaling (Scale Up) | Horizontal Scaling (Scale Out) |
|---|---|---|
| How it works | Increase resources on existing server | Add more servers to the pool |
| Capacity ceiling | Hard ceiling (max hardware spec) | Theoretically unlimited |
| Fault tolerance | Low — single point of failure | High — redundant nodes |
| Downtime risk | Possible during upgrades | Minimal — nodes added live |
| Implementation complexity | Low — no code changes needed | High — requires distributed architecture |
| Cost at scale | Expensive at high tiers | Cost-efficient with commodity hardware |
| Auto-scaling support | Limited | Native in cloud environments |
| Best for | Monolithic apps, low-latency, legacy systems | Distributed apps, microservices, variable load |
| Data consistency | Simple — single data store | Complex — requires distributed consistency patterns |
| Geographic distribution | Not possible by design | Native support for multi-region |
Auto-Scaling: The Evolution of Infrastructure Scalability
Manual scaling — whether vertical or horizontal — requires human decisions and action. Auto-scaling removes the human from the loop, automatically adjusting infrastructure capacity based on real-time demand signals. It is the operationalization of horizontal scalability in cloud environments.
Modern infrastructure scalability strategies are built around three auto-scaling approaches:
1. Reactive Auto-Scaling
The most common form. The system monitors metrics (CPU utilization, memory, request queue depth, response time) and triggers scaling actions when thresholds are crossed. AWS Auto Scaling Groups, Azure Virtual Machine Scale Sets, and Kubernetes Horizontal Pod Autoscaler (HPA) all operate reactively.
Example
A web application scales from 3 to 12 pods when average CPU utilization across the cluster exceeds 70% for 2 consecutive minutes. When utilization drops below 30%, it scales back to 3 pods over a cooldown period.
2. Predictive Auto-Scaling
Machine learning models analyze historical load patterns to predict future demand and pre-provision resources ahead of anticipated traffic spikes. AWS Predictive Scaling uses this approach, training on your application’s historical CloudWatch metrics.
Predictive scaling is particularly valuable for workloads with consistent patterns — e-commerce sites with known peak shopping hours, SaaS tools with business-hours usage patterns, or media platforms with event-driven traffic surges.
3. Scheduled Auto-Scaling
For completely predictable load patterns, scheduled scaling sets specific capacity values at specific times. A company that knows from experience that traffic triples at 9 AM UTC every weekday can pre-scale at 8:45 AM — eliminating the cold-start lag of reactive scaling.
Kubernetes and Container-Native Scalability
Kubernetes has become the de facto infrastructure scalability platform for containerized workloads. It provides three complementary scaling mechanisms that work together:
- Horizontal Pod Autoscaler (HPA): Scales the number of pod replicas based on CPU, memory, or custom metrics. This is horizontal scaling at the application layer.
- Vertical Pod Autoscaler (VPA): Adjusts CPU and memory requests/limits for containers based on historical usage. This is vertical scaling at the container layer.
- Cluster Autoscaler: Adds or removes worker nodes from the cluster itself based on pod scheduling pressure. This is horizontal scaling at the infrastructure layer.
Kubernetes Scalability Architecture
A production-grade Kubernetes deployment combining all three autoscalers achieves both vertical efficiency (VPA right-sizes containers) and horizontal resilience (HPA + Cluster Autoscaler handle demand spikes) — representing the state of the art in modern infrastructure scalability.
Hybrid Scaling: The Production Reality
Real-world infrastructure scalability is rarely purely horizontal or purely vertical. Most mature production architectures combine both approaches, applying the right strategy at each layer of the stack:
| Stack Layer | Common Scaling Approach | Rationale |
|---|---|---|
| Web/API tier | Horizontal (auto-scaling) | Stateless; auto-scaling trivially adds/removes instances |
| Application logic | Horizontal (microservices) | Independent services scale based on individual demand |
| Primary database | Vertical first, then read replicas | Write path benefits from powerful single instance; read scaling via replicas |
| Cache layer | Vertical (larger RAM instances) | In-memory cache performance scales directly with RAM |
| Message queues | Horizontal (partitioning) | Kafka/RabbitMQ throughput scales by adding partitions/consumers |
| Object storage | Horizontal (managed service) | S3/Azure Blob scales infinitely; abstracted by provider |
| Batch processing | Horizontal (worker pools) | Jobs parallelized across many workers; ephemeral scaling ideal |
“The question is never ‘which scaling approach is better?’ — it’s ‘which scaling approach is right for this workload, at this tier, at this stage of growth?’ Mature infrastructure scalability requires architectural nuance, not dogma.” — Fedir Kompaniiets, Co-founder, Gart Solutions
Infrastructure Scalability Decision Framework
The right scaling strategy is not a matter of preference — it follows from the specific characteristics of your workload, team, and growth trajectory. Use this decision framework before committing to a scaling approach:
5-Question Scalability Decision Framework
Is the workload stateful or stateless?
Stateless → horizontal scaling is straightforward. Stateful → evaluate distributed state management complexity before choosing horizontal, or favor vertical for simplicity.
Is demand predictable or variable?
Predictable & bounded → vertical scaling may be sufficient and more cost-effective. Variable or spiky → horizontal scaling with auto-scaling is essential to avoid over-provisioning.
What are the latency requirements?
Ultra-low latency (<1ms) → vertical scaling or co-located horizontal nodes. Standard web latency → horizontal scaling with load balancing works well.
What is the fault tolerance requirement?
Mission-critical, zero downtime → horizontal scaling with redundancy is mandatory. Scheduled maintenance acceptable → vertical scaling may be viable.
What is the growth trajectory?
Limited, known growth → vertical scaling handles this cleanly. Rapid or unbounded growth → horizontal scaling prevents the escalating cost and disruption of repeated hardware upgrades.
Industry-Specific Scalability Patterns
E-Commerce
E-commerce platforms face the classic variable load problem: normal traffic during weekdays, massive spikes during sales events and holidays. The optimal infrastructure scalability pattern is horizontal for the web/application tier with reactive auto-scaling, combined with vertical for the primary transactional database, supplemented by read replicas for product catalog queries.
Financial Services
Payment processing and trading platforms have extreme reliability and latency requirements. vertical scaling with premium hardware for the critical transaction path, horizontal for fraud detection microservices and reporting workloads, with active-active geographic redundancy for business continuity.
Healthcare Technology
Healthcare platforms combine predictable baseline load (scheduled appointments, EHR access) with unpredictable spikes (emergency systems). Hybrid approach: vertically scaled core clinical databases (consistency and latency critical), horizontally scaled patient-facing APIs, with strict data sovereignty controls limiting geographic distribution options.
SaaS Platforms
Multi-tenant SaaS products are the native home of horizontal scaling. Tenant workloads are isolated, stateless application tiers scale out during business hours, and per-tenant database strategies (shared vs. dedicated) allow granular infrastructure scalability at the data layer.
Infrastructure Scalability and Cost Optimization
Scaling decisions have direct financial consequences. An infrastructure that scales incorrectly — either under-provisioned or over-provisioned — causes measurable business harm. Building cost awareness into scalability strategy is non-negotiable.
The Over-Provisioning Problem
Traditional on-premise infrastructure forces teams to size for peak load. A server cluster capable of handling Black Friday traffic sits at 10–15% utilization for 350 days of the year. This is structural waste embedded in the infrastructure design.
Cloud-native horizontal scaling solves this: auto-scaling groups provision capacity on demand and deprovision it when the spike passes. Done well, this eliminates the peak-sizing premium entirely.
Reserved vs. On-Demand Capacity
A mature infrastructure scalability cost strategy combines three capacity tiers:
- Reserved instances (1–3 year commitments) for predictable baseline load — delivering 30–60% savings vs. on-demand pricing.
- On-demand instances for the variable load band between baseline and peak — paying only for what is used.
- Spot/preemptible instances for fault-tolerant batch workloads and non-critical processing — up to 90% cost reduction vs. on-demand.
💰 Cost Impact
Organizations that implement proper horizontal auto-scaling with a tiered capacity purchasing strategy consistently report 40–65% reductions in compute costs compared to statically provisioned vertical infrastructure sized for peak load.
FinOps and Scalability
Infrastructure scalability and cloud financial management (FinOps) are deeply interconnected. Scaling decisions that look technically correct can be financially destructive without proper cost governance:
- Tag all scaling groups with team, service, and environment to attribute costs accurately
- Set budget alerts that trigger at 80% of monthly targets — before costs spiral
- Review scaling policies monthly; demand patterns evolve and policies become stale
- Measure cost-per-unit-of-value (cost per transaction, cost per user) not just absolute spend
- Run rightsizing analysis quarterly — vertical over-provisioning compounds silently
Modern Infrastructure Scalability: Serverless and Beyond
The horizontal/vertical dichotomy is evolving. A new generation of infrastructure abstractions removes scaling decisions from the operator entirely:
Serverless Computing
AWS Lambda, Azure Functions, and Google Cloud Run abstract infrastructure scaling completely. The platform scales from zero to thousands of concurrent executions automatically. The developer writes functions; the cloud manages provisioning. This is the logical endpoint of horizontal scaling taken to its extreme — infinite theoretical scale, zero operational overhead for capacity management.
The tradeoff: cold starts, execution time limits, and architectural constraints make serverless unsuitable for long-running, stateful, or latency-critical workloads. It is optimal for event-driven, short-duration, stateless functions.
Database Scalability Patterns
Databases are traditionally the hardest layer to scale horizontally. Modern approaches include:
- Read replicas: Horizontal read scaling — offload read queries to replicas while writes hit the primary instance.
- Sharding: Partition data across multiple database nodes based on a shard key. Enables horizontal scaling of writes but adds application-level complexity.
- NewSQL databases (CockroachDB, PlanetScale, Vitess): Combine SQL semantics with distributed horizontal scalability — the best of both worlds for transactional workloads.
- CQRS + Event Sourcing: Architectural patterns that separate read and write models, enabling each to scale independently and asymmetrically.
Infrastructure Scalability in Kubernetes
Kubernetes has become the standard runtime for horizontally scalable workloads. Key scalability capabilities include:
- Horizontal Pod Autoscaler
- Vertical Pod Autoscaler
- Cluster Autoscaler
- KEDA (Event-Driven Autoscaling)
- Pod Disruption Budgets
- Node Affinity Rules
- Topology Spread Constraints
- Resource Quotas
KEDA (Kubernetes Event-Driven Autoscaling) extends HPA to scale based on external event sources — queue depth in SQS, topics in Kafka, or custom metrics from Prometheus. This enables true demand-driven scalability beyond CPU/memory thresholds.
Choosing the Right Infrastructure Scalability Strategy
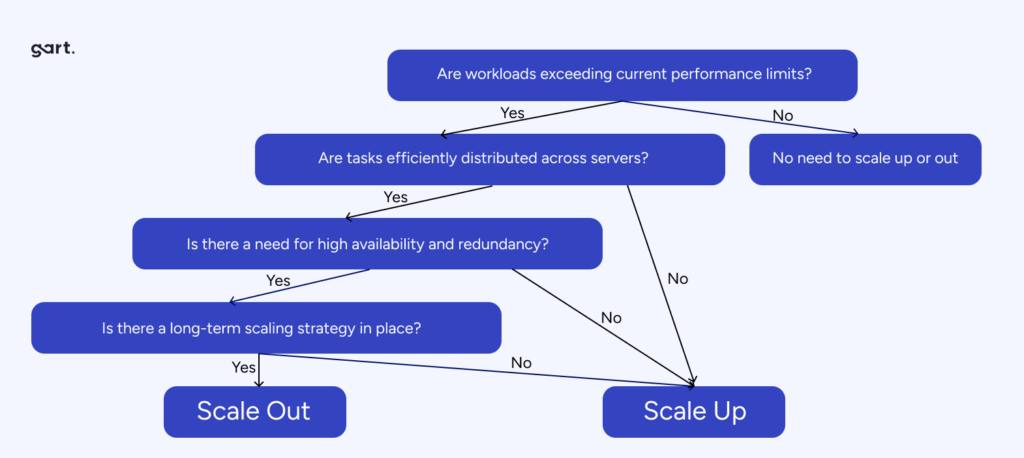
The decision between horizontal and vertical scaling — or a hybrid approach — should be based on a systematic assessment of your workload, not intuition or convention. The right answer varies by application, by layer, by growth stage, and by team capability.
Start Small, Monitor, Then Scale
The single most valuable infrastructure scalability practice is instrumentation before scaling decisions. You cannot optimize what you cannot measure. Before choosing how to scale, establish:
- Baseline performance metrics under normal load (p50, p95, p99 latencies)
- Resource utilization patterns over time (CPU, memory, disk I/O, network)
- Identified bottlenecks — is performance limited by compute, memory, I/O, or network?
- User-facing SLOs and how current headroom compares to them
This data transforms scaling from guesswork into an evidence-based engineering decision.
Scalability Is an Architecture Concern, Not an Operations Reaction
The most expensive infrastructure scalability scenarios are those that require urgent reactive decisions under pressure. Teams that build scalability thinking into their architecture from the start — designing for statelessness, separating concerns, building in observability — avoid the costly, risky emergency retrofits that plague systems designed without growth in mind.
Best Practices Summary
Design stateless where possible — it unlocks horizontal scalability. Scale databases last, and carefully — data layer scaling is hardest. Combine vertical baseline with horizontal peak handling — hybrid architectures are the production norm. Automate scaling decisions — human reaction time is too slow for modern traffic patterns. Monitor cost alongside performance — scalability without financial governance is waste.
How Gart Can Help You with Cloud Scalability
Ultimately, the determining factors are your cloud needs and cost structure. Without the ability to predict the true aspects of these components, each business can fall into the trap of choosing the wrong scaling strategy for them. Therefore, cost assessment should be a priority. Additionally, optimizing cloud costs remains a complex task regardless of which scaling system you choose.
Here are some ways Gart can help you with cloud scalability:
- Assess your cloud needs and cost structure: We can help you understand your current cloud usage and identify areas where you can optimize your costs.
- Develop a cloud scaling strategy: We can help you choose the right scaling approach for your specific needs and budget.
- Implement your cloud scaling strategy: We can help you implement your chosen scaling strategy and provide ongoing support to ensure that it meets your needs.
- Optimize your cloud costs: We can help you identify and implement cost-saving measures to reduce your cloud bill.
Gart has a team of experienced cloud experts who can help you with all aspects of cloud scalability. We have a proven track record of helping businesses optimize their cloud costs and improve their cloud performance.
Contact Gart today to learn more about how we can help you with cloud scalability.
We look forward to hearing from you!
See how we can help to overcome your challenges







