

How can AI tools enhance DevOps efficiency?
AI tools like ChatGPT, Claude, GitHub Copilot, and VZero are transforming DevOps by automating coding, streamlining infrastructure management, and accelerating UI prototyping. These tools reduce development time, minimize human error, and free up engineers for strategic tasks.
We’re long past the debate about whether AI will take over jobs. In DevOps, AI is already reshaping how we work—automating routine tasks, assisting in decision-making, and enhancing speed and productivity.
Just two years ago, using AI for code generation was off-limits in many companies. Today, it’s not only permitted — it’s encouraged. The shift has been fast and profound.
In this guide, I’ll share real-world use cases of how I use AI tools as a DevOps engineer and cloud architect, showing you where they fit into daily workflows and how they boost performance.
The Rise of AI Assistants in DevOps
Let’s dive into something that’s been on everyone’s radar lately: AI assistants. But don’t worry, we’re not going to talk about AI taking over our jobs or debating its future in society. Instead, let’s get practical and look at how we’re already using AI assistants in our daily work routines.
Just two years ago, when ChatGPT 3.5 was launched, most people couldn’t have predicted just how quickly these tools would evolve. AI’s rapid progress has been especially game-changing for the IT field. It’s as if IT professionals decided, “Why not automate parts of our own jobs first?” And here we are, seeing the impact of that decision. In just two years, AI has made strides that feel almost unreal.
I remember when many companies had strict no-AI policies. Legal restrictions were everywhere—using AI to analyze or write code was off the table. Fast forward to now, and it’s a whole different story. Many companies not only allow AI; they actively encourage it, seeing it as a way to work faster and more effectively. Tasks that used to take days can now be handed off to AI, letting us focus on deeper engineering work.
Today, I want to take you through how I, as a DevOps engineer and cloud architect, am using AI assistants to streamline different parts of my job.
Key AI Tools in DevOps and Their Use Cases
ChatGPT: Your All-in-One Assistant for DevOps
Let’s start with ChatGPT. By now, it’s a household name, probably the most recognized AI assistant and where so much of this tech revolution began. So, why do I rely on ChatGPT?
First off, it’s built on some of the largest AI models out there, often debuting groundbreaking updates. While it might feel more like a generalist than a specialist in niche areas, its capabilities for everyday tasks are impressive.
I won’t go into too much detail about ChatGPT itself, but let’s look at some recent updates that are genuinely game-changing.
For starters, ChatGPT 4.0 is now the new standard, replacing previous models 3.5 and 4. It’s a foundational model designed to handle just about any task, as they say.
But the real excitement comes with ChatGPT’s new Search feature. This is a huge leap forward, as the model can now browse the internet in real-time. Previously, it was limited to its last training cutoff, with only occasional updates. Now, it can look up current information directly from the web.
Here’s a quick example: You could ask, “What’s the current exchange rate for the Ukrainian hryvnia to the euro?” and ChatGPT will fetch the latest answer from the internet. It can even calculate taxes based on the most recent rates and regulations.
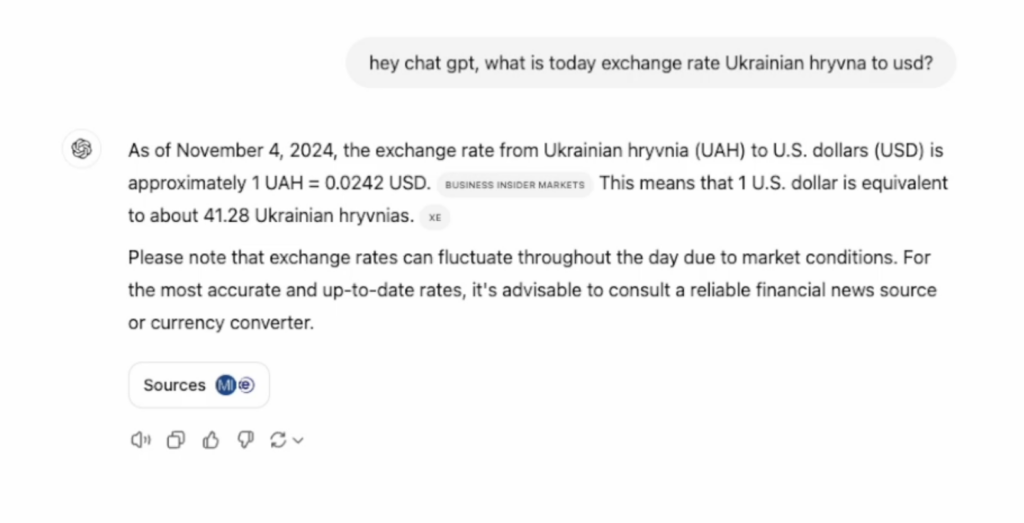
Even better, you can see the sources it uses, so you can double-check the information. This feature positions ChatGPT as a potential Google alternative for many professional questions.
Another exciting addition is ChatGPT Canvas, which offers a more visual and interactive way to collaborate with the AI. This feature lets you create and adjust diagrams, flowcharts, and other visuals directly in the chat interface. It’s perfect for brainstorming sessions, project planning, and breaking down complex ideas in a more visual format.
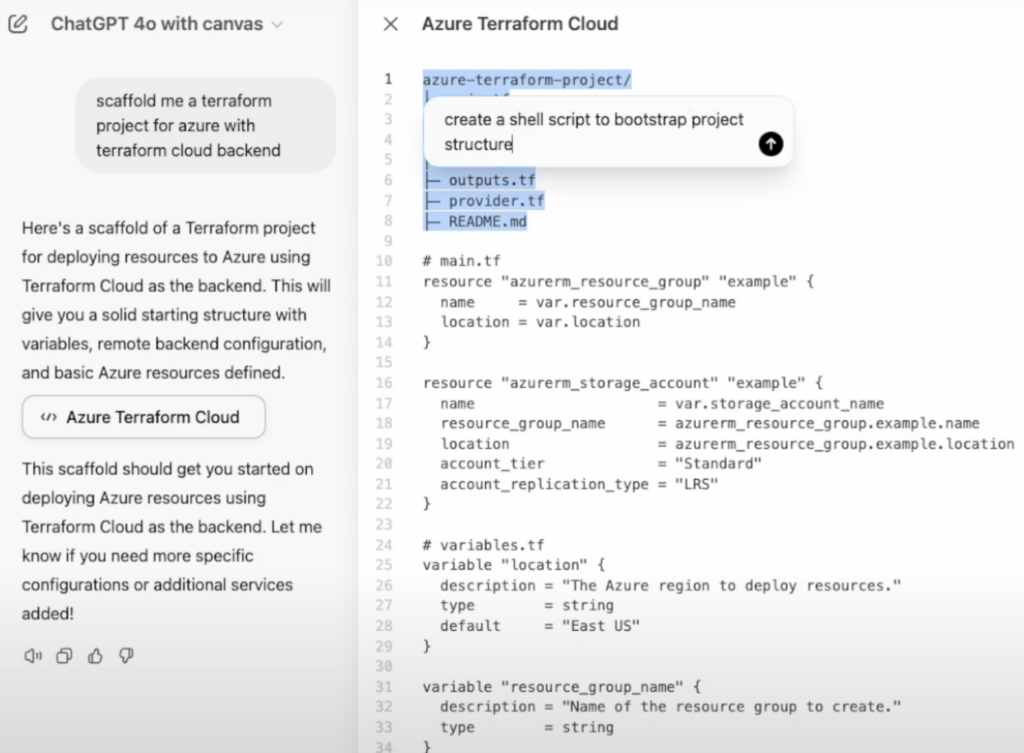
Personally, I use ChatGPT for a range of tasks — from quick questions to brainstorming sessions. With Search and Canvas, it’s evolving into an even more versatile tool that fits a variety of professional needs. It’s like having an all-in-one assistant.
To summarise, ChatGPT is good for:
🔍 Real-Time Web Access with Search
ChatGPT’s built-in browser now retrieves up-to-date information, making it more than a static assistant. Whether you’re checking the latest AWS pricing or debugging region-specific issues, this tool has you covered.
🧠 Complex Task Handling
From brainstorming pipeline structures to writing Bash scripts, ChatGPT handles high-level logic, templating, and document writing.
🗂️ Canvas: Visualizing Ideas
With Canvas, you can sketch infrastructure diagrams, brainstorm architectures, or visually debug pipeline issues—all within the same AI environment.
Use it for:
- YAML templating
- Cost estimation
- Visual breakdowns of infrastructure
- Researching live documentation
Transform Your DevOps Process with Gart’s Automation Solutions!
Take your DevOps to the next level with seamless automation. Contact us to learn how we can streamline your workflows.
Claude: AI for Project Context and Helm Charts
Claude’s project memory and file management capabilities make it ideal for large, structured DevOps tasks.
Let’s dive into a more specialized AI tool I use: Claude. Unlike other AI assistants, Claude is structured to manage files and data in a way that’s incredibly practical for DevOps. One of the best features? The ability to organize information into project-specific repositories. This setup is a huge help when juggling different environments and configurations, making it easier to pick up complex projects exactly where you left off.
Here’s a quick example. Imagine I need to create a new Helm chart for an app that’s been running on other machines.
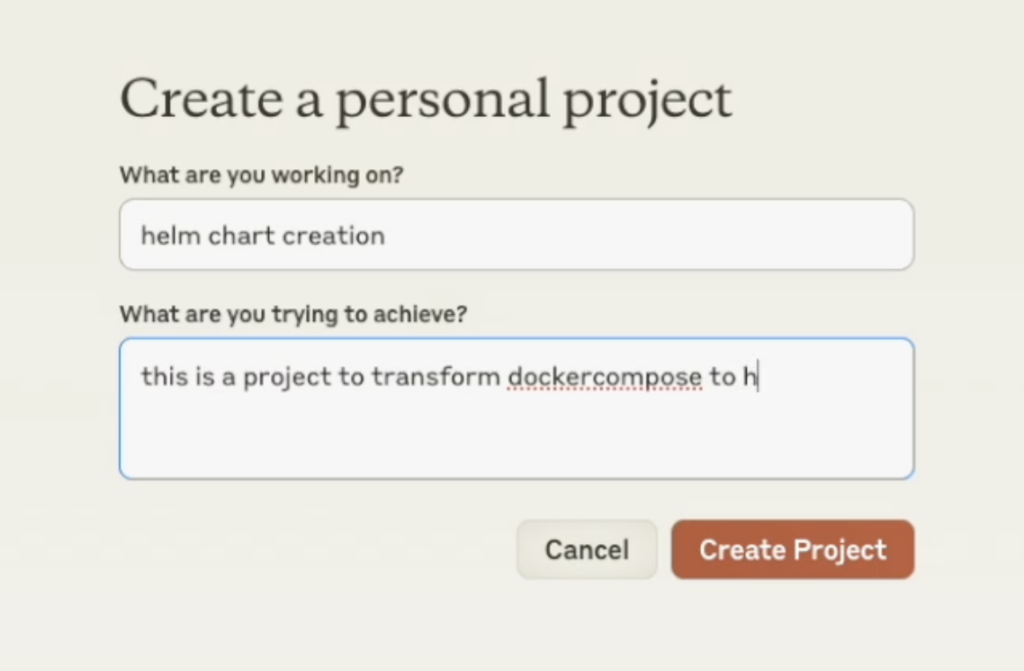
My goal is to create a universal deployment in Kubernetes. With Claude, I can start a project called “Helm Chart Creation” and load it up with essential context—best practices, reference files, and so on. Claude’s “Project Knowledge” feature is a game-changer here, allowing me to add files and snippets it should remember. If I need references from Bitnami’s Helm charts, which have an extensive library, I can just feed them directly into Claude.
Now, say I want to convert a Docker Compose file into a Helm chart. I can input the Docker Compose file and relevant Helm chart references, and Claude will scaffold the YAML files for me. Sure, it sometimes needs a bit of tweaking, but the initial output is structured, logical, and saves a massive amount of time.
In a recent project, we had to create Helm charts for a large number of services. A task that would’ve previously taken a team of two to four people several months now took just one person a few weeks, thanks to Claude’s ability to handle most of the code organization and structuring.
The only downside? You can only upload up to five files per request. But even with that limitation, Claude is a powerful tool that genuinely understands project context and writes better code.
To summarise, Claude is good for:
🧾 Project Knowledge Management
Organize your tasks by repository or project. Claude remembers past inputs and references, making it useful for tasks like:
- Converting Docker Compose to Helm
- Creating reusable Helm charts
- Structuring Kubernetes deployments
GitHub Copilot for Code Generation
Next up, let’s talk about Copilot for Visual Studio. I’ve been using it since the early days when it was just GitHub Copilot, and it’s come a long way since then. The latest version introduces some great new features that make coding even more efficient.
One small change is that Copilot now opens on the right side of the Visual Studio window—just a layout tweak, but it keeps everything organized. More importantly, it now taps into both OpenAI models and Microsoft’s proprietary AI, plus it integrates with Azure. This means it can work directly within your cloud environment, which is super useful.

Copilot also gets smart about your project setup, reading the structure and indexing files so it understands what you’re working on. For example, if I need to spin up a Terraform project for Azure with a Terraform Cloud backend, I can just ask Copilot, and it’ll generate the necessary code and config files.
It’s great for speeding up code writing, starting new projects, and even handling cloud services, all while helping troubleshoot errors as you go. One of my favorite features is the “Explain” option. If I’m stuck on a piece of code, I can ask Copilot to break it down for me, which saves me from searching online or guessing. It’s a real timesaver, especially when working with unfamiliar languages or code snippets.
GitHub Copilot is good for:
🚀 Cloud-Specific Code Generation
Copilot now understands infrastructure-as-code contexts:
- Launch a Terraform project for Azure in minutes
- Create config files and debug errors automatically
💬 Code Explainability
One standout feature is the “Explain this code” function. If you’re unfamiliar with a script, Copilot explains it clearly—perfect for onboarding or refactoring.
Use it for:
- Cloud provisioning
- Writing CI/CD scripts
- Boilerplate code in unfamiliar languages
Effortless DevOps Automation with Gart!
Let us handle the heavy lifting in DevOps. Reach out to see how Gart can simplify and accelerate your processes.
VZero for UI and Front-End Prototyping
Finally, let’s take a look at VZero from Vercel. I don’t use it as often as other tools, but it’s impressive enough that it definitely deserves a mention.
VZero is an AI-powered tool that makes creating UI forms and interfaces fast and easy. For someone like me—who isn’t a frontend developer—it’s perfect for quickly putting together a UI concept. Whether I need to show a UI idea to a dev team, share a concept with contractors, or visualize something for stakeholders, VZero makes it simple.
For example, if I need a page to display infrastructure audit results, I can start by giving VZero a basic prompt, like “I want a page that shows infrastructure audit results.” Even with this minimal direction, VZero can create a functional, attractive UI.
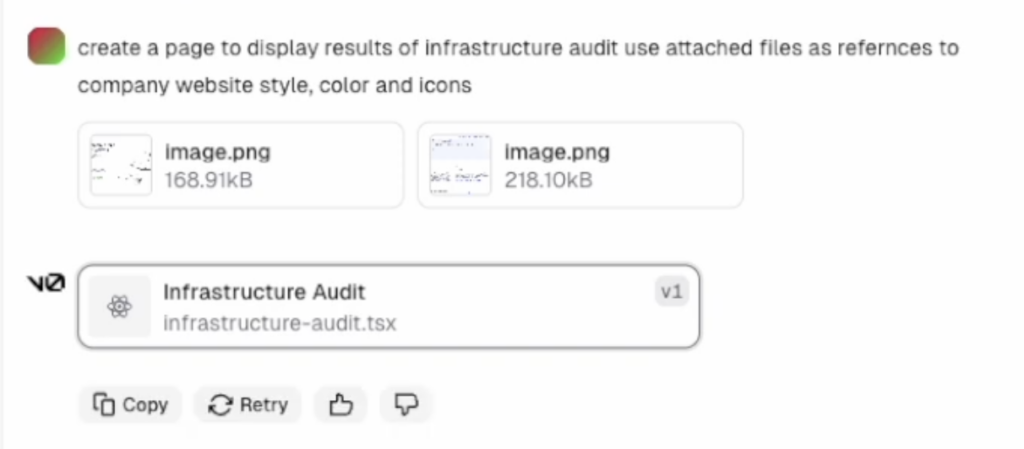
One of the best things about VZero is how well it handles design context. I can upload screenshots or examples from our existing website, and it’ll match the design language—think color schemes, styles, and layout. This means the UI it generates not only works but also looks consistent with our brand.
The tool even generates real-time editable code, so if I need to make a quick tweak—like removing an extra menu or adjusting the layout—it’s easy to do. I can just ask VZero to make the change, and it updates the UI instantly.
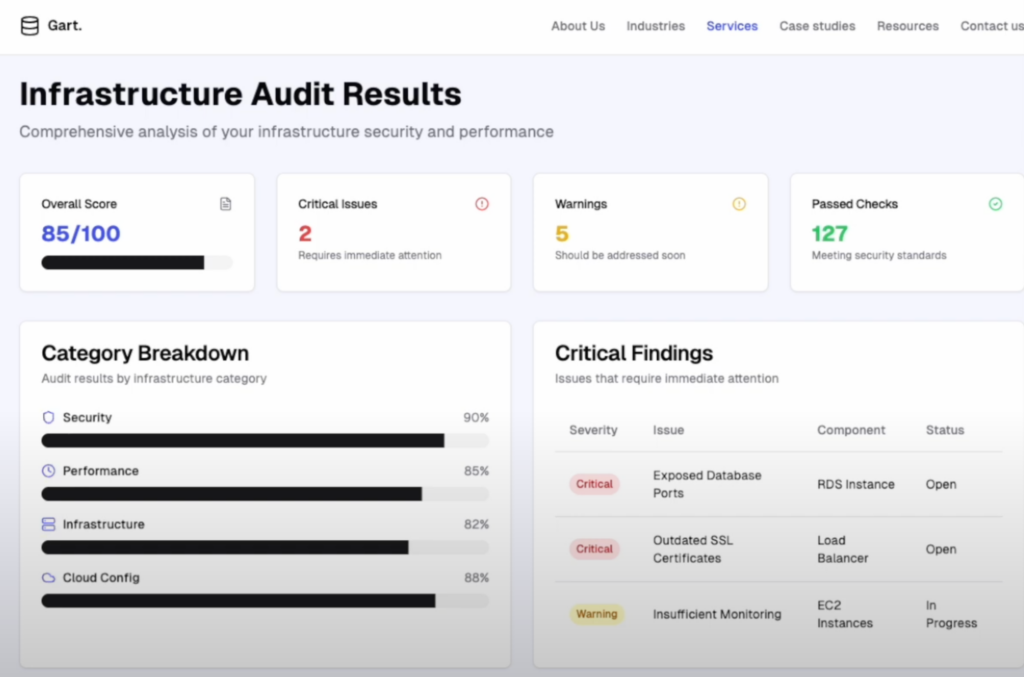
There are two main ways I use VZero:
- Prototyping: When I have a rough idea and want a quick prototype, VZero lets me visualize it without having to dive into frontend code. Then, I can pass it along to frontend developers to build out further.
- Creating Simple Forms: Sometimes, I need a quick form for a specific task, like automating a workflow or gathering input for a DevOps process. VZero lets me create these forms without needing deep frontend expertise.
Since VZero is built on Vercel’s platform, the generated code is optimized for modern frameworks like React and Next.js, making it easy to integrate with existing projects. By using AI, VZero cuts down the time and effort needed to go from idea to working UI, making frontend design more accessible to non-experts.
VZero is good for:
✨ Design Context Awareness
Upload a screenshot of your existing product, and VZero will generate matching UI components. It mimics style guides, layouts, and brand consistency.
🧩 Use Cases:
- Prototyping admin dashboards
- Mocking audit interfaces
- Creating forms for automation workflows
Built on modern React/Next.js frameworks, it outputs usable code for immediate integration.
AI’s Impact on Productivity and Efficiency
The cumulative impact of these AI tools on DevOps workflows is significant. What used to take entire teams months to complete can now be accomplished by a single engineer within weeks, thanks to AI-driven automation and structured project management. The cost-effectiveness of these tools is also noteworthy; a typical monthly subscription to all mentioned AI tools averages around $70. Given the efficiency gains, this represents a valuable investment for both individual professionals and organizations.
How to Use AI in DevOps Without Sacrificing Quality
To maximize AI’s potential, DevOps professionals must go beyond simple code generation and understand how to fully integrate these tools into their workflows. Successful use of AI involves knowing:
- When to rely on AI versus manual coding for accuracy and efficiency.
- How to assess AI-generated results critically to avoid errors.
- The importance of providing comprehensive prompts and reference materials to get the best outcomes.
To maximize value:
🔍 Review AI output like you would a junior developer’s code.
🧠 Prompt engineering matters—give context, not just commands.
⚠️ Don’t outsource critical logic—review security and environment-specific settings carefully.
By mastering these skills, DevOps teams can ensure that AI tools support their goals effectively, adding value without compromising quality.
Conclusion
AI tools have become indispensable in DevOps, transforming how engineers approach their work and enabling them to focus on higher-level tasks. As these tools continue to evolve, they are likely to become even more integral to development operations, offering ever more refined support for complex workflows. Embracing AI in DevOps is no longer a choice but a necessity, and those who learn to use it wisely will enjoy substantial advantages in productivity, adaptability, and career growth.
If you’re not leveraging AI in DevOps yet, you’re falling behind.
Want to scale your DevOps efficiency with AI-backed automation?
Connect with Gart Solutions to modernize your pipelines today.
See how we can help to overcome your challenges







