Strategic network design is the invisible backbone of every scalable, high-performing, and secure business. Get it right early, and your cloud infrastructure scales gracefully, deployments accelerate, and downtime stays near zero. Get it wrong, and a single architectural decision made in year one can cost your organization six figures to undo — or worse, it never gets fixed at all.
This guide is written for CTOs, CIOs, and engineering leaders who are either building cloud infrastructure from scratch, scaling an existing environment, or preparing for a cloud migration. It covers everything from fundamental network design principles to AWS and Azure architecture patterns, a proprietary planning checklist, real client stories, and the most expensive mistakes we see repeated across organizations of every size.
At Gart Solutions, our infrastructure and DevOps teams have reviewed, redesigned, and optimized network architectures for dozens of companies across SaaS, eCommerce, fintech, and enterprise. What follows is the accumulated insight from those engagements.
What Is Network Design — and Why Does It Determine Business Growth?
Network design is the architectural planning of how devices, systems, services, and users communicate with each other — across data centers, cloud environments, and the public internet. A well-executed network design defines the topology, segmentation model, routing policy, security perimeter, and scalability strategy of your entire technical infrastructure.
In cloud-native environments — built on AWS, Azure, or GCP — network design manifests primarily through Virtual Private Cloud (VPC) architecture, subnet segmentation, security group policy, inter-service communication patterns, and cross-region connectivity. It is the foundation on which every other infrastructure decision is made.
Why it matters for growth:
As your business scales — adding new services, expanding to new regions, onboarding enterprise clients, or pursuing compliance certification — your network architecture either enables that growth or actively blocks it. Most organizations don't realize the constraint until the damage is already done.
$9,000
Average cost per minute of IT downtime for mid-size companies
74%
Of cloud migrations that encounter network rearchitecting mid-project
40%
Reduction in deployment time after proper network segmentation
According to the Cloud Native Computing Foundation (CNCF), one of the leading causes of failed Kubernetes deployments is underestimated network complexity — specifically, the absence of a deliberate networking strategy before workloads go live. The challenge isn't cloud technology; it's the architecture underneath it.
How Poor Network Design Directly Impacts Revenue
The business cost of bad network design is rarely visible at first. It accumulates in engineering hours, deployment delays, and outage events — until one day it's visible in lost deals, churned customers, or a six-figure re-platforming bill.
Downtime and Revenue Loss
A single 30-minute outage during a peak traffic event — a product launch, Black Friday, or a quarterly billing cycle — can eliminate an entire day's revenue and trigger customer churn that takes months to recover. When that outage is caused by a flat network routing failure or an improperly segmented VPC, it is entirely preventable.
Slower Deployment Velocity
Engineering teams in organizations with poorly segmented environments spend significant time working around network constraints — manually granting access, debugging cross-environment routing failures, or waiting for firewall rule approvals. A proper network design — with clearly separated dev, staging, and production environments — removes these bottlenecks structurally.
Failed or Costly Cloud Migrations
When organizations attempt to migrate to cloud without a network design strategy, they often default to "lift and shift" into a single flat VPC. This works temporarily but creates enormous technical debt. Re-segmenting a live production environment months later — under business pressure — is significantly more expensive and risky than doing it right at the start. The Linux Foundation's LF Networking initiative has documented this pattern across enterprise adoption studies as one of the primary drivers of cloud project overruns.
Compliance Failures and Security Incidents
SOC 2, ISO 27001, PCI DSS, and GDPR all have explicit requirements around network segmentation, access control, and data flow isolation. An organization with a flat, unsegmented network cannot achieve these certifications without first rearchitecting its network. In sectors like fintech, healthcare, and enterprise SaaS, this is the difference between closing and losing an enterprise deal.
Problems Associated with Lack of Network Design
If the network design is not designed with future growth in mind, it will be difficult to add new resources and expand the cloud infrastructure.
An unoptimized network design can lead to performance problems such as latency and packet loss.
The lack of clear network segmentation can make it vulnerable to cyberattacks.
Moving resources from one network to another can be very difficult if the network design was not carefully planned.
One of our clients, RetailNow, an e-commerce company, experienced rapid growth but overlooked proper network planning. They implemented a single, flat network for all their services, which led to several critical problems
As new services and applications were added, integrating them into the existing network became increasingly difficult. The lack of a structured network design resulted in operational inefficiencies and frequent outages.
The initial network setup wasn't designed to scale. As RetailNow expanded operations to new regions, they encountered significant issues with network performance and reliability, leading to lost sales and frustrated customers.
The absence of a strategic network design led to increased operational costs. RetailNow had to invest heavily in network redesign and optimization to support their growing business needs.
The 5 Most Expensive Network Design Mistakes We See
Here are common mistakes businesses make when creating network designs:
Flat network structure
As mentioned in the RetailNow example, using a single, flat network for all services is a serious mistake. This complicates the integration of new services and leads to performance and security issues.
A flat network structure, in short, is a network design where all devices are connected to a single network segment or broadcast domain, without any hierarchical divisions or subnetworks.
Key characteristics of a flat network structure include:
Single broadcast domain
No subnets or VLANs
All devices share the same network address space
Limited traffic segregation
Simplified setup but poor scalability
This design is simple to implement for small networks but becomes problematic as the network grows, leading to increased traffic, reduced performance, and security challenges.
Insufficient Network Segmentation
When all services — databases, APIs, internal tooling, and public-facing applications — share the same subnet without granular security group rules, a single compromised resource can move laterally across the entire environment. Proper segmentation limits blast radius and is foundational to Zero Trust architecture.
Insufficient segmentation in network design refers to the inadequate division of a network into smaller, distinct subnetworks or segments. Here's a brief explanation:
Insufficient segmentation is characterized by:
Too few subnetworks or VLANs
Overly large network segments
Lack of logical separation between different types of traffic or user groups
Poor isolation of sensitive systems or data
Consequences of insufficient segmentation include reduced security due to broader attack surfaces, increased network congestion, difficulty in implementing access controls.
Proper segmentation helps improve security, performance, and manageability of the network by creating logical boundaries between different parts of the network infrastructure.
Ignoring scalability
CIDR block sizing, IP address space planning, and subnet capacity are decisions that are nearly impossible to change once production traffic is running. Many organizations run out of IP space or encounter routing conflicts during scaling, requiring complete network redesign at the worst possible time.
A scalable network design allows for easy expansion, improved performance under increased load, and the ability to adapt to changing business needs without major restructuring.
Ignoring scalability is characterized by designing only for current needs without considering future expansion, using inflexible network architectures, choosing hardware or software solutions that can't easily accommodate growth, etc.
Consequences of ignoring scalability include:
Network performance degradation as user numbers or data traffic increase
Difficulty in adding new services or applications
Costly and disruptive network redesigns or overhauls
Inability to expand to new geographic locations or integrate with other networks
Limitations on business growth due to network constraints
Suboptimal topology
Not using efficient topologies, such as hub-and-spoke, can complicate management and reduce network efficiency. Suboptimal topology in network design refers to the inefficient or ineffective arrangement of network components and their connections.
Examples of suboptimal topologies:
Overuse of hub-based networks instead of more efficient switch-based designs.
Daisy-chain configurations that create long, vulnerable paths without redundancy.
Flat networks without proper hierarchical structure, leading to broadcast storms and security issues.
Overly complex mesh networks that are difficult to manage and troubleshoot.
Consequences of suboptimal topology:
Reduced network performance and user experience
Higher operational costs due to inefficient use of resources
Increased vulnerability to network outages
Difficulty in implementing effective security measures
Challenges in network expansion and adaptation to new technologies
Complications in troubleshooting and resolving network issues
To avoid suboptimal topology, network designers should consider:
Implementing hierarchical designs (core, distribution, access layers)
Using efficient topologies like hub-and-spoke for wide area networks
Incorporating redundancy and load balancing
Designing for scalability and future growth
Optimizing traffic flow based on application requirements
Balancing between centralized and distributed network functions
Lack of centralized management
Failing to consider the need for centralized network management can lead to operational inefficiencies and security issues. Characteristics of lack of centralized management:
Decentralized control: Network components and services are managed independently, without a unified approach.
Multiple management interfaces: Different tools or platforms are used to manage various parts of the network.
Inconsistent policies: Security, access, and configuration policies may vary across different network segments.
Limited visibility: No single point of oversight for the entire network infrastructure.
Manual processes: Reliance on manual configuration and updates rather than automated, centralized solutions.
Implementing centralized management often involves deploying network management systems (NMS) or software-defined networking (SDN) solutions that provide a single pane of glass for network operations. This approach allows businesses to more effectively manage their network infrastructure, improve security, and respond more quickly to changing business needs.
More Network Design Mistakes:
Neglecting security: Insufficient attention to implementing robust security policies and firewalls makes the network vulnerable to attacks.
Insufficient connection planning: Poor planning of connections between different environments (development, testing, production) can lead to performance and security issues.
Ignoring compliance requirements: Neglecting compliance requirements when designing the network can lead to problems with regulatory bodies in the future.
Inefficient IP address management: Poor IP addressing planning can lead to conflicts and complicate future expansion.
Lack of documentation: Insufficient or absent documentation of network design makes future maintenance and modification of the network difficult.
These mistakes highlight the importance of careful planning and involving experienced professionals when developing network designs for businesses.
Client Example
RetailNow: The Cost of a Flat Network Architecture
RetailNow is an eCommerce company that scaled from startup to mid-market in under three years. Their infrastructure grew alongside their business — reactively, with no underlying network design strategy. All services ran in a single flat VPC on AWS: the database, the payment processor, the public storefront, the internal admin panel, and development tooling.
When they began expanding operations into new regions and onboarding enterprise retail partners, the problems became critical. Integrating new services into the existing network required manual reconfiguration of routing tables and security groups across every environment — a multi-week process each time. A minor misconfiguration in a development workload caused a four-hour production outage during a promotional campaign. Compliance certification for a major retail partner was blocked pending a full network segmentation audit.
After a network redesign engagement with Gart Solutions — migrating to a segmented multi-region VPC architecture with separate environment subnets, centralized routing via Transit Gateway, and a Zero Trust security layer — RetailNow achieved the following:
✓
40% reduction in deployment time
✓
Zero environment-crossing incidents post-migration
✓
SOC 2 Type II certification achieved within 4 months
✓
Enterprise partner onboarding time reduced from 6 weeks to 11 days
Gart's 5-Layer Scalable Network Design Framework
After years of designing and redesigning cloud network architectures, we've developed an internal framework that we apply to every infrastructure engagement. It's not a rigid template — it's a mental model that ensures every critical concern is addressed before a single resource is provisioned.
1. Boundary & Perimeter LayerDefines the outer security perimeter — WAF, DDoS protection, public load balancers, CDN configuration, and ingress traffic control. Everything public-facing lives and terminates here.
2. Environment Segmentation LayerStrict separation of production, staging, and development environments into isolated VPCs or network segments with no default cross-environment routes. Promotes compliance readiness from day one.
3. Service Communication LayerDefines how internal services talk to each other — service mesh configuration, internal load balancers, private DNS, and least-privilege security group rules. Kubernetes networking (CNI plugins, network policies) is managed at this layer.
4. Data & Storage Access LayerGoverns how compute resources access databases, object storage, caches, and message queues. All data services live in private subnets with no public internet exposure, accessible only via defined routes.
5. Observability & Resilience LayerNetwork flow logs, traffic anomaly detection, cross-region health checks, and automated failover policies. You cannot manage what you cannot observe — this layer makes the network transparent.
Cloud Network Architecture Best Practices for AWS & Azure
Cloud providers give you powerful networking primitives — but they don't make architectural decisions for you. Here's how strong network design translates into the specific constructs available on the two dominant platforms.
AWS VPC Best Practices
Plan your CIDR block ranges to accommodate at least 3x your expected growth before provisioning — IP space cannot be easily reclaimed later.
Use separate VPCs per environment (prod, staging, dev) connected via AWS Transit Gateway for centralized routing and policy enforcement.
Deploy NAT Gateways per Availability Zone, not per region, to prevent cross-AZ data transfer costs and eliminate single points of failure.
Implement AWS Network Firewall at the VPC level for stateful packet inspection on east-west (service-to-service) traffic.
Use VPC Flow Logs exported to S3 or CloudWatch for forensic visibility and compliance audit trails.
Never expose databases or internal services to public subnets — use PrivateLink or VPC endpoints for AWS service access without traversing the public internet.
Azure Network Design Best Practices
Use Hub-and-Spoke topology via Azure Virtual WAN to centralize shared services (DNS, firewalls, monitoring) in a hub VNet while spoke VNets host workloads.
Apply Network Security Groups (NSGs) at the subnet level — not just at the VM NIC level — for defense in depth.
Leverage Azure Private Endpoint for PaaS services (Storage, SQL, CosmosDB) to keep traffic entirely within your virtual network.
Use Azure DDoS Protection Standard on all public-facing resources in production environments.
Implement Azure Firewall Premium for TLS inspection and IDPS on cross-region and hub egress traffic.
Zero Trust Network Architecture
Zero Trust is not a product — it is a network design philosophy that eliminates implicit trust based on network location. In a Zero Trust architecture, every service-to-service call is authenticated and authorized, regardless of whether both services are "inside" the network perimeter. This is implemented through service mesh technologies (Istio, Linkerd), mutual TLS (mTLS), and granular identity-based policy. According to Synergy Research Group, organizations adopting Zero Trust principles experience up to 50% fewer network-related security incidents within the first year of implementation.
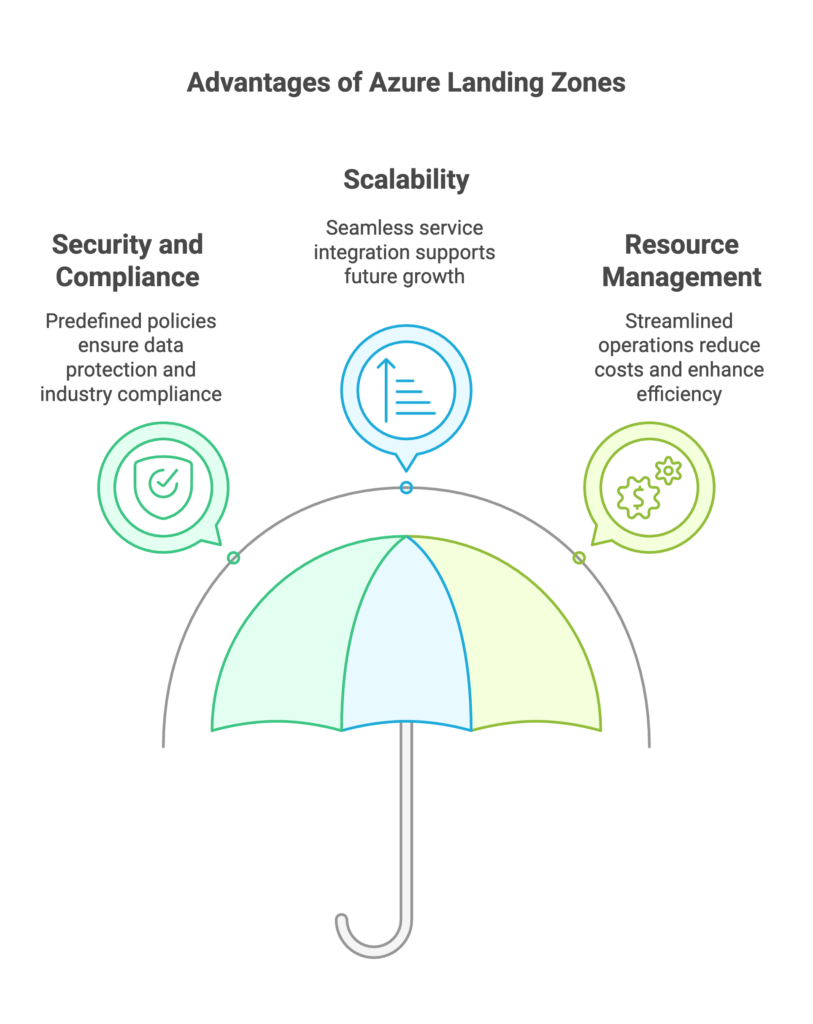
In Azure, network design is a key part of the Azure Landing Zones framework. This framework offers a comprehensive approach to designing network infrastructure, including:
Using a hub-and-spoke topology to centralize connections and simplify management.
Implementing security and management policies at the central hub level.
Segmenting the network into different environments (development, testing, production) through separate spoke networks.
Centralized management through Azure Network Manager.
Hub-and-spoke Network Topology
Azure Landing Zones utilize a hub-and-spoke network topology, which centralizes connectivity and simplifies management. In this design, a central hub network connects multiple spoke networks, each representing different environments such as development, testing, and production.
Each spoke network can be dedicated to different functions such as development, testing, or production. This design provides several advantages:
Centralized Security: The hub can enforce security policies and monitor traffic between spokes, ensuring that all communications are secure and compliant.
Simplified Management: By centralizing network management in the hub, organizations can reduce the complexity of their network operations. This makes it easier to manage connections and enforce policies across the entire network.
Flexible Scalability: New spokes can be added as needed without disrupting existing operations. This flexibility allows organizations to scale their infrastructure in response to changing business requirements.
In AWS, the recommended approach to network design includes:
Using Amazon VPC (Virtual Private Cloud) to create isolated network environments.
Implementing AWS Transit Gateway for centralized routing management between VPCs and on-premises networks.
Using AWS Control Tower for automated setup and management of multi-account environments.
Applying AWS Network Firewall for centralized network protection.
Both providers emphasize the importance of segmentation, scalability, centralized management, and security - precisely those aspects that, when neglected, lead to the typical mistakes described in the article.
This is how leading cloud platforms address the problems associated with typical network design mistakes and offer structured approaches to creating effective network architecture. This ties in well with the common mistakes discussed earlier, such as:
Flat network structure: Addressed by hub-and-spoke designs in Azure and VPC segmentation in AWS.
Insufficient segmentation: Solved through spoke networks in Azure and separate VPCs in AWS.
Ignoring scalability: Both platforms offer solutions that can easily scale with business needs.
Suboptimal topology: The recommended architectures from both providers aim to optimize network topology.
Lack of centralized management: Addressed by Azure Network Manager and AWS Control Tower.
Network Design Planning Checklist
Use this checklist before designing or redesigning any cloud network architecture. Each item represents a decision point that, if deferred, will cost significantly more to address later.
Planning AreaKey DecisionCommon MistakeIP & CIDR PlanningAllocate address space for 3x projected growthUnder-sized CIDR blocks requiring full VPC rebuildEnvironment SeparationIsolated VPCs for prod, staging, devSingle flat VPC across all environmentsMulti-Region StrategyActive-passive or active-active failover topologySingle-region deployment with no DR planVPC SegmentationPublic, private, and data subnets per AZAll resources in public subnetsSecurity PolicyLeast-privilege security groups and NACLsOpen inbound rules (0.0.0.0/0) on sensitive portsIAM & Network PolicyNetwork-level IAM conditions on resource accessIAM policies without VPC source conditionsMonitoring & ObservabilityFlow logs, anomaly detection, and alerting from day oneNetwork logging added only after an incidentDisaster Recovery TopologyDefined RTO/RPO targets with tested failover pathsNo tested DR procedure until a real outage occursNetwork Design Planning Checklist
Poor Network Design vs. Optimized Network Design
Dimension❌ Poor Network Design✅ Optimized Network DesignArchitectureFlat, single VPC for all workloadsSegmented, environment-isolated multi-VPCScalabilityManual scaling, frequent reconfigurationAuto-scaling with pre-allocated address spaceSecurityShared environments, broad firewall rulesZero Trust, least-privilege, mTLSComplianceCannot pass SOC 2 or PCI DSS without rearchitectingBuilt-in audit trails, segmentation, access logsDeployment VelocityBlocked by network access requests and routing bugsSelf-service, automated, via IaC (Terraform)CostHidden costs: unnecessary data transfer, redesign overheadOptimized routing, predictable traffic costsDisaster RecoveryNo tested failover — discovered during an incidentAutomated cross-region failover, tested quarterlyPoor Network Design vs. Optimized Network Design
When Should a Business Redesign Its Network Architecture?
The right time to redesign is always before you need to. But there are clear signals that architectural debt has accumulated to the point where a redesign is unavoidable:
Your engineering team spends more than 10% of sprint capacity managing network access, firewall rules, or routing issues — work that should be structural, not manual.
You are preparing for a compliance audit (SOC 2, ISO 27001, PCI DSS) and your current architecture cannot meet segmentation requirements without significant changes.
You are expanding into new geographic markets or cloud regions and your current network architecture does not support multi-region deployment natively.
You have experienced a security incident and the post-mortem identified lateral movement as a contributing factor — which is, by definition, a segmentation failure.
You are migrating from a monolith to microservices and your flat network cannot support the service-mesh and granular communication policies that distributed architecture requires.
A major enterprise client or partner has issued a security questionnaire and your network topology cannot satisfy their vendor assessment requirements.
As noted in Platform Engineering's infrastructure maturity research, most engineering organizations begin their platform engineering journey precisely because their network and infrastructure architecture can no longer support the velocity of delivery they need.
Gart Solutions · Network & Cloud Infrastructure
Need a Network Architecture That Scales With Your Business?
Gart Solutions designs, audits, and rebuilds cloud network architectures for growing technology companies. We help engineering teams move from reactive firefighting to intentional, scalable infrastructure — without slowing down delivery.
🔍
Network Architecture Audit
🏗️
VPC & Cloud Network Design
🛡️
Zero Trust Implementation
🌍
Multi-Region Deployment
📋
Compliance Readiness
⚡
DevOps & IaC Automation
Schedule a Free Infrastructure Consultation →
Conclusion
Planning a network design from the beginning is crucial for any growing business. It ensures that the infrastructure can scale efficiently, maintain security, and support the company's evolving needs. A well-designed network, guided by experienced DevOps engineers or cloud architects, can save businesses from costly reconfigurations and operational disruptions in the future.
@import url('https://fonts.googleapis.com/css2?family=Figtree:wght@400;500;600;700;800&display=swap');
.gart-infra-cta-section {
font-family: 'Figtree', sans-serif;
padding: 40px 0;
background-color: #FFFFFF;
width: 100%;
}
.gart-infra-cta-container {
background-color: #F2F4FB; /* Brand Light Periwinkle / Soft Blue background */
border-radius: 16px; /* Uniform soft-edged modular geometry */
max-width: 1100px;
margin: 0 auto;
padding: 48px 40px;
box-sizing: border-box;
box-shadow: 0 10px 30px rgba(55, 68, 185, 0.03);
}
.gart-infra-cta-tag {
color: #3744B9; /* Primary Royal Blue */
font-size: 0.85rem;
font-weight: 700;
text-transform: uppercase;
letter-spacing: 0.05em;
margin-bottom: 12px;
display: inline-block;
}
.gart-infra-cta-title {
font-size: 2rem;
font-weight: 800; /* Bold weight, sentence case for approachable precision */
color: #000000;
margin: 0 0 20px 0;
line-height: 1.25;
letter-spacing: -0.02em;
max-width: 800px;
}
.gart-infra-cta-desc {
font-size: 1.05rem;
font-weight: 400;
color: #222222;
line-height: 1.65;
margin: 0 0 32px 0;
max-width: 850px;
}
/* Core Competency Grid Layout with thin structural boundaries */
.gart-infra-services-grid {
display: grid;
grid-template-columns: repeat(3, 1fr);
gap: 16px;
margin-bottom: 40px;
}
.gart-infra-service-box {
background-color: #FFFFFF;
border: 1px solid #E2E6F5;
border-radius: 10px; /* Soft-edged square accentuation */
padding: 16px 20px;
display: flex;
align-items: center;
gap: 12px;
box-sizing: border-box;
box-shadow: 0 2px 8px rgba(55, 68, 185, 0.01);
}
.gart-infra-service-icon {
font-size: 1.2rem;
flex-shrink: 0;
line-height: 1;
}
.gart-infra-service-name {
font-size: 0.95rem;
font-weight: 600;
color: #000000;
margin: 0;
}
/* High contrast conversion button layout */
.gart-infra-btn-wrapper {
display: flex;
}
.gart-infra-btn {
display: inline-block;
background-color: #3744B9; /* High-contrast Primary Blue */
color: #FFFFFF !important;
text-decoration: none !important;
font-weight: 700;
font-size: 1.05rem;
padding: 16px 32px;
border-radius: 8px;
transition: background-color 0.2s ease, transform 0.2s ease;
box-shadow: 0 4px 14px rgba(55, 68, 185, 0.2);
border: none;
cursor: pointer;
}
.gart-infra-btn:hover {
background-color: #2A3499;
transform: translateY(-2px);
}
/* Responsive styling breakpoints */
@media (max-width: 992px) {
.gart-infra-services-grid {
grid-template-columns: repeat(2, 1fr);
gap: 14px;
}
}
@media (max-width: 768px) {
.gart-infra-cta-container {
padding: 32px 24px;
margin: 0 16px;
}
.gart-infra-cta-title {
font-size: 1.65rem;
}
.gart-infra-services-grid {
grid-template-columns: 1fr;
gap: 12px;
margin-bottom: 32px;
}
.gart-infra-btn-wrapper {
display: block;
}
.gart-infra

How organizations can move beyond lift-and-shift to orchestrate AI agents, enforce digital sovereignty, and realize measurable technology value in 2026 and beyond.
The Smart Fabric Paradigm
The global technology landscape in 2026 has crossed a decisive threshold. Organizations no longer ask whether to adopt cloud — they ask how to orchestrate it. The early promise of cloud computing — elasticity, cost reduction, hardware abstraction — has been largely delivered. What remains is a far more demanding challenge: transforming cloud infrastructure from a cost centre into a living, intelligent fabric that generates measurable business value.
Three converging forces are reshaping this landscape simultaneously. Artificial intelligence has graduated from experimental pilots to core operational agents embedded inside the software development life cycle. Infrastructure economics are being fundamentally disrupted by high-bandwidth memory shortages and the rise of GPU-optimized "NeoClouds." And a wave of rigorous regulation — led by the EU Cloud and AI Development Act — is forcing every enterprise to confront questions of digital sovereignty that were previously reserved for governments.
💡 Key Insight
The global cloud infrastructure market is projected to reach $2.4 trillion by 2032. Leaders who still treat cloud as a simple hosting environment will find themselves structurally disadvantaged compared to those treating it as a fabric for value, speed, and digital trust.
67%
Enterprises with AI/ML integrated by 2026
89%
Predicted AI/ML adoption by 2028
74%
Adoption of cloud-native architectures today
51%
Zero-trust security adoption in enterprises
How Agentic AI is Shaping Modern Cloud Adoption Strategy
The most consequential shift in cloud strategy for 2026 is not architectural — it is operational. AI agents are no longer browser-based copilots offering code suggestions. They are deep operational participants: making autonomous decisions about workload placement, detecting and remediating security vulnerabilities, optimising resource spend in real time, and self-documenting the systems they maintain.
This transition elevates human engineers from writing lines of code to running smart build systems — systems that self-correct, self-document, and route decisions through policy guardrails without waiting for human approval. The practical consequence is that cloud architecture must now incorporate an AI agent mesh: a dedicated infrastructure layer that mediates communication between AI agents and models, enforces governance, and provides secure interaction across the enterprise fabric.
From Co-Pilots to Autonomous Agents
Early AI tooling in the SDLC was fundamentally advisory. By contrast, 2026-era agents are granted bounded autonomy: they can rebalance Kubernetes clusters, right-size pods, trigger rollback procedures, and manage spot instance pools — all without opening a ticket. Teams that have deployed such agents report 50–70% reductions in infrastructure costs and dramatic reductions in mean time to recovery (MTTR).
At Gart, we build this agent mesh layer as a first-class concern in every cloud engagement, ensuring that automation is governed, auditable, and aligned with client-specific cost and compliance boundaries.
⚙️
Gart Perspective
Evolving DevOps: Integrating AI into Your Cloud Adoption Strategy
The migration from DevOps to AI-augmented operations is not a replacement of DevOps culture — it is its logical evolution. Continuous integration, infrastructure as code, and blameless post-mortems remain foundational. What changes is the execution layer: agents handle the repetitive, time-sensitive operations so engineers can focus on architecture, product, and innovation.
Cloud Adoption Strategy Frameworks: AWS, Azure, and Google
A successful cloud transformation requires a structured methodology to align business goals with technical execution. The three major hyperscalers have each developed comprehensive adoption frameworks, updated in 2026 to address AI integration, hybrid operations, and regulatory complexity.
AWS Cloud Adoption Framework (AWS CAF)
The AWS CAF organises capabilities into six perspectives: Business, People, Governance, Platform, Security, and Operations. The Business perspective ensures cloud investments are tied directly to digital ambitions with quantifiable outcomes. The Governance perspective is designed to minimise risk through policy automation and cloud financial management. For 2026, AWS has expanded its guidance around AI/ML workload readiness and model-agnostic deployment architectures, making it particularly well-suited for enterprises that need to interoperate across multiple AI providers.
Microsoft Azure Cloud Adoption Framework
Azure's CAF organises the journey into seven methodologies: Strategy, Plan, Ready, Adopt, Govern, Secure, and Manage. The first four phases are sequential and foundational; the last three operate in parallel throughout the cloud lifecycle. In 2026, Microsoft has added specific guidance for generative AI adoption and unifying data platforms for high-performance analytics — making Azure CAF the strongest framework for organisations deeply embedded in the Microsoft 365 and Dynamics ecosystem.
Google Cloud Adoption Framework
Google's framework identifies four themes: Lead, Learn, Scale, and Secure. The Lead theme balances top-down mandates with bottom-up momentum. The Scale theme is achieved by abstracting infrastructure through managed and serverless services. For 2026, Google has restructured its partner programme around real-world customer outcomes, with deep weighting on AI and analytics capabilities — reflecting its competitive strength in BigQuery and Vertex AI.
Framework Pillar
AWS CAF
Azure CAF
Google Cloud
Leadership & Alignment
Business & People
Strategy & Plan
Lead
Environmental Readiness
Platform
Ready
Scale
Technical Execution
Operations
Adopt
Learn
Governance & Risk
Governance
Govern
Secure
Security Operations
Security
Secure
Secure
Lifecycle Management
Operations
Manage
Scale
Applying the 7 Rs to Your Cloud Adoption Strategy
No single migration strategy fits every application. The 7 Rs framework remains the most practical tool for structuring portfolio-level migration decisions, balancing speed of delivery against long-term architectural value.
Strategy
Also Known As
Best For
Value Horizon
Rehost
Lift-and-Shift
Legacy VM workloads needing fast exit from data centre
Short-term
Relocate
Hypervisor Lift
VMware-based workloads without OS changes
Short-term
Replatform
Lift-and-Reshape
DB → managed service (RDS), containerisation of monoliths
Mid-term
Refactor
Re-architect
Monoliths requiring cloud-native transformation to microservices
Long-term
Repurchase
Drop-and-Shop
On-premise CRM/ERP → SaaS (e.g. Salesforce, Workday)
Mid-term
Retire
Decommission
Applications that no longer deliver business value
Immediate
Retain
Revisit
Workloads with complex compliance or latency dependencies
Deferred
The critical discipline is portfolio segmentation: mapping each application against business criticality, refactoring cost, and regulatory sensitivity before assigning an R-strategy. At Gart, our IT Audit process delivers this segmentation as a structured output — giving leadership a clear migration backlog with effort, risk, and cost estimates before a single workload moves.
Microservices in Cloud Adoption Strategy: When to Refactor
Refactoring to microservices is the most transformative — and most misapplied — strategy in the portfolio. For large, complex applications requiring high agility and independently scalable components, microservices deliver genuine resilience and deployment velocity. However, for small or simple applications, the operational overhead of a distributed system — service discovery, inter-service authentication, distributed tracing, and eventual consistency — significantly outweighs the benefit. The migration strategy must match the application's complexity, not the architecture's prestige.
Digital Sovereignty: The Regulatory Dimension of Cloud Strategy
By 2026, cloud strategy and geopolitical risk management have converged. The EU Cloud and AI Development Act, proposed by the European Commission in Q1 2026, seeks to harmonise cloud architecture requirements across member states and structurally reduce European dependency on US-headquartered hyperscalers — which currently control over 70% of the market.
For enterprises, the operative concern is the US CLOUD Act: American authorities retain legal authority to request access to data held by US-incorporated cloud providers, regardless of where the data is physically stored. This creates a jurisdictional exposure that European regulators are moving decisively to address.
$80B
Sovereign cloud IaaS spending forecast for 2026
35.6%
Year-over-year increase in sovereign cloud spend
20%
Current workloads shifting from global to local providers (Gartner)
Region
2025 Spend (USD M)
2026 Spend (USD M)
2027 Spend (USD M)
China
$37,539
$47,379
$58,544
North America
$12,667
$16,394
$21,127
🇪🇺 Europe
$6,868
$12,587
$23,118
Mature Asia/Pacific
$851
$1,593
$3,155
Middle East & Africa
$132
$250
$515
Global Total
$59,300
$80,427
$110,609
Europe's sovereign cloud spending is forecast to nearly double in a single year — the fastest regional acceleration globally. AWS, IBM, and a growing cohort of EU-native providers have responded with sovereign cloud offerings specifically designed to maintain data residency and governance authority within the European Union.
🔒
Action Point
For European Enterprises
Conduct a jurisdictional exposure audit across your workload portfolio. Classify data by regulatory sensitivity and map it against provider sovereignty commitments. For regulated industries — energy, finance, healthcare, telecoms — default to sovereign-compliant deployments for any data touching EU citizens.
FinOps 2026: From Cost Cutting to Technology Value Management
Cloud financial management has undergone a structural transformation. What began as a practice of turning off unused virtual machines has evolved into a comprehensive discipline spanning SaaS, data centres, licensing, and AI infrastructure. The State of FinOps 2026 report reveals that 98% of practitioners now manage AI spend as a core part of their remit — reflecting the degree to which AI infrastructure has become inseparable from cloud budgeting.
Shift Left, Shift Up
Two structural shifts are reshaping how financial accountability operates within engineering organisations. "Shift Left" embeds cost awareness directly into the SDLC: engineers and architects estimate the spend impact of design decisions before deployment, preventing expensive patterns from entering production. "Shift Up" elevates FinOps leaders to participate in provider negotiations and multi-year investment decisions at the executive level — making financial fluency a core engineering leadership competency, not a finance department afterthought.
The underlying principle is that every workload must have an owner and every cloud dollar must map to a unit economic metric: cost-per-customer, cost-per-transaction, cost-per-model-run. This transforms cloud spend from a lumpy line item into a predictable, decision-driven signal.
AI-Driven Autonomous FinOps Agents
Manual cost management at cloud scale is no longer viable. The 2026 generation of autonomous FinOps agents handles continuous cost diagnostics, real-time anomaly detection, Kubernetes rebalancing, pod right-sizing, and spot instance management — without human approval gates. These agents translate thousands of lines of cost and usage reports into natural-language insights tailored to specific personas, from the CFO to the site reliability engineer.
Agent Type
Core Focus
Key Capability in 2026
X-Ray / Diagnostic
Financial Health Checks
Surfaces inefficiencies in under 30 seconds
Governance
Budget Drift & Tag Hygiene
Automates root-cause analysis and ownership assignment
Optimisation
Rate & Resource Management
Executes strategies 24/7 without human approval
Reporting
Persona-Specific Insights
Generates context-ready reports for CFO to SRE
GreenOps and Sustainable Cloud Architecture
Sustainability has moved from a secondary ESG reporting obligation to a primary architectural constraint. The surge in AI-driven compute demand has placed cloud infrastructure at a critical environmental junction: operational growth must be structurally decoupled from carbon output. GreenOps — the operational discipline of managing cloud workloads for carbon efficiency — is the mechanism for achieving this decoupling.
Carbon-Aware Computing
The most impactful development in 2026 is the operationalisation of carbon-aware workload scheduling. Non-critical batch processing — data backups, model training runs, analytics pipelines — is shifted in time and geography to align with moments when the local power grid is drawing the highest proportion of renewable energy. Hyperscalers now provide real-time carbon intensity telemetry that feeds directly into orchestration layers, enabling fluid, environmentally-responsive infrastructure decisions.
Green AI and Efficient Hardware
The energy cost of generative AI training and inference is substantial. Technical leaders are mitigating this through purpose-built AI accelerators and ARM-based architectures that deliver significantly better performance per watt than general-purpose hardware. Combined with 100% renewable energy contracts and advanced liquid cooling techniques, modern hyperscale data centres now achieve Power Usage Effectiveness (PUE) ratios at or below 1.1 — up to five times more energy-efficient than traditional on-premise setups.
🌱
Carbon Impact
Carbon Impact of Cloud Migration
Moving from legacy on-premise infrastructure to a modern cloud architecture can reduce a company's digital carbon footprint by up to 80%. This is not a marginal efficiency gain — it is a structural transformation that positions cloud migration as both an economic and an environmental imperative.
Sustainability Dimension
Key 2026 Metric
Strategic Target
Infrastructure
Carbon Intensity (kg CO₂e / workload)
−40% Year-over-Year
Model Efficiency
Energy per Training Epoch
≤ Baseline − 25%
Application Efficiency
Joules per Inference
≤ 0.5 J / Inference
Governance
% Workloads under GreenOps
90%
Data Centres
Power Usage Effectiveness (PUE)
1.1 or lower
AWS vs Azure vs Google Cloud: Choosing the Right Foundation
The hyperscaler decision in 2026 is less about feature parity — all three offer comprehensive services — and more about ecosystem alignment and strategic centre of gravity. The right choice depends on where your organisation's heaviest technical investments already lie, and where you intend to build your AI and data capabilities.
AWS: Maximum Breadth and Flexibility
AWS retains market leadership at approximately 29–30% share, distinguished by its ecosystem depth — over 250 services, the broadest global region footprint, and the most mature model-agnostic AI strategy. It is the default choice for organisations requiring maximum configurability, large-scale B2C platforms, or multi-cloud portability. The tradeoff is complexity: AWS pricing requires dedicated management attention, and service sprawl is a real operational risk for teams without disciplined governance.
Azure: Enterprise Integration and Hybrid Excellence
Azure is the natural home for organisations already running Microsoft 365, Teams, and Active Directory. Its hybrid story — delivered through Azure Arc, which extends unified governance to on-premises and edge environments — remains unmatched. The Azure Hybrid Benefit provides compelling cost advantages for organisations with existing Microsoft licensing. Azure AI is oriented toward making machine learning accessible to business analysts and non-specialist developers, making it the strongest platform for enterprise-wide AI democratisation.
Google Cloud: Data, Analytics, and Cloud-Native Velocity
GCP excels where data is the primary strategic asset. BigQuery's serverless analytics engine and Vertex AI's native Gemini multimodal models make it the preferred platform for data-heavy applications, recommendation engines, and predictive analytics. Google's private global fibre network delivers exceptionally low latency, and its leadership in Kubernetes — the platform originated at Google — provides unmatched depth for container-native architectures. The tradeoff is a smaller enterprise sales footprint compared to AWS and Azure.
Gart's Framework
Hyperscaler Decision Framework
We advise clients to evaluate four dimensions: existing ecosystem investment (Microsoft, AWS, or Google native tooling), AI and data architecture requirements, hybrid and edge needs, and regulatory sovereignty obligations. In practice, most enterprises with complex environments benefit from a multi-cloud strategy — not for every workload, but to avoid strategic dependency on a single provider for mission-critical capabilities.
Implementation Roadmap: Three Phases to Intelligent Cloud
Successful cloud transformation follows a disciplined, phased approach that integrates technology, financial governance, and sustainability objectives from the start — not as afterthoughts.
1
Months 1–3
Assessment & Strategic Alignment
Conduct a full IT portfolio audit and map workloads against the 7 Rs framework. Define business motivations — cost optimisation, agility, regulatory compliance — and build a quantified business case. Identify jurisdictional risk across the workload portfolio and evaluate sovereign cloud requirements. Form platform engineering teams and establish the cloud centre of excellence (CCoE).
2
Months 4–6
Foundation Building
Establish the landing zone: network architecture, security policies, and governance controls. Implement Infrastructure as Code using Terraform or Pulumi for reproducibility. Deploy multi-account management via AWS Control Tower or Azure Landing Zones. Activate unified cost and carbon visibility tooling. Begin AI infrastructure standardisation and deploy the initial agentic mesh for model orchestration.
3
Months 7–12+
Migration, Modernisation & Optimisation
Execute workload migration in prioritised waves, beginning with quick-win applications. Define cut-over and rollback plans for each wave. Modernise high-value workloads from monoliths to microservices or serverless patterns. Activate autonomous FinOps and GreenOps agents for continuous optimisation. Transition from reactive reporting to proactive cost and carbon engineering embedded in the SDLC.
Conclusion: Scaling Smarter in the AI Era
The 2026 cloud adoption strategy is no longer a technology project — it is a business transformation programme with technology at its core. The organisations that thrive will not simply be those that move workloads faster, but those that build cloud environments designed for three simultaneous imperatives: intelligence (AI agents embedded in operations), sovereignty (data governance aligned with jurisdictional reality), and value (every cloud dollar mapped to a measurable business outcome).
The good news is that the frameworks, tools, and expertise to execute this transformation exist today. The 7 Rs provide a structured migration decision model. The hyperscaler CAFs provide proven organisational and technical scaffolding. Autonomous FinOps and GreenOps agents make it possible to manage complexity at a scale that was previously beyond reach. What separates leaders from laggards is not access to tools — it is the discipline to apply them with strategic intentionality.
At Gart, we help engineering teams and technology leaders navigate this complexity — from the initial IT audit and workload assessment through to full production migration and ongoing optimisation. Whether you're rearchitecting a SaaS platform, establishing a sovereign cloud footprint in Europe, or building the FinOps function your AI workloads demand, we bring the technical depth and operational experience to deliver outcomes that matter.

Cloud adoption is a crucial consideration for many enterprises. With the need to migrate from on-premises infrastructure to the cloud, businesses seek effective frameworks to streamline this transition. One such framework gaining traction is the Terraform Framework.
[lwptoc]
This article delves into the details of the Terraform Framework and its significance, particularly for enterprise-level cloud adoption projects. We will explore the background behind its adoption, the Cloud Adoption Framework for Microsoft, the concept of landing zones, and the four levels of the Terraform Framework.
https://youtu.be/vzCO-h4a9h4
Background and Adoption Strategy
Many large enterprises face the challenge of migrating their infrastructure from on-premises environments to the cloud. In response to this, Microsoft developed the Cloud Adoption Framework (CAF) as a strategic guide for customers to plan, adopt, and implement cloud services effectively.
Let's dive deeper into the components and benefits of the Terraform Framework within the Cloud Adoption Framework.
Understanding the Azure Cloud Adoption Framework (CAF)
The Cloud Adoption Framework for Microsoft (CAF) is a comprehensive framework that assists customers in defining their cloud strategy, planning the adoption process, and continuously implementing and managing cloud services. It covers various aspects of cloud adoption, from migration strategies to application and service management in the cloud. To gain a better understanding of this framework, it is essential to explore its core components.
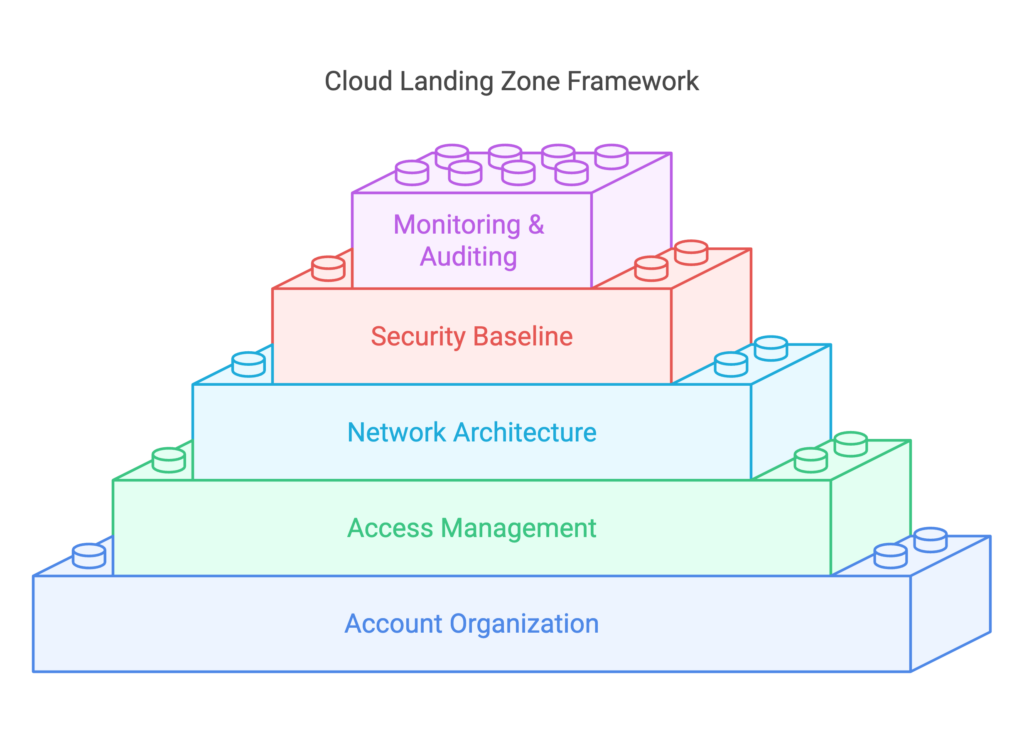
Landing Zones
A fundamental component of the CAF is the concept of landing zones. A landing zone represents a scaled and secure Azure environment, typically designed for multiple subscriptions. It acts as the building block for the overall infrastructure landscape, ensuring proper connectivity and security between different application components and even on-premises systems. Landing zones consist of several elements, including security measures, governance policies, management and monitoring services, and application-specific services within a subscription.
CAF and Infrastructure Organization
The Microsoft documentation on CAF outlines different approaches to cloud adoption based on the size and complexity of an organization. Small organizations utilizing a single subscription in Azure will have a different adoption approach compared to large enterprises with numerous services and subscriptions. For enterprise-level deployments, an organized infrastructure landscape is crucial. This includes creating management groups and subscription organization, each serving specific governance and security requirements. Additionally, specialized subscriptions, such as identity subscriptions, management subscriptions, and connectivity subscriptions, are part of the overall landing zone architecture.
? Discover the power of Caf-Terraform, a revolutionary framework that takes your infrastructure management to the next level. Let's dive in!
The Four Levels of the Terraform Framework
The Terraform Framework, an open-source project developed by Microsoft architects and engineers, simplifies the deployment of landing zones within Azure. It consists of four main components: rover, models, landing zones, and launchpad.
a. Rover:
The rover is a Docker container that encapsulates all the necessary tools for infrastructure deployment. It includes Terraform itself and additional scripts, facilitating a seamless transition to CI/CD pipelines across different platforms. By utilizing the rover, teams can standardize deployments and avoid compatibility issues caused by different Terraform versions on individual machines.
b. Models:
The models represent cloud adoption framework templates, hosted within the Terraform registry or GitHub repositories. These templates cover a wide range of Azure resources, providing a standardized approach for deploying infrastructure components. Although they may not cover every single resource available in Azure, they offer a strong foundation for most common resources and are continuously updated and supported by the community.
c. Landing Zones:
Landing zones represent compositions of multiple resources, services, or blueprints within the context of the Terraform Framework. They enable the creation of complex environments by dividing them into manageable subparts or services. By modularizing landing zones, organizations can efficiently deploy and manage infrastructure based on their specific requirements. The Terraform state file generated from the landing zone provides valuable information for subsequent deployments and configurations.
d. Launchpad:
The launchpad serves as the starting point for the Terraform Framework. It comprises scripts and Terraform configurations responsible for creating the foundational components required for all other levels. By deploying the launchpad, organizations establish storage accounts, keywords, and permissions necessary for storing and managing Terraform state files for higher-level deployments.
Understanding the Communication between Levels
To ensure efficient management and organization, the Terraform Framework promotes a layered approach, divided into four levels:
Level Zero: This level represents the launchpad and focuses on establishing the foundational infrastructure required for subsequent levels. It involves creating storage accounts, setting up subscriptions, and permissions for managing state files.
Level One: Level one primarily deals with security and compliance aspects. It encompasses policies, access control, and governance implementation across subscriptions. The level one pipeline reads outputs from level zero but has read-only access to the state files.
Level Two: Level two revolves around network infrastructure and shared services. It includes creating hub networks, configuring DNS, implementing firewalls, and enabling shared services such as monitoring and backup solutions. Level two interacts with level one and level zero, retrieving information from their state files.
Level Three and Beyond: From level three onwards, the focus shifts to application-specific deployments. Development teams responsible for application infrastructure, such as Kubernetes clusters, virtual machines, or databases, engage with levels three and beyond. These levels have access to state files from the previous levels, enabling seamless integration and deployment of application-specific resources.
Simplifying Infrastructure Deployments
In order to create new virtual machines for specific applications, we can leverage the power of Terraform and modify the configuration inside the Terraform code. By doing so, we can trigger a pipeline that resembles regular Terraform work. This approach allows us to have more control over the deployment and configuration of virtual machines.
Streamlining Service Composition and Environment Delivery
When discussing service composition and delivering a complete environment, this layered approach in Terraform can be quite beneficial. We can utilize landing zones or blueprint models at different levels. These models have input variables and produce output variables that are saved into the Terraform state file. Another landing zone or level can access these output variables, use them within its own logic, compose them with input variables, and produce its own output variables.
Organizing Teams and Repositories
This layered approach, facilitated by Terraform, helps to organize the relationship between different repositories or teams within an organization. Developers or DevOps professionals responsible for creating landing zones or cleaning zones can work locally with the Rover container in VS Code. They write Terraform code, compose and utilize modules, and create landing zone logic.
Separation of Logic and Configuration
The logic and configuration in the Terraform code are split into separate files, similar to regular Terraform practices. The logic is stored in .tf and .tfvars files, while the configuration is stored in .tfvars files, which can be organized into different environments. This separation allows for better management and maintainability.
Empowering Application Teams
Within an organization, different teams can be responsible for different aspects of the infrastructure. An experienced Azure team can define the organization's standards and write the landing zone logic using Terraform. They can provide examples of configuration files that application teams can use. By offloading the configuration files to the application teams, they can easily create infrastructure for their applications without directly involving the operations team.
Standardization and Unification
This approach allows for the standardization and unification of infrastructure within the organization. With the use of modules in Terraform, teams don't have to start from scratch but can reuse existing code and configurations, creating a consistent and streamlined infrastructure landscape.
Challenges and Considerations
Working with Terraform and the Caf-terraform framework may have some complexities. For example, the Rover tool is not able to work with managed identities, requiring the management of service principals in addition to containers and managed identities. Additionally, there may be some bugs in the modules that need to be addressed, but the open-source nature of the framework allows for contributions and improvements. Understanding the framework and its intricacies may take some time due to the documentation being spread across multiple reports and components.
Key components and features of CAF Terraform:
ComponentDescriptionCloud Adoption Framework (CAF)Microsoft's framework that provides guidance and best practices for organizations adopting Azure cloud services.TerraformOpen-source infrastructure-as-code tool used for provisioning and managing cloud resources.Azure Landing ZonesPre-configured environments in Azure that provide a foundation for deploying workloads securely and consistently.Infrastructure as Code (IaC)Approach to defining and managing infrastructure resources using declarative code.Standardized DeploymentsEnsures consistent configurations and deployments across environments, reducing inconsistencies and human errors.ModularityOffers a modular architecture allowing customization and extension of the framework based on organizational requirements.CustomizabilityEnables organizations to adapt and tailor CAF Terraform to their specific needs, incorporating existing processes, policies, and compliance standards.Security and GovernanceEmbeds security controls, network configurations, identity management, and compliance requirements into infrastructure code to enforce best practices and ensure secure deployments.Ongoing ManagementSimplifies ongoing management, updates, and scaling of Azure landing zones, enabling organizations to easily make changes to configurations and manage the lifecycle of resources.Collaboration and AgilityFacilitates collaboration among teams through infrastructure-as-code practices, promoting agility, version control, and rapid deployments.Documentation and CommunityComprehensive documentation and resources provided by Microsoft Azure, along with a vibrant community offering tutorials, examples, and support for leveraging CAF Terraform effectively.This table provides an overview of the key components and features of CAF Terraform
Conclusion: Azure Cloud Adoption Framework
The Terraform Framework within the Cloud Adoption Framework (CAF) offers enterprises a powerful toolset for cloud adoption and migration projects. By leveraging the modular structure of landing zones and adhering to the layered approach, organizations can effectively manage infrastructure deployments in Azure. The Terraform Framework's components, including rover, models, landing zones, and launchpad, contribute to standardization, automation, and collaboration, leading to successful cloud adoption and improved operational efficiency.
As organizations embrace the cloud, the Caf-terraform framework provides a layered approach to managing infrastructure and deployments. By separating logic and configuration and leveraging modules, it allows for standardized and unified infrastructure across teams and repositories. This framework simplifies and optimizes the transition from on-premises to the cloud, enabling enterprises to harness the full potential of Azure's capabilities.
Empower your team with DevOps excellence! Streamline workflows, boost productivity, and fortify security. Let's shape the future of your software development together – inquire about our DevOps Consulting Services.