Cloud spending is accelerating faster than most organizations can manage it. According to Flexera's State of the Cloud report, 82% of enterprises identify cloud cost optimization as their top initiative — yet the average organization wastes 28% of its cloud budget. FinOps, the operating model that unifies engineering, finance, and operations around cloud financial accountability, is the most reliable framework for closing that gap.
At Gart Solutions, we have implemented FinOps practices across more than 50 cloud environments — from early-stage product companies to multi-cloud enterprise setups. In this guide, we share the frameworks we actually use, the KPIs that matter, the mistakes we see most often, and a realistic picture of what FinOps delivers in practice.
Key Takeaways
FinOps is not a tool — it is a cross-functional operating model connecting engineering, finance, and product.
Visibility always comes before optimization. You cannot optimize what you cannot see.
The biggest cloud cost wins come from rightsizing, Reserved Instances, and Kubernetes resource governance.
FinOps maturity follows three stages: Crawl, Walk, Run. Most organizations take 3–6 months to reach the Walk phase.
Tagging governance is the single most underestimated precondition for any cost attribution initiative.
What Is FinOps? Defining the Operating Model
FinOps (Financial Operations) is a cloud financial management practice that brings financial accountability to the variable-spend model of cloud computing. The FinOps Foundation defines it as a discipline that enables organizations to get maximum business value from cloud by helping engineering, finance, technology, and business teams to collaborate on data-driven spending decisions.
What makes FinOps distinct from traditional IT budgeting is its operating philosophy: in a cloud model, engineering teams control spending in real time through infrastructure decisions. That means cost ownership must shift left — into product and engineering — rather than remaining a finance-only concern.
The three core principles of FinOps are:
Teams need to collaborate. Finance, engineering, and product operate with a shared language around cloud spend.
Everyone takes ownership of their cloud usage. Cost accountability is distributed, not centralized.
A FinOps team drives the process and culture. A centralized FinOps function enables and advocates, but does not control.
Why Does Cost Management Matter?
In practice, most organizations have an unbalanced cost/resource structure that was created during the planning, deployment, and subsequent launch stages of a project. An unbalanced structure leads to additional margin loss and, in some cases, quality loss.
But with FinOps practice, each operational group can access the data they need to influence their costs in near real-time and make decisions based on it that will lead to efficient cloud costs balanced with service speed or performance.
Thus, FinOps as a service has a direct impact on the margins of an organization or project, allowing cross-functional teams (project owners, engineers, and management) to maximize the use of resources based on a budget but in real-time.
Who Participates in a FinOps Practice?
One of the most common implementation failures we see is treating FinOps as purely a DevOps or infrastructure responsibility. Effective FinOps requires structured participation across four stakeholder groups:
RoleResponsibility in FinOpsKey ContributionFinOps LeadOwns the practice, drives reporting cadence, manages toolingAccountability framework, cost allocation rulesEngineering TeamsMake resource provisioning decisions in real timeRightsizing, autoscaling, tagging complianceFinance TeamsTranslate cloud spend into business metrics and forecastsBudget setting, variance analysis, showback/chargebackProduct OwnersAlign spend to product value and business outcomesUnit economics, feature cost attributionWho Participates in a FinOps Practice?
The FinOps team generates recommendations, such as reconfiguring resources or committing to cloud service providers, that need to be considered by the organization.
The FinOps Maturity Model: Crawl, Walk, Run
Every organization that successfully implements FinOps passes through three maturity stages. Understanding which stage you are in determines what actions will deliver the most impact — and what is premature.
🐛 Stage 1: Crawl
Cloud cost visibility established
Basic tagging strategy defined
Cost dashboards created
Anomaly alerting configured
Engineering teams introduced to cost data
Manual monthly cost reviews
Typical duration: 1–3 months
🚶 Stage 2: Walk
Rightsizing recommendations actioned
Reserved Instance and Savings Plan coverage >50%
Showback reports shared with teams
Kubernetes cost allocation in place
FinOps reviews in sprint cadence
Forecasting with <15% variance
Typical duration: 3–6 months
🏃 Stage 3: Run
Full chargeback to business units
Automated anomaly remediation
Unit cost economics tracked per product
Spot instance adoption >40%
FinOps KPIs embedded in OKRs
Continuous optimization culture
Typical duration: Ongoing
Most organizations we engage with are operating at the Crawl stage when we arrive — they have cloud bills but limited attribution, and engineering teams have little visibility into the cost impact of their decisions.
Top FinOps Practices to Manage Cloud Costs
FinOps is an evolving practice that empowers organizations to manage their cloud expenses efficiently and fine-tune their financial operations. Below, we present some of the prime FinOps practices for proficiently controlling cloud costs:
1. Monitoring and Tracking Cloud Expenditure
The initial step in effectively overseeing cloud expenses is the vigilant monitoring and tracking of cloud spending. This entails gaining a deep understanding of the utilization patterns of various services, pinpointing the primary drivers of costs, and closely observing user trends. These actions are instrumental in uncovering areas ripe for cost optimization, identifying redundant resources, and recognizing underutilized services.
2. Implementing Cost Optimization Strategies
Once the key cost drivers have been pinpointed, the implementation of cost-efficiency strategies can commence. This involves harnessing discounts, making judicious use of spot instances, downsizing underused services, and eliminating superfluous resources. Here are some recommendations to initiate this process:
Scrutinize Your Company’s Expenditures
Identify Sources of Squander and Inefficiency
Rationalize Operational Procedures
3. Automating Management of Cloud Costs
Automation stands as the linchpin of cost control in the realm of cloud services. By automating key processes, organizations can expedite the discovery of cost-saving opportunities, automate the provisioning of resources, and streamline billing procedures. Automation plays a pivotal role in helping companies uncover and rectify inefficiencies in cloud cost management. For instance, it can facilitate real-time tracking of cloud resource utilization, enabling the identification and repurposing or termination of redundant or underutilized assets. Moreover, it can flag cost optimization prospects, such as discounts or incentives from cloud providers and potential strategies for economizing, such as resource scaling.
4. Leverage Tools for Cost Control
A multitude of cost control tools is at your disposal to facilitate efficient management of cloud costs. These optimization tools are adept at tracking usage patterns, establishing budgetary thresholds, and flagging opportunities for cost efficiency. Their design caters to empowering businesses with the capability to scrutinize and dissect their financial outlays. These tools enable meticulous expense tracking, identification of areas with potential for optimization, and the execution of cost-cutting measures.
5. Implementing Resource Allocation Strategies
Resource allocation proves pivotal in the effective management of cloud costs. The objective is to allocate resources in the most resourceful manner possible, taking into account usage trends and cost efficiency tactics.
6. Harnessing Cloud Cost Forecasting
The practice of cloud cost forecasting serves as a valuable resource for comprehending future cloud expenses and pinpointing areas ripe for cost reduction. This forward-looking approach aids in strategic planning and fosters more precise budgeting.
7. Investing in Cloud Governance
Establishing comprehensive cloud governance protocols is a foundational element in the realm of cloud cost management. This entails the formulation of rules and policies governing cloud utilization, the delineation of roles and responsibilities, and the diligent monitoring of compliance.
How to Set Up FinOps in Your Business?
Stage 1: Planning FinOps in the Organization 1. Gather Support: identify key stakeholders interested in increasing cloud margins. Familiarize yourself with the opportunities for your organization with better resource and expenditure analysis. 2. Determine the required time for monitoring and supporting FinOps in your organization based on time and data flow cycles. 3. Plan target actions and require a team with the relevant skills for FinOps. 4. Make decisions regarding the collection and storage of cloud consumption data. 5. Think about reporting tools and data transmission for FinOps stakeholders.
Stage 2: Adoption of FinOps FinOps is a cultural change that requires the involvement of various teams and individuals throughout the organization. Communication and feedback cycles aimed at encouraging the practice are crucial. The goal of this stage is to present the FinOps plan created in Stage 1 to stakeholders. The presentation below helps communicate this clearly, easily, and quickly:
Share a high-level activity roadmap of FinOps and the value it brings to different teams and projects.
Understand cross-team challenges and explain/teach how FinOps can help address them.
Establish a collaboration model between FinOps and key partners (IT domains, controllers, program teams).
Create and implement a FinOps dashboard for key stakeholders and cross-functional teams.
Stage 3: Operational Phase
The FinOps lifecycle is built around a 3-stage model and has the same principles in each of them.
Cross-functional teams must collaborate.
Decisions are made based on cloud value for the business.
Everyone takes responsibility for their cloud usage.
FinOps reports should be accessible and timely.
A centralized team manages FinOps.
Leverage the benefits of the cloud model with variable expenses.
To prepare for a successful FinOps practice, certain criteria need to be met:
Prepare a resource map or a list of resources in active projects, as specified in contracts and actively deployed environments.
Track complete and up-to-date consumption data from all cloud providers.
Enable cost analysis and expenditure forecasting for active projects.
Ability to assess discrepancies between contractual (budgeted) and actual consumption levels.
Reporting is the only way to provide information on cloud consumption discrepancies and offer recommendations for resource structuring or resizing. Data quality collected through APIs or proprietary cloud solutions, as mentioned earlier, is a critical prerequisite for the reporting process.
Top 3 FinOps Best Practices of Automation
1. Tag Management
After establishing a tagging standard for your organization, you can use automation to ensure compliance with this standard.
Start by identifying resources with missing or incorrectly applied tags, and then assign responsibility to rectify these tag violations. You can also proceed to stop or lock resources to compel owners to take action and potentially work on deletion or decommissioning policies for these resources.
However, resource deletion is a highly effective form of automation, so many companies may not reach this level of maturity immediately. It is advisable not to jump directly to resource deletion without addressing previous, less impactful levels of automation.
2. Scheduled Resource Start/Stop
Managing resources and automation allows you to schedule resource stoppages when they are not in use (e.g., outside of office hours) and then bring them back online when needed.
The goal of this automation is to minimize impact on teams while saving significant costs during hours when their resources are idle. This automation is often deployed in development and testing environments, where resource unavailability is not noticed outside of working hours.
You should ensure that the implementation allows team members to bypass scheduled actions in case they need to keep a server active during off-hours. Additionally, canceling a scheduled task should not completely remove the resource from automation but merely skip the current execution.
3. Usage Reduction
Automation for usage reduction eliminates waste of notifications to responsible team members for better cost optimization.
Automated resource data retrieval from services like Trusted Advisor (for AWS), third-party cost optimization platforms, or directly from resource metrics provides a straightforward way to send notifications to team members responsible for resources to investigate or, in some environments, allows for automatic resource termination or resizing.
FinOps Cloud Cost Management: The Implementation Stages
Stage 1 — Inform: Building Cost Visibility
The first principle of FinOps is that visibility precedes optimization. Before you can reduce cloud spend, you need to understand where it is going, which teams own it, and how it maps to business value. This requires:
Activating cloud cost management tooling (AWS Cost Explorer, Azure Cost Management, Google Cloud Billing)
Establishing a resource tagging taxonomy (environment, team, product, cost center)
Creating cost allocation reports by business unit
Configuring budget alerts and anomaly detection
Building a cloud cost dashboard visible to engineering and finance simultaneously
In our experience, organizations that skip this phase and go straight to optimization waste engineering time on changes that do not address their actual largest cost drivers. Tagging remediation alone — going back through existing infrastructure to apply consistent tags — typically takes 4–6 weeks for a mid-sized cloud environment.
Stage 2 — Optimize: Reducing Waste and Right-Sizing
Once visibility is established, optimization follows a consistent priority order. The highest-ROI actions in the shortest timeframe are:
Optimization PracticeImplementation EffortSavings PotentialTime to ValueEC2/VM RightsizingLowHigh (15–30%)2–4 weeksReserved Instances / Savings PlansMediumHigh (30–60% vs on-demand)Immediate after purchaseStorage Tier OptimizationLowMedium (8–20%)2–3 weeksKubernetes Resource GovernanceHighHigh (20–45%)4–8 weeksSpot / Preemptible Instance AdoptionMediumHigh (60–80% for eligible workloads)3–6 weeksIdle Resource TerminationLowMedium (5–15%)1–2 weeksCross-Region Traffic ReductionMediumLow–Medium (3–12%)4–6 weeksOptimize: Reducing Waste and Right-Sizing
Stage 3 — Operate: Embedding FinOps into Engineering Culture
The Operate phase is where FinOps transforms from a project into a practice. This requires making cost accountability a routine part of how engineering teams work — not a periodic audit. Key mechanisms include:
Embedding cost review into sprint retrospectives and architectural decision records
Automated cost policies enforced through IaC (Terraform cost estimation, Infracost integration)
Chargeback or showback reporting linked to team OKRs
Cloud cost discussed in engineering all-hands as a product metric, not an IT overhead
Top Cloud FinOps KPIs
Answering the question of how to measure the success of FinOps program, from our experience, I can outline six main KPIs (but any KPI should be defined by your organization):
Cloud Spend
This metric provides visibility into how much money you spend on cloud services to get a clear picture of your cloud spending and identify areas where else to save money.
Cloud Utilization
This metric measures how efficiently you’re using your cloud resources.
Cloud Availability
The metric measures cloud environment’s reliability and meeting performance expectations. Poor availability can lead to downtime and lost productivity.
Cloud Security
Cloud Security measures the security of your cloud environment and helps you identify any potential threats.
Cloud Adoption
Cloud Adoption measures the rate at which your organization is adopting cloud technologies.
Measuring the right metrics is what separates a FinOps program from a one-time cost audit. The KPIs below represent the metrics we track across all client engagements, organized by maturity stage:
KPIWhat It MeasuresTarget / BenchmarkMaturity StageTagging Coverage Rate% of resources with mandatory cost tags>95%CrawlReserved Instance / Savings Plan Coverage% of eligible compute covered by commitments>70%WalkReserved Instance Utilization% of purchased RI capacity actually used>90%WalkCost Forecast AccuracyVariance between forecast and actual spend<10%WalkWaste Rate% of spend attributable to idle/unused resources<5%Walk–RunUnit Cost (Cost per Feature/Transaction)Cloud cost relative to business outputTrending down QoQRunSpot Instance Adoption Rate% of eligible workloads running on Spot/Preemptible>40% of eligibleRun
Chargeback vs. Showback: Choosing the Right Accountability Model
One of the most strategic decisions in a FinOps program is how to implement cost accountability across teams. The two models serve different organizational contexts:
Showback gives engineering and product teams visibility into their cloud costs without financial consequences. Teams see what they spend, but it does not affect their budget. This is the right starting point for organizations building FinOps culture from scratch.
Chargeback allocates actual cloud costs to business units or teams, affecting their P&L or budget. This creates stronger behavioral incentives but requires mature cost allocation data — misattributed costs will create organizational friction.
Our recommendation: start with showback for the first 3–6 months while tagging coverage and attribution accuracy improve, then migrate to chargeback once you can attribute >90% of spend to specific owners.
Best FinOps Tools in 2026
Native cloud tooling is the right starting point for most organizations. Third-party platforms add value primarily at scale or in multi-cloud environments:
Native Cloud Tools
AWS Cost Explorer + AWS Cost and Usage Report (CUR) — Granular cost analysis, RI recommendations, Savings Plans modeler. Free.
Azure Cost Management + Billing — Budget alerts, cost allocation, advisor recommendations. Included with Azure.
Google Cloud Billing + Cost Insights — Committed Use Discount recommendations, BigQuery billing export for custom analysis.
Third-Party and Open Source
Kubecost — Kubernetes cost allocation down to namespace, deployment, and pod level. Essential for organizations with significant EKS/GKE/AKS spend.
CloudHealth by VMware — Multi-cloud cost management at enterprise scale.
Apptio Cloudability — Strong financial analytics and chargeback capabilities.
Infracost — Open source tool that estimates infrastructure cost changes in CI/CD pipelines before deployment. Excellent for shift-left cost governance.
OpenCost (CNCF project) — Open standard for Kubernetes cost monitoring. See CNCF OpenCost.
Common FinOps Mistakes We See in Practice
After 50+ cloud optimization engagements, these are the failure patterns that appear most consistently — and the ones we are most direct with clients about:
1. Buying Reserved Instances Before Understanding Your Workloads
We have seen organizations commit to 1- and 3-year Reserved Instances for workloads that were subsequently decommissioned or significantly resized within 6 months. Unused RIs represent real financial waste. The rule: only commit to RIs for workloads with >70% stable utilization over the past 3 months and a credible 12-month forward forecast.
2. Misconfigured Autoscaling
Autoscaling that is configured for maximum availability and never scales down is a common source of overprovisioning. We frequently find minimum instance counts set so high that the "auto" in autoscaling is entirely theoretical — the cluster never scales below the minimum because the minimum already covers peak load.
3. Ignoring Kubernetes Cost Governance
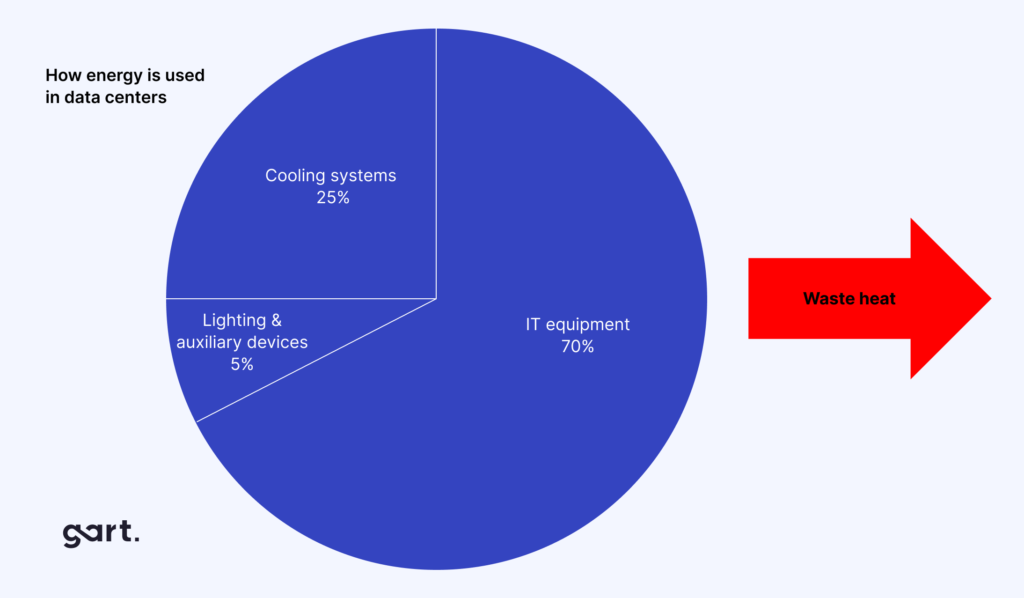
Kubernetes clusters are the fastest-growing source of cloud waste we encounter. Teams provision generous CPU and memory limits at the namespace level, which get allocated — and billed — even when actual utilization is a fraction of the reservation. CNCF data shows Kubernetes resource utilization averaging 13% of allocated CPU and 20% of allocated memory across production clusters. That gap is money.
4. Treating Tagging as an Afterthought
Tagging is the precondition for everything else in FinOps. Without consistent tags, you cannot do cost allocation, chargeback, or per-team dashboards. Yet most organizations we engage with have fewer than 60% of resources tagged — and of those, the consistency and completeness is often poor. Tag early, tag everything, enforce through IaC and policy.
5. FinOps as a One-Time Audit
The organizations that sustain cloud cost savings treat FinOps as a continuous practice embedded in engineering culture — not a quarterly audit driven by CFO pressure. One-time optimization delivers one-time results; cloud environments evolve constantly, and optimization without governance reverts within 6–12 months.
Lessons From 50+ Cloud Cost Optimization Projects
The following insights reflect patterns from our actual project history, not textbook guidance:
The biggest source of waste is almost never what the client expects. Clients come to us expecting compute to be the problem. In most cases, it is: forgotten non-production environments running 24/7, unmanaged Kubernetes resource limits, or data transfer costs between availability zones that nobody ever measured.
Savings without governance are temporary. The organizations that sustain 30%+ reductions embed cost review into sprint ceremonies. Those that achieve savings through a one-time optimization audit typically revert within 12 months.
Unit economics beat percentage savings as a long-term KPI. Reducing cloud cost per transaction or per active user is a more meaningful metric than absolute spend reduction, especially for scaling businesses where total cloud spend is expected to grow.
FinOps culture requires executive sponsorship. Without a CTO or VP Engineering who treats cloud cost as a product metric — not just an IT overhead — FinOps practices do not survive organizational friction.
Editorial Disclosure: This article was written by Roman Burdiuzha, CTO and Co-Founder of Gart Solutions, drawing on experience from client cloud cost engagements. Specific savings figures referenced are from individual project outcomes and represent actual measured results. Savings potential varies based on cloud maturity, workload architecture, current governance practices, and cloud provider. Statistics cited from third-party sources are linked to their original publications.
Conclusion
In this article, we've covered the fundamentals of FinOps as well as how to set up Cloud FinOps practices in your business. By leveraging these capabilities, organizations can achieve greater cost visibility, financial control, and overall operational efficiency in their cloud environments.
Start your cloud FinOps journey with Gart's FinOps Assessment. You will get a roadmap and a completely executable plan wherever you are on your cloud journey.
So, whether you're implementing a full cloud operating model, or just managing your cloud cost, a collaboration with Cloud FinOps partner like Gart, drives your organization. Schedule a free consultation.

⚡ Key Takeaways
Rightsizing compute alone reduces cloud costs by 20–40% in most environments — yet most teams skip it after initial setup.
Unmanaged data transfer and forgotten storage account for nearly 35% of unnecessary cloud spend in our optimization projects — more than idle compute.
Reserved Instances are not always the best choice: in fast-growing SaaS environments, Savings Plans outperform traditional RIs due to changing workload patterns.
Kubernetes clusters without cost controls are one of the fastest-growing sources of cloud waste in 2025–2026.
A FinOps governance model reduces cost drift by up to 60% over 12 months compared to ad-hoc optimization.
Cloud costs are the second-largest operational expense for most engineering-led companies — and the fastest-growing. According to the FinOps Foundation, organizations waste on average 32% of their cloud spend. That's not a vendor problem. It's a governance and execution problem.
I'm Roman Burdiuzha, co-founder and CTO at Gart Solutions, and I've personally led cloud cost optimization projects across 50+ environments — AWS, Azure, GCP, and hybrid — for SaaS, healthcare, fintech, and enterprise clients. The patterns are consistent, and the fixes are specific.
This guide goes beyond the standard "rightsize your VMs" advice. I'll share what we actually find when we audit cloud environments, which optimization levers deliver the most impact, and how to build a FinOps culture that prevents costs from growing back.
In this post, I'll share some practical tips to help you maximize the value of your cloud investments while minimizing unnecessary expenses.
[lwptoc]
Main Components of Cloud Costs — and What You're Likely Underestimating
Most cloud cost discussions focus on compute. In our experience, compute is rarely where the biggest leaks are. Here's what the full picture looks like:
Cost ComponentDescription% of Total Bill (Avg.)Optimization PotentialCompute (VMs / EC2 / Nodes)Virtual machines, container nodes, serverless invocations40–55%High (20–40% savings)StorageObject storage, block volumes, backups, snapshots15–25%High (30–60% with lifecycle policies)Data TransferEgress to internet, cross-region, cross-AZ10–20%Often overlooked; 25–40% reducibleDatabase ServicesManaged RDS, Aurora, Cosmos DB, BigQuery10–18%Medium–HighNetworkingLoad balancers, NAT gateways, VPNs, CDN5–10%Often invisible; NAT gateways are a frequent culpritKubernetes / Container OrchestrationControl plane, node groups, cluster autoscaling5–15% (growing fast)High with proper bin-packingUnused/Forgotten ResourcesUnattached EBS, idle load balancers, stale snapshots8–15%Near-total elimination possibleMain Components of Cloud Costs — and What You're Likely Underestimating
💡 From the Field — Roman Burdiuzha, CTO, Gart Solutions
"In our optimization work, the biggest source of waste isn't compute. Unmanaged data transfer and forgotten storage consistently account for nearly 35% of unnecessary cloud spend — more than idle VMs. Teams focus on rightsizing servers because it's visible in the dashboard. The egress bills hide in a line item most engineers don't open."
Step 1: Identify and Eliminate Zombie Resources
Before you optimize what's running, you need to eliminate what shouldn't be running at all. Zombie resources — orphaned compute, unattached disks, forgotten snapshots — are the lowest-hanging fruit in any cloud cost audit.
Cloud Waste Detection Framework
Resource TypeCommon Waste PatternDetection MethodPotential SavingsEBS Volumes (AWS)Unattached disks from terminated instancesAWS Cost Explorer → filter by "unattached"5–15% of storage billEC2 / VMsIdle instances (<5% CPU over 14 days)AWS Compute Optimizer / Azure Advisor10–30% of compute billSnapshotsNever deleted; retained indefinitelyScript: age > 90 days with no policy5–20% of storage billLoad BalancersPointing to no healthy targets (legacy environments)Check target group health metrics3–10% of networking billElastic IPs (AWS)Reserved but unattached to running instancesFilter: "not associated" in EC2 consoleMinor but easy winNAT GatewaysPer-GB processed data charge; often abused for internal trafficReview VPC Flow Logs; use VPC endpoints instead5–25% of networking billManaged DatabasesDev/test RDS instances running 24/7Tag review: environment=dev + always-on schedule10–40% of DB billCloud Waste Detection Framework
How to Run a Zombie Resource Audit (4-Step Process)
Enable tagging enforcement.Without tags, there's no way to identify resource ownership. Set mandatory tags:env,team,project,cost-center. Resources without these tags should trigger an alert.
Run idle resource detection.AWS Compute Optimizer, Azure Advisor, and Google Cloud Recommender all provide out-of-the-box idle resource flagging. Schedule a weekly review.
Audit snapshots and backups.Write a simple script (or use AWS Data Lifecycle Manager) to flag snapshots older than 90 days that have no attached policy.
Implement a "delete on idle" policy for dev/test.Environments that show zero connections for 72+ hours should auto-stop. Implement this using AWS Instance Scheduler or Azure DevTest Labs.
Potential Savings 15–35% of total bill
Implementation Difficulty Low
Time to Impact 1–2 weeks
Tools AWS Compute Optimizer, Azure Advisor, GCP Recommender
Step 2: Rightsizing — The #1 Lever Most Teams Misuse
Rightsizing is the practice of matching instance type and size to actual workload requirements. According to the FinOps Foundation, the average cloud environment runs at 14% CPU utilization. Most teams over-provision at initial deployment and never revisit.
How to Rightsize Effectively
The most common mistake is rightsizing once and treating it as done. Workloads change. A SaaS product that needed an r5.4xlarge at launch may only need an r5.xlarge 18 months later after engineering optimizations. We recommend a quarterly rightsizing review as part of your FinOps cycle.
AWS Rightsizing
Use AWS Compute Optimizer — it analyzes 14 days of CloudWatch metrics and recommends specific instance type changes, including cross-family migrations (e.g., from general-purpose M-series to compute-optimized C-series). Average savings from following these recommendations: 21–35% on compute.
Refer to the AWS Well-Architected Framework — Cost Optimization Pillar for the official decision framework.
Azure Rightsizing
Azure Advisor provides size recommendations under the "Cost" tab. Enable Azure Hybrid Benefit to reuse existing Windows Server and SQL Server licenses — this alone can reduce VM costs by up to 40% for Windows workloads without changing any infrastructure.
GCP Rightsizing
Google Cloud's Active Assist Recommender surfaces idle VM recommendations. Pair rightsizing with Committed Use Discounts (CUDs) — GCP's equivalent of Reserved Instances — for 1-year (37% off) or 3-year (55% off) commitments on Compute Engine.
🔍 What We See in Practice
"In 9 out of 10 environments we audit, the dev/staging infrastructure is provisioned at near-production scale. Downsizing dev environments to burstable instances (T3/T4g on AWS, B-series on Azure) typically saves $2,000–$15,000/month with zero impact on developer productivity."
Potential Savings 20–40% of compute bill
Implementation Difficulty Medium
Time to Impact 2–4 weeks
Step 3: Commitment Discounts — Reserved Instances vs. Savings Plans
This is one of the most nuanced decisions in cloud cost optimization. The right answer depends on your workload growth trajectory, not just your current usage.
AWS: Reserved Instances vs. Savings Plans
DimensionReserved Instances (RIs)Compute Savings PlansCommitment typeSpecific instance family, size, regionDollar amount per hour (flexible)FlexibilityLow (convertible RIs help but are complex)High (applies across EC2, Lambda, Fargate)Max discountUp to 72% (1yr, all upfront)Up to 66% (1yr, all upfront)Best forStable, predictable workloads on specific instance typesFast-growing SaaS, variable instance mixRiskStranded capacity if workloads changeSlight discount gap vs. RIsAWS: Reserved Instances vs. Savings Plans
💡 Contrarian Take — From 50+ Projects
"Reserved Instances are not always the best choice. In fast-growing SaaS environments, Savings Plans consistently outperform traditional RI strategies because your instance mix changes as you scale. We've seen companies with stranded RIs costing them more than they saved. Unless your workload is stable and well-defined, start with Savings Plans."
Azure: Reserved Instances + Hybrid Benefit
Azure Reserved VM Instances offer discounts of up to 72% versus pay-as-you-go for 3-year terms. Stack this with Azure Hybrid Benefit (bring your own Windows/SQL license) and you can achieve blended savings of 55–80% on eligible workloads. See the Azure Hybrid Benefit documentation for eligibility.
GCP: Committed Use Discounts
GCP's Committed Use Discounts apply to specific amounts of vCPU and memory. Unlike AWS, GCP also offers automatic sustained use discounts — if you run an instance for more than 25% of a month, GCP automatically applies a discount of up to 30%, with no commitment required.
Potential Savings 30–72% vs. on-demand
Implementation Difficulty Low-Medium
Time to ImpactImmediate after purchase
Step 4: Spot and Preemptible Instances — Where They Work and Where They Fail
Spot instances (AWS), preemptible VMs (GCP), and Spot VMs (Azure) offer discounts of up to 90% versus on-demand pricing. But using them incorrectly costs more than you save.
Workloads That Are a Good Fit for Spot
Batch data processing jobs (ETL, ML training, image processing)
CI/CD build agents (stateless, interruptible)
Big data analytics (Spark, Hadoop on EMR)
Rendering and media encoding pipelines
Non-production test environments
Workloads That Are NOT a Good Fit
Stateful databases or caches
Long-running, stateful microservices without checkpointing
Any workload with a strict SLA under 99.9%
Production API servers without session externalization
Production-Grade Spot Architecture
The right pattern for using spot in production is a mixed instance group: use Spot for the majority of capacity (60–80%), with On-Demand or Reserved instances as a baseline (20–40%). This is natively supported via AWS Auto Scaling Groups, Azure VMSS, and GCP Managed Instance Groups.
Potential SavingsUp to 90% vs. on-demand (60–80% realistically for mixed fleets)
Implementation DifficultyMedium-High
Risk Interruption; requires fault-tolerant architecture
Step 5: Kubernetes Cost Optimization — The Emerging Frontier
If your organization runs Kubernetes, this is now one of your most important optimization areas. Kubernetes makes it easy to over-provision resources — and most teams do. Namespace-level visibility doesn't come for free, and without it, containers silently consume capacity that no one claims.
The Four Kubernetes Cost Levers
1. Set Accurate Resource Requests and Limits
The #1 source of Kubernetes waste: pods with overestimated resource requests. Kubernetes schedules based on requests, not actual usage. If a pod requests 4 CPU but only uses 0.3 CPU, you're paying for 4 CPU of node capacity. Use CNCF-recommended tooling like Vertical Pod Autoscaler (VPA) to automatically right-size requests based on observed usage.
2. Cluster Autoscaler and Karpenter (AWS)
Cluster Autoscaler adds and removes nodes based on pending pod scheduling. Karpenter (AWS-native) goes further: it provisions nodes just-in-time with the exact instance type needed for pending workloads, then consolidates underloaded nodes automatically. Teams using Karpenter report 20–40% additional savings over Cluster Autoscaler alone.
3. Namespace-Level Cost Allocation
Use tools like OpenCost (CNCF project) or Kubecost to allocate costs by namespace, team, and workload. Without this, you have no visibility into which teams or services are driving Kubernetes spend. Implement chargeback or showback policies to create accountability.
4. Bin-Packing and Node Pool Optimization
Right-size your node pools. A cluster running many small pods on large nodes wastes capacity. Segment workloads by resource profile: compute-intensive (C-series), memory-intensive (R-series), and general-purpose (M/N-series). Use node affinity and taints to route workloads to appropriately sized pools.
📊 What We See in Kubernetes Audits
"In Kubernetes environments we audit, the average resource utilization is 18% CPU and 25% memory relative to cluster capacity. The biggest lever is almost always resource request rightsizing — not the cluster autoscaler settings. Fix the requests first, then tune the autoscaler."
Potential Savings30–60% of Kubernetes infrastructure cost
Implementation DifficultyHigh
Time to Impact2–6 weeks
Step 6: Storage Lifecycle and Data Transfer — The Hidden Cost Drivers
Storage and data transfer are the "silent" cost categories that grow unchecked while engineering teams focus on compute. In fast-growing companies, storage costs compound: they never go down, and without lifecycle policies, they accelerate.
Storage Optimization: Lifecycle Policies First
Cloud providers offer intelligent tiering that automatically moves data between storage classes based on access frequency:
ProviderHot TierCool / InfrequentArchiveTypical Savings vs. HotAWS S3S3 StandardS3 Standard-IA / Intelligent-TieringS3 Glacier / Deep ArchiveUp to 95% (Glacier Deep Archive)Azure BlobHotCoolArchiveUp to 90% (Archive tier)GCP Cloud StorageStandardNearline / ColdlineArchiveUp to 94% (Archive)Storage Optimization: Lifecycle Policies First
Quick win: Enable S3 Intelligent-Tiering for any bucket containing data older than 30 days that you don't actively manage. It requires zero code changes and typically reduces S3 costs by 20–40% within 90 days.
Data Transfer: The Overlooked Multiplier
AWS, Azure, and GCP all charge for data leaving the cloud (egress). Within the cloud, cross-AZ data transfer has a per-GB charge that is easy to miss at scale.
Most common data transfer waste patterns:
Services in different AZs communicating over private IPs (charged cross-AZ)
S3 data being read by EC2 in a different region
NAT Gateway processing charges for traffic that could use VPC Endpoints
Database reads going through Application Load Balancers unnecessarily
Fix: Enable VPC Endpoints for S3 and DynamoDB (free on AWS). This routes traffic within the AWS network and eliminates NAT Gateway processing charges for those services — a change that takes 10 minutes and saves thousands of dollars per month in high-egress environments.
Potential Savings30–60% of storage; 25–40% of data transfer
Implementation DifficultyLow–Medium
Time to Impact1–3 weeks
Step 7: FinOps Governance — How to Prevent Cost Drift
The reason cloud costs grow back after optimization is governance failure — not technical failure. Without a FinOps model, every new deployment is an uncontrolled cost event. The FinOps Foundation defines three stages of cloud financial maturity:
FinOps Maturity StageCharacteristicsWhere Most Companies AreCrawlBasic tagging, cost alerts, monthly review meetings~60% of organizationsWalkRI/Savings Plan coverage >70%, chargeback by team, weekly reporting~30% of organizationsRunReal-time cost allocation, automated anomaly detection, cloud unit economics~10% of organizationsFinOps Governance — How to Prevent Cost Drift
The Minimum Viable FinOps Model
You don't need a full FinOps team to start. Here's what we implement for mid-size engineering organizations as a minimum effective governance model:
Cloud Tagging Strategy. Enforce tags: team,env,project,cost-center. Use AWS Service Control Policies (SCPs), Azure Policy, or GCP Organization Policies to block resource creation without mandatory tags. No tags = no deployment.
Weekly Cost Review Cadence. A 30-minute weekly review with the engineering lead and finance stakeholder reviewing the previous week's cost delta. The goal is to catch anomalies within 7 days, not at month-end.
Budget Alerts with Escalation. Set alerts at 80% and 100% of monthly budget for each cost center. Route to Slack or email. Include an escalation path — who is responsible for investigation within 24 hours?
Anomaly Detection. AWS Cost Anomaly Detection (free), Azure Cost Management anomaly alerts, or Google Cloud Billing Budget alerts provide automated anomaly detection. Configure them. They catch accidental resource launches that would otherwise appear only at month-end.
Cloud Unit Economics. Define a cost-per-unit metric for your product: cost per active user, cost per API call, cost per transaction processed. Track this metric monthly. When your revenue grows faster than your cloud cost-per-unit, you have a healthy scaling model.
Multi-Account Cost Governance
If you operate across multiple AWS accounts or Azure subscriptions, consolidated billing and AWS Organizations / Azure Management Groups are essential. Use cost allocation tags at the management account level to see spend by account, region, and service in a single view. This is especially important for MSPs and companies with dev/staging/production account separation.
Cost Drift ReductionUp to 60% over 12 months vs. ad-hoc approach
Implementation DifficultyMedium
Time to Value30–60 days to establish; ongoing
Step 8: Serverless and Multi-Cloud Cost Strategy
Serverless: True Cost-Per-Use, With Caveats
Serverless computing (AWS Lambda, Azure Functions, GCP Cloud Run) offers genuine pay-per-execution billing — you pay only when code runs. For event-driven, low-to-medium throughput workloads, this is often 60–80% cheaper than always-on compute. But serverless has hidden costs at scale:
Cold start latency requires mitigation strategies (provisioned concurrency adds cost)
High-throughput Lambda at millions of requests/day can exceed EC2 cost — run the math before assuming serverless is cheaper
Data transfer from Lambda still incurs egress charges — serverless doesn't eliminate networking costs
Multi-Cloud Cost Arbitrage
True multi-cloud cost arbitrage — placing workloads on the cheapest provider dynamically — is operationally complex and usually not worth the engineering investment for most companies. The better approach is strategic multi-cloud placement: use each provider where it has a genuine advantage.
ProviderStrongest Cost-Efficiency AreasAWSSpot Instances for batch compute; S3 at scale; broadest RI/SP optionsAzureHybrid Benefit for existing Windows/SQL licenses; M365-integrated workloadsGCPBigQuery for analytics; sustained-use discounts without commitment; Preemptible VMsMulti-Cloud Cost Arbitrage
Real-World Case Studies: Measurable Outcomes
Case Study 1: AWS Cost Optimization for an Entertainment SaaS Platform
Context: A mid-size entertainment software platform running on AWS with $180,000/month cloud spend. The environment had grown organically over 5 years with no formal cost governance.
Findings from audit:
38% of EC2 instances were oversized by at least 2 sizes (CPU utilization <8%)
$22,000/month in unattached EBS volumes and unused snapshots
No Reserved Instance coverage (100% on-demand)
Dev environment running 24/7 at production scale
Actions taken:
Rightsized EC2 fleet: migrated from M5.4xlarge to M5.xlarge for 60% of instances
Automated dev environment shutdown (8pm–8am weekdays; full shutdown weekends)
Purchased 1-year Compute Savings Plans at 55% coverage
Implemented S3 Intelligent-Tiering for media assets bucket (1.2PB)
Eliminated unattached EBS and legacy snapshots
Results: 41% reduction in monthly cloud spend within 60 days. Monthly bill went from $180,000 to $106,000. Annualized saving: $888,000.
Case Study 2: Azure Cost Optimization for a Software Development Company
Context: A software development company with 120 developers running Azure at $45,000/month, experiencing 25% month-over-month cost growth with no visibility into which projects were driving spend.
Findings from audit:
No tagging — impossible to attribute costs to projects or teams
Windows VMs not using Azure Hybrid Benefit (all had eligible licenses)
SQL Server managed instances running at <20% utilization
Multiple abandoned resource groups from completed projects
Actions taken:
Enforced mandatory tagging policy via Azure Policy
Enabled Azure Hybrid Benefit across all eligible VMs and SQL instances (38% of fleet)
Rightsized SQL Managed Instances; moved two to elastic pools
Deleted abandoned resource groups after ownership review
Implemented project-level cost centers with weekly reporting to team leads
Results: 33% cost reduction within 45 days. Bill reduced from $45,000 to $30,000/month. Month-over-month growth stabilized to <5%. Full cost visibility achieved for the first time.
Case Study 3: Kubernetes Cost Optimization for a Cloud-Native SaaS
Context: A SaaS company running 8 Kubernetes clusters across AWS EKS with $95,000/month in infrastructure costs. Engineering team reported the clusters felt "too expensive" but couldn't identify where the spend was going.
Findings from audit:
Average cluster utilization: 17% CPU, 23% memory
Pod resource requests set to "defaults" — 2 CPU, 4GB memory per pod, regardless of workload
No Cluster Autoscaler; node counts static
All nodes on On-Demand; no Spot integration
Actions taken:
Deployed Vertical Pod Autoscaler in recommendation mode; rightsized all pod requests
Implemented Karpenter; consolidated from 8-node clusters to 4-5 nodes
Migrated batch workloads and CI/CD agents to Spot node groups
Deployed OpenCost for namespace-level cost attribution
Results: 48% reduction in Kubernetes infrastructure cost. Bill reduced from $95,000 to $49,000/month within 90 days.
Main Components of Cloud Costs
ComponentDescriptionCompute InstancesCost of virtual machines or compute instances used in the cloud.StorageCost of storing data in the cloud, including object storage, block storage, etc.Data TransferCost associated with transferring data within the cloud or to/from external networks.NetworkingCost of network resources like load balancers, VPNs, and other networking components.Database ServicesCost of utilizing managed database services, both relational and NoSQL databases.Content Delivery Network (CDN)Cost of using a CDN for content delivery to end users.Additional ServicesCost of using additional cloud services like machine learning, analytics, etc.Table Comparing Main Components of Cloud Costs
Are you looking for ways to reduce your cloud operating costs? Look no further! Contact Gart today for expert assistance in optimizing your cloud expenses.
10 Cloud Cost Optimization Strategies
Here are some key strategies to optimize your cloud spending:
Analyze Current Cloud Usage and Costs
Analyzing your current cloud usage and costs is an essential first step towards optimizing your cloud operating costs. Start by examining the cloud services and resources currently in use within your organization. This includes virtual machines, storage solutions, databases, networking components, and any other services utilized in the cloud. Take stock of the specific configurations, sizes, and usage patterns associated with each resource.
Once you have a comprehensive overview of your cloud infrastructure, identify any resources that are underutilized or no longer needed. These could be instances running at low utilization levels, storage volumes with little data, or services that have become obsolete or redundant. By identifying and addressing such resources, you can eliminate unnecessary costs.
Dig deeper into your cloud costs and identify the key drivers behind your expenditure. Look for patterns and trends in your usage data to understand which services or resources are consuming the majority of your cloud budget. It could be a particular type of instance, high data transfer volumes, or storage solutions with excessive replication. This analysis will help you prioritize cost optimization efforts.
During this analysis phase, leverage the cost management tools provided by your cloud service provider. These tools often offer detailed insights into resource usage, costs, and trends, allowing you to make data-driven decisions for cost optimization.
Optimize Resource Allocation
Optimizing resource allocation is crucial for reducing cloud operating costs while ensuring optimal performance.
Leverage Autoscaling
Adopt Reserved Instances
Utilize Spot Instances
Rightsize Resources
Optimize Storage
Assess the utilization of your cloud resources and identify instances or services that are over-provisioned or underutilized. Right-sizing involves matching the resource specifications (e.g., CPU, memory, storage) to the actual workload requirements. Downsize instances that are consistently running at low utilization, freeing up resources for other workloads. Similarly, upgrade underpowered instances experiencing performance bottlenecks to improve efficiency.
Take advantage of cloud scalability features to align resources with varying workload demands. Autoscaling allows resources to automatically adjust based on predefined thresholds or performance metrics. This ensures you have enough resources during peak periods while reducing costs during periods of low demand. Autoscaling can be applied to compute instances, databases, and other services, optimizing resource allocation in real-time.
Reserved instances (RIs) or savings plans offer significant cost savings for predictable or consistent workloads over an extended period. By committing to a fixed term (e.g., 1 or 3 years) and prepaying for the resource usage, you can achieve substantial discounts compared to on-demand pricing. Analyze your workload patterns and identify instances that have steady usage to maximize savings with RIs or savings plans.
For workloads that are flexible and can tolerate interruptions, spot instances can be a cost-effective option. Spot instances are spare computing capacity offered at steep discounts (up to 90% off on AWS) compared to on-demand prices. However, these instances can be reclaimed by the cloud provider with little notice, making them suitable for fault-tolerant, interruptible tasks.
When optimizing resource allocation, it's crucial to continuously monitor and adjust your resource configurations based on changing workload patterns. Leverage cloud provider tools and services that provide insights into resource utilization and performance metrics, enabling you to make data-driven decisions for efficient resource allocation.
Implement Cost Monitoring and Budgeting
Implementing effective cost monitoring and budgeting practices is crucial for maintaining control over cloud operating costs.
Take advantage of the cost management tools and features offered by your cloud provider. These tools provide detailed insights into your cloud spending, resource utilization, and cost allocation. They often include dashboards, reports, and visualizations that help you understand the cost breakdown and identify areas for optimization. Familiarize yourself with these tools and leverage their capabilities to gain better visibility into your cloud costs.
Configure cost alerts and notifications to receive real-time updates on your cloud spending. Define spending thresholds that align with your budget and receive alerts when costs approach or exceed those thresholds. This allows you to proactively monitor and control your expenses, ensuring you stay within your allocated budget. Timely alerts enable you to identify any unexpected cost spikes or unusual patterns and take appropriate actions.
Set a budget for your cloud operations, allocating specific spending limits for different services or departments. This budget should align with your business objectives and financial capabilities. Regularly review and analyze your cost performance against the budget to identify any discrepancies or areas for improvement. Adjust the budget as needed to optimize your cloud spending and align it with your organizational goals.
By implementing cost monitoring and budgeting practices, you gain better visibility into your cloud spending and can take proactive steps to optimize costs. Regularly reviewing cost performance allows you to identify potential cost-saving opportunities, make informed decisions, and ensure that your cloud usage remains within the defined budget.
Remember to involve relevant stakeholders, such as finance and IT teams, to collaborate on budgeting and align cost optimization efforts with your organization's overall financial strategy.
Use Cost-effective Storage Solutions
To optimize cloud operating costs, it is important to use cost-effective storage solutions.
Begin by assessing your storage requirements and understanding the characteristics of your data. Evaluate the available storage options, such as object storage and block storage, and choose the most suitable option for each use case. Object storage is ideal for storing large amounts of unstructured data, while block storage is better suited for applications that require high performance and low latency. By aligning your storage needs with the appropriate options, you can avoid overprovisioning and optimize costs.
Implement data lifecycle management techniques to efficiently manage your data throughout its lifecycle. This involves practices like data tiering, where you classify data based on its frequency of access or importance and store it in the appropriate storage tiers. Frequently accessed or critical data can be stored in high-performance storage, while less frequently accessed or archival data can be moved to lower-cost storage options. Archiving infrequently accessed data to cost-effective storage tiers can significantly reduce costs while maintaining data accessibility.
Cloud providers often provide features such as data compression, deduplication, and automated storage tiering. These features help optimize storage utilization, reduce redundancy, and improve overall efficiency. By leveraging these built-in optimization features, you can lower your storage costs without compromising data availability or performance.
Regularly review your storage usage and make adjustments based on changing needs and data access patterns. Remove any unnecessary or outdated data to avoid incurring unnecessary costs. Periodically evaluate storage options and pricing plans to ensure they align with your budget and business requirements.
Employ Serverless Architecture
Employing a serverless architecture can significantly contribute to reducing cloud operating costs.
Embrace serverless computing platforms provided by cloud service providers, such as AWS Lambda or Azure Functions. These platforms allow you to run code without managing the underlying infrastructure. With serverless, you can focus on writing and deploying functions or event-driven code, while the cloud provider takes care of resource provisioning, maintenance, and scalability.
One of the key benefits of serverless architecture is its cost model, where you only pay for the actual execution of functions or event triggers. Traditional computing models require provisioning resources for peak loads, resulting in underutilization during periods of low activity. With serverless, you are charged based on the precise usage, which can lead to significant cost savings as you eliminate idle resource costs.
Serverless platforms automatically scale your functions based on incoming requests or events. This means that resources are allocated dynamically, scaling up or down based on workload demands. This automatic scaling eliminates the need for manual resource provisioning, reducing the risk of overprovisioning and ensuring optimal resource utilization. With automatic scaling, you can handle spikes in traffic or workload without incurring additional costs for idle resources.
When adopting serverless architecture, it's important to design your applications or functions to take full advantage of its benefits. Decompose your applications into smaller, independent functions that can be executed individually, ensuring granular scalability and cloud cost optimization.
Consider Multi-Cloud and Hybrid Cloud Strategies
Considering multi-cloud and hybrid cloud strategies can help optimize cloud operating costs while maximizing flexibility and performance.
Evaluate the pricing models, service offerings, and discounts provided by different cloud providers. Compare the costs of comparable services, such as compute instances, storage, and networking, to identify the most cost-effective options. Take into account the specific needs of your workloads and consider factors like data transfer costs, regional pricing variations, and pricing commitments. By leveraging competition among cloud providers, you can negotiate better pricing and optimize your cloud costs.
Analyze your workloads and determine the most suitable cloud environment for each workload. Some workloads may perform better or have lower costs in specific cloud providers due to their specialized services or infrastructure. Consider factors like latency, data sovereignty, compliance requirements, and service-level agreements (SLAs) when deciding where to deploy your workloads. By strategically placing workloads, you can optimize costs while meeting performance and compliance needs.
Adopt a hybrid cloud strategy that combines on-premises infrastructure with public cloud services. Utilize on-premises resources for workloads with stable demand or data that requires local processing, while leveraging the scalability and cost-efficiency of the public cloud for variable or bursty workloads. This hybrid approach allows you to optimize costs by using the most cost-effective infrastructure for different aspects of your data processing pipeline.
Automate Resource Management and Provisioning
Automating resource management and provisioning is key to optimizing cloud operating costs and improving operational efficiency.
Infrastructure-as-code (IaC) tools such as Terraform or CloudFormation allow you to define and manage your cloud infrastructure as code. With IaC, you can express your infrastructure requirements in a declarative format, enabling automated provisioning, configuration, and management of resources. This approach ensures consistency, repeatability, and scalability while reducing manual efforts and potential configuration errors.
Automate the process of provisioning and deprovisioning cloud resources based on workload requirements. By using scripting or orchestration tools, you can create workflows or scripts that automatically provision resources when needed and release them when they are no longer required. This automation eliminates the need for manual intervention, reduces resource wastage, and optimizes costs by ensuring resources are only provisioned when necessary.
Auto-scaling enables your infrastructure to dynamically adjust its capacity based on workload demands. By setting up auto-scaling rules and policies, you can automatically add or remove resources in response to changes in traffic or workload patterns. This ensures that you have the right amount of resources available to handle workload spikes without overprovisioning during periods of low demand. Auto-scaling optimizes resource allocation, improves performance, and helps control costs by scaling resources efficiently.
It's important to regularly review and optimize your automation scripts, policies, and configurations to align them with changing business needs and evolving workload patterns. Monitor resource utilization and performance metrics to fine-tune auto-scaling rules and ensure optimal resource allocation.
Optimize Data Transfer and Bandwidth Usage
Optimizing data transfer and bandwidth usage is crucial for reducing cloud operating costs.
Analyze your data flows and minimize unnecessary data transfer between cloud services and different regions. When designing your architecture, consider the proximity of services and data to minimize cross-region data transfer. Opt for services and resources located in the same region whenever possible to reduce latency and data transfer costs. Additionally, use efficient data transfer protocols and optimize data payloads to minimize bandwidth usage.
Employ content delivery networks (CDNs) to cache and distribute content closer to your end users. CDNs have a network of edge servers distributed across various locations, enabling faster content delivery by reducing the distance data needs to travel. By caching content at edge locations, you can minimize data transfer from your origin servers to end users, reducing bandwidth costs and improving user experience.
Implement data compression and caching techniques to optimize bandwidth usage. Compressing data before transferring it between services or to end users reduces the amount of data transmitted, resulting in lower bandwidth costs. Additionally, leverage caching mechanisms to store frequently accessed data closer to users or within your infrastructure, reducing the need for repeated data transfers. Caching helps improve performance and reduces bandwidth usage, particularly for static or semi-static content.
Evaluate Reserved Instances and Savings Plans
It is important to evaluate and leverage Reserved Instances (RIs) and Savings Plans provided by cloud service providers.
Analyze your historical usage patterns and identify workloads or services with consistent, predictable usage over an extended period. These workloads are ideal candidates for long-term commitments. By understanding your long-term usage requirements, you can determine the appropriate level of reservation coverage needed to optimize costs.
Reserved Instances (RIs) and Savings Plans are cost-saving options offered by cloud providers. RIs allow you to reserve instances for a specified term, typically one to three years, at a significantly discounted rate compared to on-demand pricing. Savings Plans provide flexible coverage for a specific dollar amount per hour, allowing you to apply the savings across different instance types within the same family. Evaluate your usage patterns and purchase RIs or Savings Plans accordingly to benefit from the cost savings they offer.
Cloud usage and requirements may change over time, so it is crucial to regularly review your reserved instances and savings plans. Assess if the existing reservations still align with your workload demands and make adjustments as needed. This may involve modifying the reservation terms, resizing or exchanging instances, or reallocating savings plans to different services or instance families. By optimizing your reservations based on evolving needs, you can ensure that you maximize cost savings and minimize unused or underutilized resources.
Continuously Monitor and Optimize
Monitor your cloud usage and costs regularly to identify opportunities for cloud cost optimization. Analyze resource utilization, identify underutilized or idle resources, and make necessary adjustments such as rightsizing instances, eliminating unused services, or reconfiguring storage allocations. Continuously assess your workload demands and adjust resource allocation accordingly to ensure optimal usage and cost efficiency.
Cloud service providers frequently introduce new cost optimization features, tools, and best practices. Stay informed about these updates and enhancements to leverage them effectively. Subscribe to newsletters, participate in webinars, or engage with cloud provider communities to stay up to date with the latest cost optimization strategies. By taking advantage of new features, you can further optimize your cloud costs and take advantage of emerging cost-saving opportunities.
Create awareness and promote a culture of cost consciousness and cloud cost Optimization across your organization. Educate and train your teams on cost optimization strategies, best practices, and tools. Encourage employees to be mindful of resource usage, waste reduction, and cost-saving measures. Establish clear cost management policies and guidelines, and regularly communicate cost-saving success stories to encourage and motivate cost optimization efforts.
Conclusion: Cloud Cost Optimization
By taking a proactive approach to cloud cost optimization, businesses can not only reduce their expenses but also enhance their overall cloud operations, improve scalability, and drive innovation. With careful planning, monitoring, and optimization, businesses can achieve a cost-effective and efficient cloud infrastructure that aligns with their specific needs and budgetary goals.
Elevate your business with our Cloud Consulting Services! From migration strategies to scalable infrastructure, we deliver cost-efficient, secure, and innovative cloud solutions. Ready to transform? Contact us today.
Roman Burdiuzha
Co-founder & CTO, Gart Solutions · Cloud Architecture Expert
Roman has 15+ years of experience in DevOps and cloud architecture, with prior leadership roles at SoftServe and lifecell Ukraine. He co-founded Gart Solutions, where he leads cloud transformation and infrastructure modernization engagements across Europe and North America. In one recent client engagement, Gart reduced infrastructure waste by 38% through consolidating idle resources and introducing usage-aware automation. Read more on Startup Weekly.
Author Fedir
Fedir Kompaniiets
Co-founder & CEO, Gart Solutions · Cloud Architect & DevOps Consultant
Fedir is a technology enthusiast with over a decade of diverse industry experience. He co-founded Gart Solutions to address complex tech challenges related to Digital Transformation, helping businesses focus on what matters most — scaling. Fedir is committed to driving sustainable IT transformation, helping SMBs innovate, plan future growth, and navigate the "tech madness" through expert DevOps and Cloud managed services. Connect on LinkedIn.

In my experience optimizing cloud costs, especially on AWS, I often find that many quick wins are in the "easy to implement - good savings potential" quadrant.
[lwptoc]
That's why I've decided to share some straightforward methods for optimizing expenses on AWS that will help you save over 80% of your budget.
Choose reserved instances
Potential Savings: Up to 72%
Choosing reserved instances involves committing to a subscription, even partially, and offers a discount for long-term rentals of one to three years. While planning for a year is often deemed long-term for many companies, especially in Ukraine, reserving resources for 1-3 years carries risks but comes with the reward of a maximum discount of up to 72%.
You can check all the current pricing details on the official website - Amazon EC2 Reserved Instances
Purchase Saving Plans (Instead of On-Demand)
Potential Savings: Up to 72%
There are three types of saving plans: Compute Savings Plan, EC2 Instance Savings Plan, SageMaker Savings Plan.
AWS Compute Savings Plan is an Amazon Web Services option that allows users to receive discounts on computational resources in exchange for committing to using a specific volume of resources over a defined period (usually one or three years). This plan offers flexibility in utilizing various computing services, such as EC2, Fargate, and Lambda, at reduced prices.
AWS EC2 Instance Savings Plan is a program from Amazon Web Services that offers discounted rates exclusively for the use of EC2 instances. This plan is specifically tailored for the utilization of EC2 instances, providing discounts for a specific instance family, regardless of the region.
AWS SageMaker Savings Plan allows users to get discounts on SageMaker usage in exchange for committing to using a specific volume of computational resources over a defined period (usually one or three years).
The discount is available for one and three years with the option of full, partial upfront payment, or no upfront payment. EC2 can help save up to 72%, but it applies exclusively to EC2 instances.
Utilize Various Storage Classes for S3 (Including Intelligent Tier)
Potential Savings: 40% to 95%
AWS offers numerous options for storing data at different access levels. For instance, S3 Intelligent-Tiering automatically stores objects at three access levels: one tier optimized for frequent access, 40% cheaper tier optimized for infrequent access, and 68% cheaper tier optimized for rarely accessed data (e.g., archives).
S3 Intelligent-Tiering has the same price per 1 GB as S3 Standard — $0.023 USD.
However, the key advantage of Intelligent Tiering is its ability to automatically move objects that haven't been accessed for a specific period to lower access tiers.
Every 30, 90, and 180 days, Intelligent Tiering automatically shifts an object to the next access tier, potentially saving companies from 40% to 95%. This means that for certain objects (e.g., archives), it may be appropriate to pay only $0.0125 USD per 1 GB or $0.004 per 1 GB compared to the standard price of $0.023 USD.
Information regarding the pricing of Amazon S3
AWS Compute Optimizer
Potential Savings: quite significant
The AWS Compute Optimizer dashboard is a tool that lets users assess and prioritize optimization opportunities for their AWS resources.
The dashboard provides detailed information about potential cost savings and performance improvements, as the recommendations are based on an analysis of resource specifications and usage metrics.
The dashboard covers various types of resources, such as EC2 instances, Auto Scaling groups, Lambda functions, Amazon ECS services on Fargate, and Amazon EBS volumes.
For example, AWS Compute Optimizer reproduces information about underutilized or overutilized resources allocated for ECS Fargate services or Lambda functions. Regularly keeping an eye on this dashboard can help you make informed decisions to optimize costs and enhance performance.
Use Fargate in EKS for underutilized EC2 nodes
If your EKS nodes aren't fully used most of the time, it makes sense to consider using Fargate profiles. With AWS Fargate, you pay for a specific amount of memory/CPU resources needed for your POD, rather than paying for an entire EC2 virtual machine.
For example, let's say you have an application deployed in a Kubernetes cluster managed by Amazon EKS (Elastic Kubernetes Service). The application experiences variable traffic, with peak loads during specific hours of the day or week (like a marketplace or an online store), and you want to optimize infrastructure costs. To address this, you need to create a Fargate Profile that defines which PODs should run on Fargate. Configure Kubernetes Horizontal Pod Autoscaler (HPA) to automatically scale the number of POD replicas based on their resource usage (such as CPU or memory usage).
Manage Workload Across Different Regions
Potential Savings: significant in most cases
When handling workload across multiple regions, it's crucial to consider various aspects such as cost allocation tags, budgets, notifications, and data remediation.
Cost Allocation Tags: Classify and track expenses based on different labels like program, environment, team, or project.
AWS Budgets: Define spending thresholds and receive notifications when expenses exceed set limits. Create budgets specifically for your workload or allocate budgets to specific services or cost allocation tags.
Notifications: Set up alerts when expenses approach or surpass predefined thresholds. Timely notifications help take actions to optimize costs and prevent overspending.
Remediation: Implement mechanisms to rectify expenses based on your workload requirements. This may involve automated actions or manual interventions to address cost-related issues.
Regional Variances: Consider regional differences in pricing and data transfer costs when designing workload architectures.
Reserved Instances and Savings Plans: Utilize reserved instances or savings plans to achieve cost savings.
AWS Cost Explorer: Use this tool for visualizing and analyzing your expenses. Cost Explorer provides insights into your usage and spending trends, enabling you to identify areas of high costs and potential opportunities for cost savings.
Transition to Graviton (ARM)
Potential Savings: Up to 30%
Graviton utilizes Amazon's server-grade ARM processors developed in-house. The new processors and instances prove beneficial for various applications, including high-performance computing, batch processing, electronic design automation (EDA) automation, multimedia encoding, scientific modeling, distributed analytics, and machine learning inference on processor-based systems.
The processor family is based on ARM architecture, likely functioning as a system on a chip (SoC). This translates to lower power consumption costs while still offering satisfactory performance for the majority of clients. Key advantages of AWS Graviton include cost reduction, low latency, improved scalability, enhanced availability, and security.
Spot Instances Instead of On-Demand
Potential Savings: Up to 30%
Utilizing spot instances is essentially a resource exchange. When Amazon has surplus resources lying idle, you can set the maximum price you're willing to pay for them. The catch is that if there are no available resources, your requested capacity won't be granted.
However, there's a risk that if demand suddenly surges and the spot price exceeds your set maximum price, your spot instance will be terminated.
Spot instances operate like an auction, so the price is not fixed. We specify the maximum we're willing to pay, and AWS determines who gets the computational power. If we are willing to pay $0.1 per hour and the market price is $0.05, we will pay exactly $0.05.
Use Interface Endpoints or Gateway Endpoints to save on traffic costs (S3, SQS, DynamoDB, etc.)
Potential Savings: Depends on the workload
Interface Endpoints operate based on AWS PrivateLink, allowing access to AWS services through a private network connection without going through the internet. By using Interface Endpoints, you can save on data transfer costs associated with traffic.
Utilizing Interface Endpoints or Gateway Endpoints can indeed help save on traffic costs when accessing services like Amazon S3, Amazon SQS, and Amazon DynamoDB from your Amazon Virtual Private Cloud (VPC).
Key points:
Amazon S3: With an Interface Endpoint for S3, you can privately access S3 buckets without incurring data transfer costs between your VPC and S3.
Amazon SQS: Interface Endpoints for SQS enable secure interaction with SQS queues within your VPC, avoiding data transfer costs for communication with SQS.
Amazon DynamoDB: Using an Interface Endpoint for DynamoDB, you can access DynamoDB tables in your VPC without incurring data transfer costs.
Additionally, Interface Endpoints allow private access to AWS services using private IP addresses within your VPC, eliminating the need for internet gateway traffic. This helps eliminate data transfer costs for accessing services like S3, SQS, and DynamoDB from your VPC.
Optimize Image Sizes for Faster Loading
Potential Savings: Depends on the workload
Optimizing image sizes can help you save in various ways.
Reduce ECR Costs: By storing smaller instances, you can cut down expenses on Amazon Elastic Container Registry (ECR).
Minimize EBS Volumes on EKS Nodes: Keeping smaller volumes on Amazon Elastic Kubernetes Service (EKS) nodes helps in cost reduction.
Accelerate Container Launch Times: Faster container launch times ultimately lead to quicker task execution.
Optimization Methods:
Use the Right Image: Employ the most efficient image for your task; for instance, Alpine may be sufficient in certain scenarios.
Remove Unnecessary Data: Trim excess data and packages from the image.
Multi-Stage Image Builds: Utilize multi-stage image builds by employing multiple FROM instructions.
Use .dockerignore: Prevent the addition of unnecessary files by employing a .dockerignore file.
Reduce Instruction Count: Minimize the number of instructions, as each instruction adds extra weight to the hash. Group instructions using the && operator.
Layer Consolidation: Move frequently changing layers to the end of the Dockerfile.
These optimization methods can contribute to faster image loading, reduced storage costs, and improved overall performance in containerized environments.
Use Load Balancers to Save on IP Address Costs
Potential Savings: depends on the workload
Starting from February 2024, Amazon begins billing for each public IPv4 address. Employing a load balancer can help save on IP address costs by using a shared IP address, multiplexing traffic between ports, load balancing algorithms, and handling SSL/TLS.
By consolidating multiple services and instances under a single IP address, you can achieve cost savings while effectively managing incoming traffic.
Optimize Database Services for Higher Performance (MySQL, PostgreSQL, etc.)
Potential Savings: depends on the workload
AWS provides default settings for databases that are suitable for average workloads. If a significant portion of your monthly bill is related to AWS RDS, it's worth paying attention to parameter settings related to databases.
Some of the most effective settings may include:
Use Database-Optimized Instances: For example, instances in the R5 or X1 class are optimized for working with databases.
Choose Storage Type: General Purpose SSD (gp2) is typically cheaper than Provisioned IOPS SSD (io1/io2).
AWS RDS Auto Scaling: Automatically increase or decrease storage size based on demand.
If you can optimize the database workload, it may allow you to use smaller instance sizes without compromising performance.
Regularly Update Instances for Better Performance and Lower Costs
Potential Savings: Minor
As Amazon deploys new servers in their data processing centers to provide resources for running more instances for customers, these new servers come with the latest equipment, typically better than previous generations. Usually, the latest two to three generations are available. Make sure you update regularly to effectively utilize these resources.
Take Memory Optimize instances, for example, and compare the price change based on the relevance of one instance over another. Regular updates can ensure that you are using resources efficiently.
InstanceGenerationDescriptionOn-Demand Price (USD/hour)m6g.large6thInstances based on ARM processors offer improved performance and energy efficiency.$0.077m5.large5thGeneral-purpose instances with a balanced combination of CPU and memory, designed to support high-speed network access.$0.096m4.large4thA good balance between CPU, memory, and network resources.$0.1m3.large3rdOne of the previous generations, less efficient than m5 and m4.Not avilable
Use RDS Proxy to reduce the load on RDS
Potential for savings: Low
RDS Proxy is used to relieve the load on servers and RDS databases by reusing existing connections instead of creating new ones. Additionally, RDS Proxy improves failover during the switch of a standby read replica node to the master.
Imagine you have a web application that uses Amazon RDS to manage the database. This application experiences variable traffic intensity, and during peak periods, such as advertising campaigns or special events, it undergoes high database load due to a large number of simultaneous requests.
During peak loads, the RDS database may encounter performance and availability issues due to the high number of concurrent connections and queries. This can lead to delays in responses or even service unavailability.
RDS Proxy manages connection pools to the database, significantly reducing the number of direct connections to the database itself.
By efficiently managing connections, RDS Proxy provides higher availability and stability, especially during peak periods.
Using RDS Proxy reduces the load on RDS, and consequently, the costs are reduced too.
Define the storage policy in CloudWatch
Potential for savings: depends on the workload, could be significant.
The storage policy in Amazon CloudWatch determines how long data should be retained in CloudWatch Logs before it is automatically deleted.
Setting the right storage policy is crucial for efficient data management and cost optimization. While the "Never" option is available, it is generally not recommended for most use cases due to potential costs and data management issues.
Typically, best practice involves defining a specific retention period based on your organization's requirements, compliance policies, and needs.
Avoid using an undefined data retention period unless there is a specific reason. By doing this, you are already saving on costs.
Configure AWS Config to monitor only the events you need
Potential for savings: depends on the workload
AWS Config allows you to track and record changes to AWS resources, helping you maintain compliance, security, and governance. AWS Config provides compliance reports based on rules you define. You can access these reports on the AWS Config dashboard to see the status of tracked resources.
You can set up Amazon SNS notifications to receive alerts when AWS Config detects non-compliance with your defined rules. This can help you take immediate action to address the issue. By configuring AWS Config with specific rules and resources you need to monitor, you can efficiently manage your AWS environment, maintain compliance requirements, and avoid paying for rules you don't need.
Use lifecycle policies for S3 and ECR
Potential for savings: depends on the workload
S3 allows you to configure automatic deletion of individual objects or groups of objects based on specified conditions and schedules. You can set up lifecycle policies for objects in each specific bucket. By creating data migration policies using S3 Lifecycle, you can define the lifecycle of your object and reduce storage costs.
These object migration policies can be identified by storage periods. You can specify a policy for the entire S3 bucket or for specific prefixes. The cost of data migration during the lifecycle is determined by the cost of transfers. By configuring a lifecycle policy for ECR, you can avoid unnecessary expenses on storing Docker images that you no longer need.
Switch to using GP3 storage type for EBS
Potential for savings: 20%
By default, AWS creates gp2 EBS volumes, but it's almost always preferable to choose gp3 — the latest generation of EBS volumes, which provides more IOPS by default and is cheaper.
For example, in the US-east-1 region, the price for a gp2 volume is $0.10 per gigabyte-month of provisioned storage, while for gp3, it's $0.08/GB per month. If you have 5 TB of EBS volume on your account, you can save $100 per month by simply switching from gp2 to gp3.
Switch the format of public IP addresses from IPv4 to IPv6
Potential for savings: depending on the workload
Starting from February 1, 2024, AWS will begin charging for each public IPv4 address at a rate of $0.005 per IP address per hour. For example, taking 100 public IP addresses on EC2 x $0.005 per public IP address per month x 730 hours = $365.00 per month.
While this figure might not seem huge (without tying it to the company's capabilities), it can add up to significant network costs. Thus, the optimal time to transition to IPv6 was a couple of years ago or now.
Here are some resources about this recent update that will guide you on how to use IPv6 with widely-used services — AWS Public IPv4 Address Charge.
Collaborate with AWS professionals and partners for expertise and discounts
Potential for savings: ~5% of the contract amount through discounts.
AWS Partner Network (APN) Discounts: Companies that are members of the AWS Partner Network (APN) can access special discounts, which they can pass on to their clients. Partners reaching a certain level in the APN program often have access to better pricing offers.
Custom Pricing Agreements: Some AWS partners may have the opportunity to negotiate special pricing agreements with AWS, enabling them to offer unique discounts to their clients. This can be particularly relevant for companies involved in consulting or system integration.
Reseller Discounts: As resellers of AWS services, partners can purchase services at wholesale prices and sell them to clients with a markup, still offering a discount from standard AWS prices. They may also provide bundled offerings that include AWS services and their own additional services.
Credit Programs: AWS frequently offers credit programs or vouchers that partners can pass on to their clients. These could be promo codes or discounts for a specific period.
Seek assistance from AWS professionals and partners. Often, this is more cost-effective than purchasing and configuring everything independently. Given the intricacies of cloud space optimization, expertise in this matter can save you tens or hundreds of thousands of dollars.
More valuable tips for optimizing costs and improving efficiency in AWS environments:
Scheduled TurnOff/TurnOn for NonProd environments: If the Development team is in the same timezone, significant savings can be achieved by, for example, scaling the AutoScaling group of instances/clusters/RDS to zero during the night and weekends when services are not actively used.
Move static content to an S3 Bucket & CloudFront: To prevent service charges for static content, consider utilizing Amazon S3 for storing static files and CloudFront for content delivery.
Use API Gateway/Lambda/Lambda Edge where possible: In such setups, you only pay for the actual usage of the service. This is especially noticeable in NonProd environments where resources are often underutilized.
If your CI/CD agents are on EC2, migrate to CodeBuild: AWS CodeBuild can be a more cost-effective and scalable solution for your continuous integration and delivery needs.
CloudWatch covers the needs of 99% of projects for Monitoring and Logging: Avoid using third-party solutions if AWS CloudWatch meets your requirements. It provides comprehensive monitoring and logging capabilities for most projects.
Feel free to reach out to me or other specialists for an audit, a comprehensive optimization package, or just advice.