In my experience optimizing cloud costs, especially on AWS, I often find that many quick wins are in the "easy to implement - good savings potential" quadrant.
[lwptoc]
That's why I've decided to share some straightforward methods for optimizing expenses on AWS that will help you save over 80% of your budget.
Choose reserved instances
Potential Savings: Up to 72%
Choosing reserved instances involves committing to a subscription, even partially, and offers a discount for long-term rentals of one to three years. While planning for a year is often deemed long-term for many companies, especially in Ukraine, reserving resources for 1-3 years carries risks but comes with the reward of a maximum discount of up to 72%.
You can check all the current pricing details on the official website - Amazon EC2 Reserved Instances
Purchase Saving Plans (Instead of On-Demand)
Potential Savings: Up to 72%
There are three types of saving plans: Compute Savings Plan, EC2 Instance Savings Plan, SageMaker Savings Plan.
AWS Compute Savings Plan is an Amazon Web Services option that allows users to receive discounts on computational resources in exchange for committing to using a specific volume of resources over a defined period (usually one or three years). This plan offers flexibility in utilizing various computing services, such as EC2, Fargate, and Lambda, at reduced prices.
AWS EC2 Instance Savings Plan is a program from Amazon Web Services that offers discounted rates exclusively for the use of EC2 instances. This plan is specifically tailored for the utilization of EC2 instances, providing discounts for a specific instance family, regardless of the region.
AWS SageMaker Savings Plan allows users to get discounts on SageMaker usage in exchange for committing to using a specific volume of computational resources over a defined period (usually one or three years).
The discount is available for one and three years with the option of full, partial upfront payment, or no upfront payment. EC2 can help save up to 72%, but it applies exclusively to EC2 instances.
Utilize Various Storage Classes for S3 (Including Intelligent Tier)
Potential Savings: 40% to 95%
AWS offers numerous options for storing data at different access levels. For instance, S3 Intelligent-Tiering automatically stores objects at three access levels: one tier optimized for frequent access, 40% cheaper tier optimized for infrequent access, and 68% cheaper tier optimized for rarely accessed data (e.g., archives).
S3 Intelligent-Tiering has the same price per 1 GB as S3 Standard — $0.023 USD.
However, the key advantage of Intelligent Tiering is its ability to automatically move objects that haven't been accessed for a specific period to lower access tiers.
Every 30, 90, and 180 days, Intelligent Tiering automatically shifts an object to the next access tier, potentially saving companies from 40% to 95%. This means that for certain objects (e.g., archives), it may be appropriate to pay only $0.0125 USD per 1 GB or $0.004 per 1 GB compared to the standard price of $0.023 USD.
Information regarding the pricing of Amazon S3
AWS Compute Optimizer
Potential Savings: quite significant
The AWS Compute Optimizer dashboard is a tool that lets users assess and prioritize optimization opportunities for their AWS resources.
The dashboard provides detailed information about potential cost savings and performance improvements, as the recommendations are based on an analysis of resource specifications and usage metrics.
The dashboard covers various types of resources, such as EC2 instances, Auto Scaling groups, Lambda functions, Amazon ECS services on Fargate, and Amazon EBS volumes.
For example, AWS Compute Optimizer reproduces information about underutilized or overutilized resources allocated for ECS Fargate services or Lambda functions. Regularly keeping an eye on this dashboard can help you make informed decisions to optimize costs and enhance performance.
Use Fargate in EKS for underutilized EC2 nodes
If your EKS nodes aren't fully used most of the time, it makes sense to consider using Fargate profiles. With AWS Fargate, you pay for a specific amount of memory/CPU resources needed for your POD, rather than paying for an entire EC2 virtual machine.
For example, let's say you have an application deployed in a Kubernetes cluster managed by Amazon EKS (Elastic Kubernetes Service). The application experiences variable traffic, with peak loads during specific hours of the day or week (like a marketplace or an online store), and you want to optimize infrastructure costs. To address this, you need to create a Fargate Profile that defines which PODs should run on Fargate. Configure Kubernetes Horizontal Pod Autoscaler (HPA) to automatically scale the number of POD replicas based on their resource usage (such as CPU or memory usage).
Manage Workload Across Different Regions
Potential Savings: significant in most cases
When handling workload across multiple regions, it's crucial to consider various aspects such as cost allocation tags, budgets, notifications, and data remediation.
Cost Allocation Tags: Classify and track expenses based on different labels like program, environment, team, or project.
AWS Budgets: Define spending thresholds and receive notifications when expenses exceed set limits. Create budgets specifically for your workload or allocate budgets to specific services or cost allocation tags.
Notifications: Set up alerts when expenses approach or surpass predefined thresholds. Timely notifications help take actions to optimize costs and prevent overspending.
Remediation: Implement mechanisms to rectify expenses based on your workload requirements. This may involve automated actions or manual interventions to address cost-related issues.
Regional Variances: Consider regional differences in pricing and data transfer costs when designing workload architectures.
Reserved Instances and Savings Plans: Utilize reserved instances or savings plans to achieve cost savings.
AWS Cost Explorer: Use this tool for visualizing and analyzing your expenses. Cost Explorer provides insights into your usage and spending trends, enabling you to identify areas of high costs and potential opportunities for cost savings.
Transition to Graviton (ARM)
Potential Savings: Up to 30%
Graviton utilizes Amazon's server-grade ARM processors developed in-house. The new processors and instances prove beneficial for various applications, including high-performance computing, batch processing, electronic design automation (EDA) automation, multimedia encoding, scientific modeling, distributed analytics, and machine learning inference on processor-based systems.
The processor family is based on ARM architecture, likely functioning as a system on a chip (SoC). This translates to lower power consumption costs while still offering satisfactory performance for the majority of clients. Key advantages of AWS Graviton include cost reduction, low latency, improved scalability, enhanced availability, and security.
Spot Instances Instead of On-Demand
Potential Savings: Up to 30%
Utilizing spot instances is essentially a resource exchange. When Amazon has surplus resources lying idle, you can set the maximum price you're willing to pay for them. The catch is that if there are no available resources, your requested capacity won't be granted.
However, there's a risk that if demand suddenly surges and the spot price exceeds your set maximum price, your spot instance will be terminated.
Spot instances operate like an auction, so the price is not fixed. We specify the maximum we're willing to pay, and AWS determines who gets the computational power. If we are willing to pay $0.1 per hour and the market price is $0.05, we will pay exactly $0.05.
Use Interface Endpoints or Gateway Endpoints to save on traffic costs (S3, SQS, DynamoDB, etc.)
Potential Savings: Depends on the workload
Interface Endpoints operate based on AWS PrivateLink, allowing access to AWS services through a private network connection without going through the internet. By using Interface Endpoints, you can save on data transfer costs associated with traffic.
Utilizing Interface Endpoints or Gateway Endpoints can indeed help save on traffic costs when accessing services like Amazon S3, Amazon SQS, and Amazon DynamoDB from your Amazon Virtual Private Cloud (VPC).
Key points:
Amazon S3: With an Interface Endpoint for S3, you can privately access S3 buckets without incurring data transfer costs between your VPC and S3.
Amazon SQS: Interface Endpoints for SQS enable secure interaction with SQS queues within your VPC, avoiding data transfer costs for communication with SQS.
Amazon DynamoDB: Using an Interface Endpoint for DynamoDB, you can access DynamoDB tables in your VPC without incurring data transfer costs.
Additionally, Interface Endpoints allow private access to AWS services using private IP addresses within your VPC, eliminating the need for internet gateway traffic. This helps eliminate data transfer costs for accessing services like S3, SQS, and DynamoDB from your VPC.
Optimize Image Sizes for Faster Loading
Potential Savings: Depends on the workload
Optimizing image sizes can help you save in various ways.
Reduce ECR Costs: By storing smaller instances, you can cut down expenses on Amazon Elastic Container Registry (ECR).
Minimize EBS Volumes on EKS Nodes: Keeping smaller volumes on Amazon Elastic Kubernetes Service (EKS) nodes helps in cost reduction.
Accelerate Container Launch Times: Faster container launch times ultimately lead to quicker task execution.
Optimization Methods:
Use the Right Image: Employ the most efficient image for your task; for instance, Alpine may be sufficient in certain scenarios.
Remove Unnecessary Data: Trim excess data and packages from the image.
Multi-Stage Image Builds: Utilize multi-stage image builds by employing multiple FROM instructions.
Use .dockerignore: Prevent the addition of unnecessary files by employing a .dockerignore file.
Reduce Instruction Count: Minimize the number of instructions, as each instruction adds extra weight to the hash. Group instructions using the && operator.
Layer Consolidation: Move frequently changing layers to the end of the Dockerfile.
These optimization methods can contribute to faster image loading, reduced storage costs, and improved overall performance in containerized environments.
Use Load Balancers to Save on IP Address Costs
Potential Savings: depends on the workload
Starting from February 2024, Amazon begins billing for each public IPv4 address. Employing a load balancer can help save on IP address costs by using a shared IP address, multiplexing traffic between ports, load balancing algorithms, and handling SSL/TLS.
By consolidating multiple services and instances under a single IP address, you can achieve cost savings while effectively managing incoming traffic.
Optimize Database Services for Higher Performance (MySQL, PostgreSQL, etc.)
Potential Savings: depends on the workload
AWS provides default settings for databases that are suitable for average workloads. If a significant portion of your monthly bill is related to AWS RDS, it's worth paying attention to parameter settings related to databases.
Some of the most effective settings may include:
Use Database-Optimized Instances: For example, instances in the R5 or X1 class are optimized for working with databases.
Choose Storage Type: General Purpose SSD (gp2) is typically cheaper than Provisioned IOPS SSD (io1/io2).
AWS RDS Auto Scaling: Automatically increase or decrease storage size based on demand.
If you can optimize the database workload, it may allow you to use smaller instance sizes without compromising performance.
Regularly Update Instances for Better Performance and Lower Costs
Potential Savings: Minor
As Amazon deploys new servers in their data processing centers to provide resources for running more instances for customers, these new servers come with the latest equipment, typically better than previous generations. Usually, the latest two to three generations are available. Make sure you update regularly to effectively utilize these resources.
Take Memory Optimize instances, for example, and compare the price change based on the relevance of one instance over another. Regular updates can ensure that you are using resources efficiently.
InstanceGenerationDescriptionOn-Demand Price (USD/hour)m6g.large6thInstances based on ARM processors offer improved performance and energy efficiency.$0.077m5.large5thGeneral-purpose instances with a balanced combination of CPU and memory, designed to support high-speed network access.$0.096m4.large4thA good balance between CPU, memory, and network resources.$0.1m3.large3rdOne of the previous generations, less efficient than m5 and m4.Not avilable
Use RDS Proxy to reduce the load on RDS
Potential for savings: Low
RDS Proxy is used to relieve the load on servers and RDS databases by reusing existing connections instead of creating new ones. Additionally, RDS Proxy improves failover during the switch of a standby read replica node to the master.
Imagine you have a web application that uses Amazon RDS to manage the database. This application experiences variable traffic intensity, and during peak periods, such as advertising campaigns or special events, it undergoes high database load due to a large number of simultaneous requests.
During peak loads, the RDS database may encounter performance and availability issues due to the high number of concurrent connections and queries. This can lead to delays in responses or even service unavailability.
RDS Proxy manages connection pools to the database, significantly reducing the number of direct connections to the database itself.
By efficiently managing connections, RDS Proxy provides higher availability and stability, especially during peak periods.
Using RDS Proxy reduces the load on RDS, and consequently, the costs are reduced too.
Define the storage policy in CloudWatch
Potential for savings: depends on the workload, could be significant.
The storage policy in Amazon CloudWatch determines how long data should be retained in CloudWatch Logs before it is automatically deleted.
Setting the right storage policy is crucial for efficient data management and cost optimization. While the "Never" option is available, it is generally not recommended for most use cases due to potential costs and data management issues.
Typically, best practice involves defining a specific retention period based on your organization's requirements, compliance policies, and needs.
Avoid using an undefined data retention period unless there is a specific reason. By doing this, you are already saving on costs.
Configure AWS Config to monitor only the events you need
Potential for savings: depends on the workload
AWS Config allows you to track and record changes to AWS resources, helping you maintain compliance, security, and governance. AWS Config provides compliance reports based on rules you define. You can access these reports on the AWS Config dashboard to see the status of tracked resources.
You can set up Amazon SNS notifications to receive alerts when AWS Config detects non-compliance with your defined rules. This can help you take immediate action to address the issue. By configuring AWS Config with specific rules and resources you need to monitor, you can efficiently manage your AWS environment, maintain compliance requirements, and avoid paying for rules you don't need.
Use lifecycle policies for S3 and ECR
Potential for savings: depends on the workload
S3 allows you to configure automatic deletion of individual objects or groups of objects based on specified conditions and schedules. You can set up lifecycle policies for objects in each specific bucket. By creating data migration policies using S3 Lifecycle, you can define the lifecycle of your object and reduce storage costs.
These object migration policies can be identified by storage periods. You can specify a policy for the entire S3 bucket or for specific prefixes. The cost of data migration during the lifecycle is determined by the cost of transfers. By configuring a lifecycle policy for ECR, you can avoid unnecessary expenses on storing Docker images that you no longer need.
Switch to using GP3 storage type for EBS
Potential for savings: 20%
By default, AWS creates gp2 EBS volumes, but it's almost always preferable to choose gp3 — the latest generation of EBS volumes, which provides more IOPS by default and is cheaper.
For example, in the US-east-1 region, the price for a gp2 volume is $0.10 per gigabyte-month of provisioned storage, while for gp3, it's $0.08/GB per month. If you have 5 TB of EBS volume on your account, you can save $100 per month by simply switching from gp2 to gp3.
Switch the format of public IP addresses from IPv4 to IPv6
Potential for savings: depending on the workload
Starting from February 1, 2024, AWS will begin charging for each public IPv4 address at a rate of $0.005 per IP address per hour. For example, taking 100 public IP addresses on EC2 x $0.005 per public IP address per month x 730 hours = $365.00 per month.
While this figure might not seem huge (without tying it to the company's capabilities), it can add up to significant network costs. Thus, the optimal time to transition to IPv6 was a couple of years ago or now.
Here are some resources about this recent update that will guide you on how to use IPv6 with widely-used services — AWS Public IPv4 Address Charge.
Collaborate with AWS professionals and partners for expertise and discounts
Potential for savings: ~5% of the contract amount through discounts.
AWS Partner Network (APN) Discounts: Companies that are members of the AWS Partner Network (APN) can access special discounts, which they can pass on to their clients. Partners reaching a certain level in the APN program often have access to better pricing offers.
Custom Pricing Agreements: Some AWS partners may have the opportunity to negotiate special pricing agreements with AWS, enabling them to offer unique discounts to their clients. This can be particularly relevant for companies involved in consulting or system integration.
Reseller Discounts: As resellers of AWS services, partners can purchase services at wholesale prices and sell them to clients with a markup, still offering a discount from standard AWS prices. They may also provide bundled offerings that include AWS services and their own additional services.
Credit Programs: AWS frequently offers credit programs or vouchers that partners can pass on to their clients. These could be promo codes or discounts for a specific period.
Seek assistance from AWS professionals and partners. Often, this is more cost-effective than purchasing and configuring everything independently. Given the intricacies of cloud space optimization, expertise in this matter can save you tens or hundreds of thousands of dollars.
More valuable tips for optimizing costs and improving efficiency in AWS environments:
Scheduled TurnOff/TurnOn for NonProd environments: If the Development team is in the same timezone, significant savings can be achieved by, for example, scaling the AutoScaling group of instances/clusters/RDS to zero during the night and weekends when services are not actively used.
Move static content to an S3 Bucket & CloudFront: To prevent service charges for static content, consider utilizing Amazon S3 for storing static files and CloudFront for content delivery.
Use API Gateway/Lambda/Lambda Edge where possible: In such setups, you only pay for the actual usage of the service. This is especially noticeable in NonProd environments where resources are often underutilized.
If your CI/CD agents are on EC2, migrate to CodeBuild: AWS CodeBuild can be a more cost-effective and scalable solution for your continuous integration and delivery needs.
CloudWatch covers the needs of 99% of projects for Monitoring and Logging: Avoid using third-party solutions if AWS CloudWatch meets your requirements. It provides comprehensive monitoring and logging capabilities for most projects.
Feel free to reach out to me or other specialists for an audit, a comprehensive optimization package, or just advice.

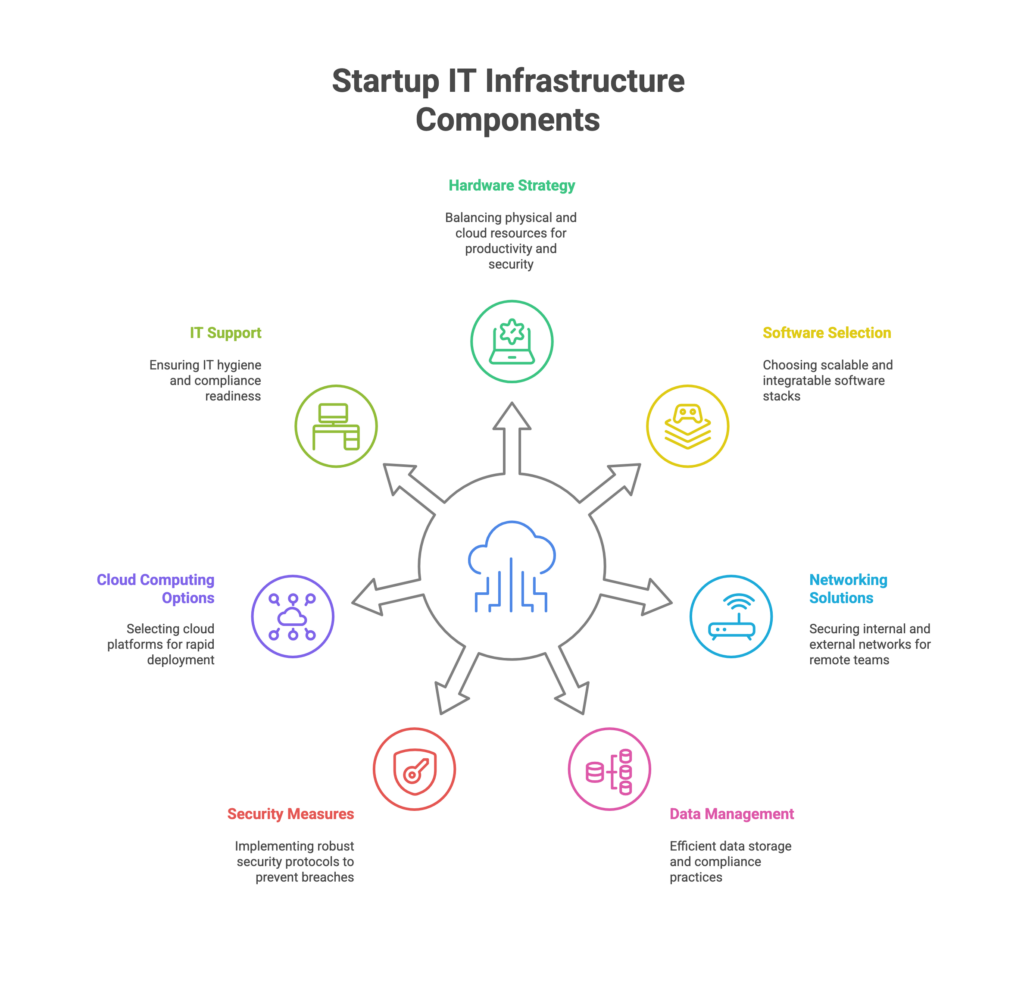
IT systems hold the data, apps, and networks that keep a business running. If they fail or get hacked, everything can stop.
IT infrastructure security means protecting these systems from attacks and mistakes. It covers hardware, software, networks, and data.
Cyberattacks are growing. They are not rare events but everyday risks. If a company is not ready, it can lose money, face lawsuits, and damage its reputation.
This matters for any business—big or small. Good security builds trust with customers, protects sensitive data, and keeps operations stable.
Key Threats to IT Infrastructure Security
Organizations face a range of evolving cyber threats:
Malware and ransomware: Still among the most common, causing operational shutdowns and costly recovery.
DDoS attacks: Overwhelm systems, disrupt services, and affect customer experience.
Phishing and human error: A recurring weak link, often opening the door to larger breaches.
Exploited vulnerabilities in poorly secured networks and outdated softwarerozi,+83.
Notably, 70% of IT security experts interviewed in the study identified human error as the primary factor in incidents, underscoring the need for awareness training and stronger organizational security culture.
Malware and Ransomware Attacks
Malware and ransomware attacks present considerable risks to the security of IT infrastructure. Malicious programs like viruses, worms, and Trojan horses can infiltrate systems through diverse vectors such as email attachments, infected websites, or software downloads. Once within the infrastructure, malware can compromise sensitive data, disrupt operations, and even grant unauthorized access to malicious actors. Ransomware, a distinct form of malware, encrypts vital files and extorts a ransom for their decryption, potentially resulting in financial losses and operational disruptions.
Phishing and Social Engineering Attacks
Phishing and social engineering attacks target individuals within an organization, exploiting their trust and manipulating them into divulging sensitive information or performing actions that compromise security. These attacks often come in the form of deceptive emails, messages, or phone calls, impersonating legitimate entities. By tricking employees into sharing passwords, clicking on malicious links, or disclosing confidential data, cybercriminals can gain unauthorized access to the IT infrastructure and carry out further malicious activities.
Insider Threats
Insider threats refer to security risks that arise from within an organization. They can occur due to intentional actions by disgruntled employees or unintentional mistakes made by well-meaning staff members. Insider threats can involve unauthorized data access, theft of sensitive information, sabotage, or even the introduction of malware into the infrastructure. These threats are challenging to detect, as insiders often have legitimate access to critical systems and may exploit their privileges to carry out malicious actions.
Distributed Denial of Service (DDoS) Attacks
DDoS attacks aim to disrupt the availability of IT infrastructure by overwhelming systems with a flood of traffic or requests. Attackers utilize networks of compromised computers, known as botnets, to generate massive amounts of traffic directed at a target infrastructure. This surge in traffic overwhelms the network, rendering it unable to respond to legitimate requests, causing service disruptions and downtime. DDoS attacks can impact businesses financially, tarnish their reputation, and impede normal operations.
Data Breaches and Theft
Data breaches and theft transpire when unauthorized individuals acquire entry to sensitive information housed within the IT infrastructure. This encompasses personally identifiable information (PII), financial records, intellectual property, and trade secrets. Perpetrators may exploit software vulnerabilities, weak access controls, or inadequate encryption to infiltrate the infrastructure and extract valuable data. The ramifications of data breaches are far-reaching and encompass legal liabilities, financial repercussions, and harm to the organization's reputation.
Vulnerabilities in Software and Hardware
Software and hardware vulnerabilities introduce weaknesses in the IT infrastructure that can be exploited by attackers. These vulnerabilities can arise from coding errors, misconfigurations, or outdated software and firmware. Attackers actively search for and exploit these weaknesses to gain unauthorized access, execute arbitrary code, or perform other malicious activities. Regular patching, updates, and vulnerability assessments are critical to mitigating these risks and ensuring a secure IT infrastructure.
Strategies for Optimizing IT Infrastructure Security
The study highlights three pillars of a successful IT security strategy: policy, technology, and training.
1. Implementing Security Frameworks
Frameworks like the NIST Cybersecurity Framework and ISO/IEC 27001 help organizations identify, protect, detect, respond to, and recover from threats. They provide a structured roadmap for resilience.
2. Adopting Modern Defense Technologies
Encryption ensures data confidentiality.
Next-generation firewalls block evolving threats.
AI-driven threat detection improves speed and accuracy, with reports showing it can cut incident response time by 50%rozi,+83.
Intrusion detection systems (IDS) add an extra layer of monitoring and defense.
3. Prioritizing Human-Centric Security
Policies and awareness programs are as critical as technical defenses. Regular training reduces human error, phishing susceptibility, and careless data handling.
https://youtu.be/NFVCpGQFjgA?si=D8cA2q2dPR9UBpWl
Real-World Case Study: How Gart Transformed IT Infrastructure Security for a Client
The entertainment software platform SoundCampaign approached Gart with a twofold challenge: optimizing their AWS costs and automating their CI/CD processes. Additionally, they were experiencing conflicts and miscommunication between their development and testing teams, which hindered their productivity and caused inefficiencies within their IT infrastructure.
As a trusted DevOps company, Gart devised a comprehensive solution that addressed both the cost optimization and automation needs, while also improving the client's IT infrastructure security and fostering better collaboration within their teams.
To streamline the client's CI/CD processes, Gart introduced an automated pipeline using modern DevOps tools. We leveraged technologies such as Jenkins, Docker, and Kubernetes to enable seamless code integration, automated testing, and deployment. This eliminated manual errors, reduced deployment time, and enhanced overall efficiency.
Recognizing the importance of IT infrastructure security, Gart implemented robust security measures to minimize risks and improve collaboration within the client's teams. By implementing secure CI/CD pipelines and automated security checks, we ensured a clear and traceable code deployment process. This clarity minimized conflicts between developers and testers, as it became evident who made changes and when. Additionally, we implemented strict access controls, encryption mechanisms, and continuous monitoring to enhance overall security posture.
Are you concerned about the security of your IT infrastructure? Protect your valuable digital assets by partnering with Gart, your trusted IT security provider.
Best Practices for IT Infrastructure Security
Good security is not only about technology. It also needs clear rules, user awareness, and regular checks. Here are the basics:
Access controls and authentication: Use strong passwords, multi-factor authentication, and manage who has access to what. This limits the risk of someone breaking in.
Updates and patches: Keep software and hardware up to date. Fixing known issues quickly reduces the chance of attacks.
Monitoring and auditing: Watch network traffic for anything unusual. Tools like SIEM can help spot problems early and limit damage.
Data encryption: Encrypt sensitive data both when stored and when sent. This keeps information safe if it gets intercepted.
Firewalls and intrusion detection: Firewalls block unwanted traffic. IDS tools alert you when something suspicious happens. Together they protect the network.
Employee training: Most attacks start with human error. Regular training helps staff avoid phishing, scams, and careless mistakes.
Backups and disaster recovery: Back up data on schedule and test recovery plans often. This ensures you can restore critical systems if something goes wrong.
Our team of experts specializes in securing networks, servers, cloud environments, and more. Contact us today to fortify your defenses and ensure the resilience of your IT infrastructure.
Network Infrastructure
A strong network is key to protecting business systems. Here are the main steps:
Secure wireless networks: Use WPA2 or WPA3 encryption, change default passwords, and turn off SSID broadcasting. Add MAC filtering and always keep access points updated.
Use VPNs: VPNs create an encrypted tunnel for remote access. This keeps data private when employees connect over public networks.
Segment and isolate networks: Split the network into smaller parts based on roles or functions. This limits how far an attacker can move if one system is breached. Each segment should have its own rules and controls.
Monitor and log activity: Watch network traffic for unusual behavior. Keep logs of events to help with investigations and quick response to incidents.
Server Infrastructure
Servers run the core systems of any organization, so they need strong protection. Key practices include:
Harden server settings: Turn off unused services and ports, limit permissions, and set firewalls to only allow needed traffic. This reduces the attack surface.
Strong authentication and access control: Use unique, complex passwords and multi-factor authentication. Apply role-based access control (RBAC) so only the right people can reach sensitive resources.
Keep servers updated: Apply patches and firmware updates as soon as vendors release them. Staying current helps block known exploits and emerging threats.
Monitor logs and activity: Collect and review server logs to spot unusual activity or failed access attempts. Real-time monitoring helps catch and respond to threats faster.
Cloud Infrastructure Security
By choosing a reputable cloud service provider, implementing strong access controls and encryption, regularly monitoring and auditing cloud infrastructure, and backing up data stored in the cloud, organizations can enhance the security of their cloud infrastructure. These measures help protect sensitive data, maintain data availability, and ensure the overall integrity and resilience of cloud-based systems and applications.
Choosing a reputable and secure cloud service provider is a critical first step in ensuring cloud infrastructure security. Organizations should thoroughly assess potential providers based on their security certifications, compliance with industry standards, data protection measures, and track record for security incidents. Selecting a trusted provider with robust security practices helps establish a solid foundation for securing data and applications in the cloud.
Implementing strong access controls and encryption for data in the cloud is crucial to protect against unauthorized access and data breaches. This includes using strong passwords, multi-factor authentication, and role-based access control (RBAC) to ensure that only authorized users can access cloud resources. Additionally, sensitive data should be encrypted both in transit and at rest within the cloud environment to safeguard it from potential interception or compromise.
Regular monitoring and auditing of cloud infrastructure is vital to detect and respond to security incidents promptly. Organizations should implement tools and processes to monitor cloud resources, network traffic, and user activities for any suspicious or anomalous behavior. Regular audits should also be conducted to assess the effectiveness of security controls, identify potential vulnerabilities, and ensure compliance with security policies and regulations.
Backing up data stored in the cloud is essential for ensuring business continuity and data recoverability in the event of data loss, accidental deletion, or cloud service disruptions. Organizations should implement regular data backups and verify their integrity to mitigate the risk of permanent data loss. It is important to establish backup procedures and test data recovery processes to ensure that critical data can be restored effectively from the cloud backups.
Incident Response and Recovery
A well-prepared and practiced incident response capability enables timely response, minimizes the impact of incidents, and improves overall resilience in the face of evolving cyber threats.
Developing an Incident Response Plan
Developing an incident response plan is crucial for effectively handling security incidents in a structured and coordinated manner. The plan should outline the roles and responsibilities of the incident response team, the procedures for detecting and reporting incidents, and the steps to be taken to mitigate the impact and restore normal operations. It should also include communication protocols, escalation procedures, and coordination with external stakeholders, such as law enforcement or third-party vendors.
Detecting and Responding to Security Incidents
Prompt detection and response to security incidents are vital to minimize damage and prevent further compromise. Organizations should deploy security monitoring tools and establish real-time alerting mechanisms to identify potential security incidents. Upon detection, the incident response team should promptly assess the situation, contain the incident, gather evidence, and initiate appropriate remediation steps to mitigate the impact and restore security.
Conducting Post-Incident Analysis and Implementing Improvements
After the resolution of a security incident, conducting a post-incident analysis is crucial to understand the root causes, identify vulnerabilities, and learn from the incident. This analysis helps organizations identify weaknesses in their security posture, processes, or technologies, and implement improvements to prevent similar incidents in the future. Lessons learned should be documented and incorporated into updated incident response plans and security measures.
Testing Incident Response and Recovery Procedures
Regularly testing incident response and recovery procedures is essential to ensure their effectiveness and identify any gaps or shortcomings. Organizations should conduct simulated exercises, such as tabletop exercises or full-scale incident response drills, to assess the readiness and efficiency of their incident response teams and procedures. Testing helps uncover potential weaknesses, validate response plans, and refine incident management processes, ensuring a more robust and efficient response during real incidents.
IT Infrastructure Security
AspectDescriptionThreatsCommon threats include malware/ransomware, phishing/social engineering, insider threats, DDoS attacks, data breaches/theft, and vulnerabilities in software/hardware.Best PracticesImplementing strong access controls, regularly updating software/hardware, conducting security audits/risk assessments, encrypting sensitive data, using firewalls/intrusion detection systems, educating employees, and regularly backing up data/testing disaster recovery plans.Network SecuritySecuring wireless networks, implementing VPNs, network segmentation/isolation, and monitoring/logging network activities.Server SecurityHardening server configurations, implementing strong authentication/authorization, regularly updating software/firmware, and monitoring server logs/activities.Cloud SecurityChoosing a reputable cloud service provider, implementing strong access controls/encryption, monitoring/auditing cloud infrastructure, and backing up data stored in the cloud.Incident Response/RecoveryDeveloping an incident response plan, detecting/responding to security incidents, conducting post-incident analysis/implementing improvements, and testing incident response/recovery procedures.Emerging Trends/TechnologiesArtificial Intelligence (AI)/Machine Learning (ML) in security, Zero Trust security model, blockchain technology for secure transactions, and IoT security considerations.Here's a table summarizing key aspects of IT infrastructure security
Emerging Trends and Technologies in IT Infrastructure Security
Artificial Intelligence (AI) and Machine Learning (ML) in Security
Artificial Intelligence (AI) and Machine Learning (ML) are emerging trends in IT infrastructure security. These technologies can analyze vast amounts of data, detect patterns, and identify anomalies or potential security threats in real-time. AI and ML can be used for threat intelligence, behavior analytics, user authentication, and automated incident response. By leveraging AI and ML in security, organizations can enhance their ability to detect and respond to sophisticated cyber threats more effectively.
Zero Trust Security Model
The Zero Trust security model is gaining popularity as a comprehensive approach to IT infrastructure security. Unlike traditional perimeter-based security models, Zero Trust assumes that no user or device should be inherently trusted, regardless of their location or network. It emphasizes strong authentication, continuous monitoring, and strict access controls based on the principle of "never trust, always verify." Implementing a Zero Trust security model helps organizations reduce the risk of unauthorized access and improve overall security posture.
Blockchain Technology for Secure Transactions
Blockchain technology is revolutionizing secure transactions by providing a decentralized and tamper-resistant ledger. Its cryptographic mechanisms ensure the integrity and immutability of transaction data, reducing the reliance on intermediaries and enhancing trust. Blockchain can be used in various industries, such as finance, supply chain, and healthcare, to secure transactions, verify identities, and protect sensitive data. By leveraging blockchain technology, organizations can enhance security, transparency, and trust in their transactions.
Internet of Things (IoT) Security Considerations
As the Internet of Things (IoT) continues to proliferate, securing IoT devices and networks is becoming a critical challenge. IoT devices often have limited computing resources and may lack robust security features, making them vulnerable to exploitation. Organizations need to consider implementing strong authentication, encryption, and access controls for IoT devices. They should also ensure that IoT networks are separate from critical infrastructure networks to mitigate potential risks. Proactive monitoring, patch management, and regular updates are crucial to address IoT security vulnerabilities and protect against potential IoT-related threats.
These advancements enable organizations to proactively address evolving threats, enhance data protection, and improve overall resilience in the face of a dynamic and complex cybersecurity landscape.
Supercharge your IT landscape with our Infrastructure Consulting! We specialize in efficiency, security, and tailored solutions. Contact us today for a consultation – your technology transformation starts here.

To maintain smooth operation, you need to scale your resources. This article delves into the two main scaling strategies - horizontal scaling (spreading out) and vertical scaling (gearing up) - Horizontal vs. Vertical Scaling.
Even if a company pauses its processes, does not grow or develop, the amount of data will still accumulate, and information systems will become more complex. Computing requests require storing large amounts of data in the server's memory and allocating significant resources.
When corporate servers can no longer handle the load, a company has two options: purchase additional capacity for existing equipment or buy another server to offload some of the load. In this article, we will discuss the advantages and disadvantages of both approaches to building IT infrastructure.
Cloud Scalability
What is scaling? It is the ability to increase project performance in minimal time by adding resources.
Therefore, one of the priority tasks of IT specialists is to ensure the scalability of the infrastructure, i.e., the ability to quickly and without unnecessary expenses expand the volume and performance of the IT solution.
Usually, scaling does not involve rewriting the code, but either adding servers or increasing the resources of the existing one. According to this type, vertical and horizontal scaling are distinguished.
Vertical Scaling or Scale Up Infrastructure
Vertical scaling involves adding more RAM, disks, etc., to an existing server. This approach is used when the performance limit of infrastructure elements is exhausted.
Advantages of vertical scaling:
If a company lacks the resources of its existing equipment, its components can be replaced with more powerful ones.
Increasing the performance of each component within a single node increases the performance of the IT infrastructure as a whole.
However, vertical scaling also has disadvantages. The most obvious one is the limitation in increasing performance. When a company reaches its limits, it will need to purchase a more powerful system and then migrate its IT infrastructure to it. Such a transfer requires time and money and increases the risks of downtime during the system transfer.
The second disadvantage of vertical scaling is that if a virtual machine fails, the software will stop working. The company will need time to restore its functionality. Therefore, with vertical scaling, expensive hardware is often chosen that will work without downtime.
When to Scale Up Infrastructure
While scaling out offers advantages in many scenarios, scaling up infrastructure remains relevant in specific situations. Here are some key factors to consider when deciding when to scale up:
Limited growth
If your application experiences predictable and limited growth, scaling up can be a simpler and more efficient solution. Upgrading existing hardware with increased processing power, memory, and storage can often handle the anticipated growth without the complexities of managing a distributed system.
Single server bottleneck
Scaling up can be effective if you experience a performance bottleneck confined to a single server or resource type. For example, if your application primarily suffers from CPU limitations, adding more cores to the existing server might be sufficient to address the bottleneck.
Simplicity and familiarity
If your team possesses expertise and experience in managing a single server environment, scaling up might be a more familiar and manageable approach compared to the complexities of setting up and managing a distributed system with multiple nodes.
Limited resources
In scenarios with limited financial or physical resources, scaling up may be the more feasible option compared to the initial investment required for additional hardware and the ongoing costs associated with managing a distributed system.
Latency-sensitive applications
Applications with real-time processing requirements and low latency needs, such as high-frequency trading platforms or online gaming servers, can benefit from the reduced communication overhead associated with a single server architecture. Scaling up with high-performance hardware can ensure minimal latency and responsiveness.
Stateless applications
For stateless applications that don't require storing data on individual servers, scaling up can be a viable option. These applications can typically be easily migrated to a more powerful server without significant configuration changes.
Scaling up ( or verticalscaling) provides a sufficient and manageable solution for your specific needs and infrastructure constraints.
Example Situations of When to Scale Up:
E-commerce platform experiencing increased traffic during holiday seasons
Consider an e-commerce platform that experiences a surge in traffic during holiday seasons or special sales events. As more users flock to the website to make purchases, the existing infrastructure may struggle to handle the sudden influx of requests, leading to slow response times and potential downtime.
To address this issue, the e-commerce platform can opt to scale up its resources by upgrading its servers or adding more powerful processing units. By bolstering its infrastructure, the platform can better accommodate the heightened traffic load, ensuring that users can seamlessly browse, add items to their carts, and complete transactions without experiencing delays or disruptions.
Database management system for a growing social media platform
Imagine a social media platform that is rapidly gaining users and generating vast amounts of user-generated content, such as posts, comments, and media uploads. As the platform's database accumulates more data, the performance of the database management system (DBMS) may start to degrade, leading to slower query execution times and reduced responsiveness.
In response to this growth, the social media platform can choose to scale up its database infrastructure by deploying more powerful servers with higher processing capabilities and additional storage capacity. By upgrading its DBMS hardware, the platform can efficiently handle the increasing volume of user data, ensuring that users can swiftly retrieve and interact with content on the platform without experiencing delays or downtime.
Financial institution processing a growing number of transactions
Consider a financial institution, such as a bank or credit card company, that processes a large volume of transactions daily. As the institution's customer base expands and the number of transactions continues to grow, the existing processing infrastructure may struggle to keep up with the increasing workload, leading to delays in transaction processing and potential system failures.
To maintain smooth and efficient operations, the financial institution can opt to scale up its transaction processing systems by investing in more robust hardware solutions. By upgrading its servers, networking equipment, and database systems, the institution can enhance its processing capabilities, ensuring that transactions are processed quickly and accurately, and that customers have uninterrupted access to banking services.
Horizontal Scaling or Scale-Out
Horizontal scaling involves adding new nodes to the IT infrastructure. Instead of increasing the capacity of individual components of a node, the company adds new servers. With each additional node, the load is redistributed between all nodes.
Advantages of horizontal scaling:
This type of scaling allows you to use inexpensive equipment that provides enough power for workloads.
There is no need to migrate the infrastructure.
If necessary, virtual machines can be migrated to another infrastructure without stopping operation.
The company can organize work without downtime due to the fact that software instances operate on several nodes of the IT infrastructure. If one of them fails, the load will be distributed between the remaining nodes, and the program will continue to work.
With horizontal scaling, you can refuse to purchase expensive equipment and reduce hardware costs by 20 times.
When to scale out infrastructure
There are several key factors to consider when deciding when to scale out infrastructure:
Horizontal growth
If your application or service anticipates sustained growth in data, users, or workload over time, scaling out offers a more scalable and cost-effective approach than repeated scaling up. Adding new nodes allows you to incrementally increase capacity as needed, rather than investing in significantly larger hardware upgrades each time.
Performance bottlenecks
If you experience performance bottlenecks due to resource limitations (CPU, memory, storage) spread across multiple servers, scaling out can help distribute the workload and alleviate the bottleneck. This is particularly beneficial for stateful applications where data needs to be stored on individual servers.
Distributed processing
When dealing with large datasets or complex tasks that require parallel processing, scaling out allows you to distribute the workload across multiple nodes, significantly reducing processing time and improving efficiency. This is often used in big data processing and scientific computing.
Fault tolerance and redundancy
Scaling out can enhance fault tolerance and redundancy. If one server fails, the remaining nodes can handle the workload, minimizing downtime and ensuring service continuity. This is crucial for mission-critical applications where downtime can have significant consequences.
Microservices architecture
If your application employs a microservices architecture, where each service is independent and modular, scaling out individual microservices allows you to scale specific functionalities based on their specific needs. This offers greater flexibility and efficiency compared to scaling the entire application as a single unit.
Cost-effectiveness
While scaling out may require an initial investment in additional servers, in the long run, it can be more cost-effective than repeatedly scaling up. Additionally, cloud-based solutions often offer pay-as-you-go models which allow you to scale resources dynamically and only pay for what you use.
In summary, scaling out infrastructure is a good choice when you anticipate sustained growth, encounter performance bottlenecks due to resource limitations, require distributed processing for large tasks, prioritize fault tolerance and redundancy, utilize a microservices architecture, or seek cost-effective long-term scalability. Remember to carefully assess your specific needs and application characteristics to determine the optimal approach for your infrastructure.
Example Situations of When to Scale Out
Cloud-based software-as-a-service (SaaS) application facing increased demand
Consider a cloud-based SaaS application that provides project management tools to businesses of all sizes. As the application gains popularity and attracts more users, the demand for its services may skyrocket, putting strain on the existing infrastructure and causing performance degradation.
To meet the growing demand and maintain optimal performance, the SaaS provider can scale out its infrastructure by leveraging cloud computing resources such as auto-scaling groups and load balancers. By dynamically adding more virtual servers or container instances based on demand, the provider can ensure that users have access to the application's features and functionalities without experiencing slowdowns or service disruptions.
Content delivery network (CDN) handling a surge in internet traffic
Imagine a content delivery network (CDN) that delivers multimedia content, such as videos, images, and web pages, to users around the world. During peak traffic periods, such as major events or viral content trends, the CDN may experience a significant increase in incoming requests, leading to congestion and delays in content delivery.
To cope with the surge in internet traffic, the CDN can scale out its infrastructure by deploying additional edge servers or caching nodes in strategic locations. By expanding its network footprint and distributing content closer to end users, the CDN can reduce latency and improve the speed and reliability of content delivery, ensuring a seamless browsing experience for users worldwide.
E-commerce shopping cart
An e-commerce platform utilizes microservices architecture, where each service is independent and responsible for specific tasks like managing shopping carts. Scaling out individual microservices allows for handling increased user traffic and order volume without impacting other functionalities of the platform. This approach provides better flexibility and scalability compared to scaling up the entire system as a single unit.
These examples demonstrate situations where scaling out by adding more nodes horizontally is better suited to handle situations with unpredictable workloads, distributed processing needs, and independent service scaling within a larger system.
Choosing the Right Approach
The decision between horizontal and vertical scaling should be based on specific system requirements, constraints, and objectives.
Some considerations include:
Workload characteristics: Consider the nature of your workload. Horizontal scaling is well-suited for distributed and stateless workloads, while vertical scaling may be preferable for single-threaded or stateful workloads.
Cost and budget: Evaluate your budget and resource availability. Horizontal scaling can be cost-effective, especially when using commodity hardware, while vertical scaling may require a more significant upfront investment in high-performance hardware.
Performance and maintenance: Assess the performance gains and management complexity associated with each approach. Consider how well each option aligns with your operational capabilities and objectives.
Future growth: Think about your system's long-term scalability needs. If you anticipate significant growth, horizontal scaling may provide greater flexibility.
Here are some additional tips for choosing the right scaling approach:
Start with a small-scale deployment and monitor performance: This will help you understand your workload's requirements and identify any potential bottlenecks.
Use a combination of horizontal and vertical scaling: This can provide the best balance of performance, cost, and flexibility.
Consider using a cloud-based platform: Cloud providers offer a variety of scalable and cost-effective solutions that can be tailored to your specific needs.
By carefully considering all of these factors, you can choose the best scaling approach for your company's needs.
How Gart Can Help You with Cloud Scalability
Ultimately, the determining factors are your cloud needs and cost structure. Without the ability to predict the true aspects of these components, each business can fall into the trap of choosing the wrong scaling strategy for them. Therefore, cost assessment should be a priority. Additionally, optimizing cloud costs remains a complex task regardless of which scaling system you choose.
Here are some ways Gart can help you with cloud scalability:
Assess your cloud needs and cost structure: We can help you understand your current cloud usage and identify areas where you can optimize your costs.
Develop a cloud scaling strategy: We can help you choose the right scaling approach for your specific needs and budget.
Implement your cloud scaling strategy: We can help you implement your chosen scaling strategy and provide ongoing support to ensure that it meets your needs.
Optimize your cloud costs: We can help you identify and implement cost-saving measures to reduce your cloud bill.
Gart has a team of experienced cloud experts who can help you with all aspects of cloud scalability. We have a proven track record of helping businesses optimize their cloud costs and improve their cloud performance.
Contact Gart today to learn more about how we can help you with cloud scalability.
We look forward to hearing from you!