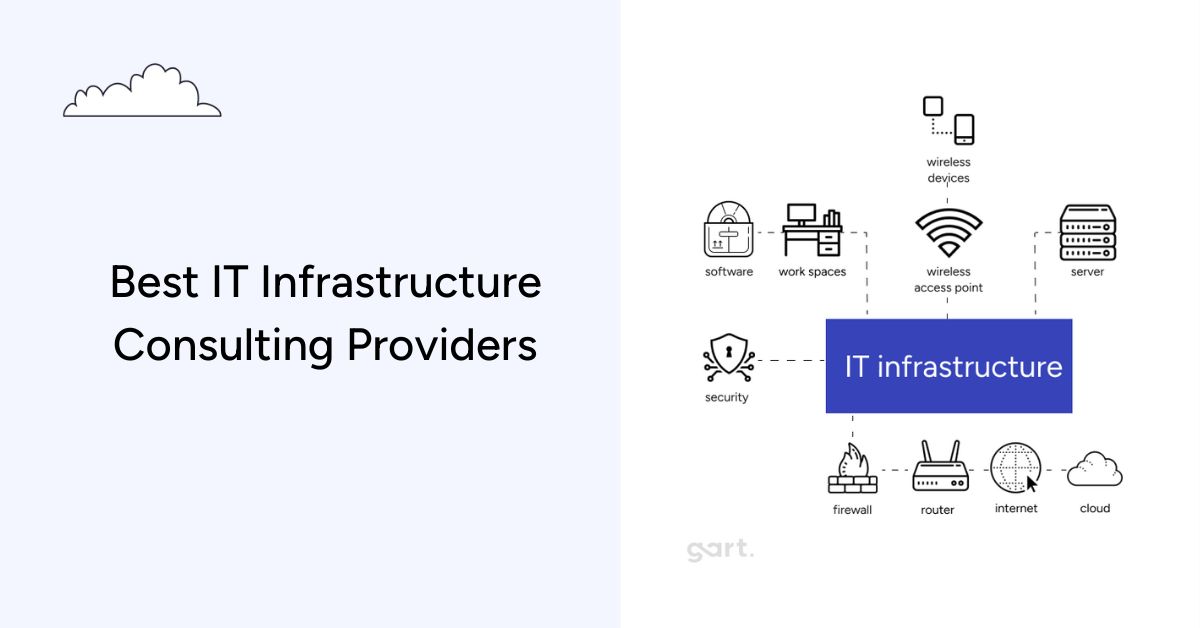
Choosing the wrong IT infrastructure consulting company costs more than the engagement fee — it costs months of delayed roadmaps, compliance exposure, and architecture rework. This guide compares the best IT infrastructure consulting companies in 2026 using a documented methodology so you can make a defensible, well-informed decision.
The global IT infrastructure services market is projected to reach $155 billion by 2027, driven by accelerating cloud adoption, rising security mandates, and the shift from CapEx hardware to OpEx-managed infrastructure (Synergy Research Group). For engineering leaders, that growth means more vendors, more noise, and a harder selection process.
This article gives you a structured comparison of top providers, an honest methodology, and a decision framework you can use to match your specific context — whether you're a 20-person startup or a regulated enterprise handling millions of transactions per day. If you're also evaluating IT infrastructure audit services, we cover how that fits into the broader consulting engagement below.
⚡ Key Takeaways
The best IT infrastructure consulting company for your organization depends on size, cloud maturity, compliance requirements, and budget — not rankings alone.
Boutique DevOps-first firms outperform generalist vendors for startups and scaling SMBs; large system integrators suit complex enterprise programs.
Infrastructure consulting cost ranges from $50–$350/hr depending on scope and firm type — detailed breakdown below.
Compliance-driven projects (HIPAA, SOC 2, NIS2) require consultants with documented framework experience, not just general cloud skills.
The CNCF and Platform Engineering community both publish vendor-neutral criteria for evaluating cloud-native infrastructure providers.
Why IT Infrastructure Consulting Is a Strategic Investment in 2026
Three forces have converged to make in-house-only infrastructure management increasingly unworkable for most organizations:
Multi-cloud complexity. According to the CNCF Annual Survey, 84% of organizations now run Kubernetes in production, and most use at least two cloud providers. Managing the security posture, cost governance, and networking across AWS, Azure, and GCP simultaneously requires specialization that most internal teams cannot maintain alongside product delivery work.
Compliance acceleration. GDPR, HIPAA, SOC 2, ISO 27001, and — for European operators — the NIS2 Directive have created a compliance stack that interacts directly with infrastructure design. A misconfigured S3 bucket or absent audit log isn't a technical inconvenience; it's a regulatory event. Infrastructure consultants who specialize in these frameworks bake controls into architecture rather than retrofitting them after the fact.
Cost optimization as a board-level concern. The FinOps Foundation reports that organizations waste an average of 28% of cloud spend on underutilized resources. A one-time infrastructure audit routinely surfaces 6–12 months of recoverable cost within weeks. Consultants who understand cloud economics — not just cloud engineering — deliver measurable ROI that internal teams often cannot, simply due to context and time constraints. For more on this, see our guide to cloud computing and cost optimization.
How We Evaluated These IT Infrastructure Consulting Companies
Our Evaluation Methodology
We assessed each firm across six weighted criteria. Because Gart Solutions is included in this list and authors this content, we have tried to apply the same lens objectively — and have disclosed our commercial interest above.
Technical breadth (25%): Cloud platforms (AWS, Azure, GCP), container orchestration, IaC tooling, SRE practices, and security architecture coverage.
Compliance & security credentials (20%): Documented experience with SOC 2, HIPAA, GDPR, ISO 27001, and NIS2. Relevant certifications held by engineers.
Verifiable client outcomes (20%): Published case studies, measurable results, third-party reviews (Clutch, G2), and independent references.
Delivery model fit (15%): Suitability for startup vs. enterprise, on-site vs. remote, project vs. retainer engagements.
Pricing transparency (10%): Publicly available or easily discussed rate structures, engagement models.
Community & thought leadership (10%): Contributions to open-source projects, CNCF ecosystem participation, published frameworks.
Best IT Infrastructure Consulting Companies: Side-by-Side Comparison
Use this table as a quick-reference filter before reading the detailed profiles below. Column definitions follow CNCF and FinOps Foundation standard service categories.
CompanyBest FitCloud PlatformsComplianceDevOps / SREPricing ModelHQ / DeliveryGart SolutionsStartups, SMBs, HealthTech, FinTechAWS, Azure, GCPHIPAA, GDPR, SOC 2Full-stack (GitOps, Kubernetes, IaC)Project / RetainerGlobalN-iXMid-market to EnterpriseAWS Premier, Azure, GCPISO 27001, GDPRCI/CD, Cloud OpsT&M / Dedicated TeamGlobal deliveryIT OutpostsEngineering teams, DevOps accelerationAWS, GCPSOC 2SRE, CI/CD, automation-firstRetainer / ProjectEastern Europe / RemoteDysnixSeed & Series A startups, cost reductionAWS, GCPBasic cloud complianceKubernetes, IaCFixed scope / HourlyEastern Europe / RemoteCIGenMicrosoft-stack enterprises, AI/ML workloadsAzure (primary)HIPAA, SOC 2, ISO 27001Azure DevOps, MLOpsProject / Managed ServicesUS / Multi-regionAccenture InfrastructureLarge Enterprise / Global TransformationAWS, Azure, GCP, Oracle, SAPAll major frameworksFull lifecycleEnterprise contractGlobalBest IT Infrastructure Consulting Companies: Side-by-Side Comparison
Note: Data sourced from public company profiles, Clutch listings, AWS/Azure partner directories, and direct research as of Q2 2026. Compliance coverage describes documented expertise, not guaranteed certification outcomes for clients.
Detailed Provider Profiles
Reviewed by the Gart team
1. Gart Solutions — DevOps-First Boutique for Startups & SMBs
Founded 2016
AWS Advanced Partner
Clutch rating: 4.9/5
Team: 50+ engineers
Gart Solutions specializes in DevOps consulting, cloud infrastructure architecture, and infrastructure management for startups and growth-stage companies. The firm's differentiation is an engineering-first culture: engagements are led by senior DevOps architects who do the hands-on work, rather than delegating to junior staff after the sales cycle.
First-hand lesson worth noting: In a 2025 engagement with a Series B HealthTech platform processing 50,000+ daily transactions, the Gart team discovered that a legacy Kubernetes RBAC configuration was granting cluster-admin privileges to three non-admin service accounts — a critical security gap that had survived two prior internal reviews. Remediation took 4 hours. The gap had existed for 14 months.
Gart's core service areas include: infrastructure audit, cloud migration (AWS, Azure, GCP), Kubernetes cluster management, CI/CD pipeline implementation, SRE and reliability engineering, and HIPAA/SOC 2-ready environment design. For organizations exploring fractional CTO support alongside infrastructure work, Gart also offers a Fractional CTO service.
Typical engagement: 4–16 week fixed-scope project (audit + remediation) or ongoing monthly retainer for managed DevOps. Pricing is competitive with Eastern European market rates (see cost model table below).
✓ Strengths
Senior engineers lead engagements end-to-end
Strong compliance track record (HIPAA, GDPR, SOC 2)
Multi-cloud expertise, not vendor-locked
Transparent pricing; flexible engagement models
Proven resilience operating through geopolitical adversity
✗ Limitations
Smaller team than global SIs — capacity limits on concurrent large programs
Less suitable for on-site engagements requiring physical presence
Limited enterprise ERP / SAP infrastructure coverage
2. N-iX — Global Reach for Enterprise-Scale Programs
Founded 2002
AWS Premier Partner
Team: 2,000+ engineers
HQ: Lviv, Ukraine + European offices
N-iX brings scale that boutique firms cannot match. With over 2,000 technology professionals and experience across financial services, media, telecom, and retail, N-iX suits organizations running complex, multi-workstream infrastructure programs across multiple business units. Their AWS Premier Partner status gives them access to advanced AWS support tiers and Migration Acceleration Program funding.
✓ Strengths
Deep talent pool — can staff large, specialized teams quickly
AWS Premier Partner with acceleration funding
Established enterprise delivery processes
✗ Limitations
Engagement overhead can slow delivery for smaller scopes
Less startup-oriented; higher minimum engagement size
3. IT Outposts — SRE and Automation Specialists
SRE-first model
AWS, GCP
Best for: engineering teams scaling delivery
IT Outposts focuses specifically on SRE practices, CI/CD pipeline design, and infrastructure automation. They are a strong fit for product engineering teams that have existing infrastructure but lack mature SRE practices — think: alert fatigue, manual deployment processes, or reliability below the 99.9% threshold. Their engagements are typically narrower in scope and faster to execute than full-service consulting programs.
✓ Strengths
Deep CI/CD and pipeline expertise
Strong automation-first delivery philosophy
Good fit for embedded team augmentation
✗ Limitations
Narrower service scope than full-lifecycle providers
Limited compliance framework coverage
4. Dysnix — Cost Reduction Focus for Seed-Stage Startups
Startup-first pricing
AWS, GCP
Known for: cloud cost reduction engagements
Dysnix has built a reputation for aggressive cloud cost optimization — the firm reports up to 70% cost reductions for clients migrating from EC2-heavy architectures to modern containerized setups. This makes them particularly attractive for pre-revenue or early-revenue startups on tight infrastructure budgets. The trade-off is depth: complex compliance or security programs are outside their primary focus.
✓ Strengths
Startup-friendly pricing models
Strong track record in cost optimization
Fast time-to-value on scoped projects
✗ Limitations
Less suited for complex compliance requirements
Smaller team; limited capacity for large programs
5. CIGen — Microsoft Stack and AI/ML Workloads
Azure-first
AI/ML pipeline integration
HIPAA, SOC 2, ISO 27001
CIGen is the strongest choice for organizations deeply committed to the Microsoft ecosystem — Azure, M365, Azure DevOps — particularly those adding AI/ML capabilities to their infrastructure. Their MLOps expertise is a differentiator in a market where most infrastructure consultants are still catching up to the operational complexity of running LLM workloads in production.
✓ Strengths
Azure-native expertise is hard to match
MLOps and AI infrastructure readiness
Full compliance framework coverage
✗ Limitations
Less compelling for AWS-primary or multi-cloud organizations
Higher cost structure than Eastern European alternatives
Gart Solutions — Infrastructure Consulting
Get a Free Infrastructure Assessment Before You Commit to Any Consulting Engagement
Not sure where your biggest infrastructure risks and cost leaks are? Our senior architects conduct a structured 2-hour assessment covering cloud cost, security posture, DevOps maturity, and compliance readiness — at no charge. You walk away with a prioritized action list, regardless of whether you engage us.
Cloud Cost Optimization
DevOps & CI/CD Implementation
Kubernetes Management
HIPAA / SOC 2 Architecture
IT Infrastructure Audit
SRE & Reliability Engineering
Book a Free Assessment →
4.9/5 on Clutch (50+ reviews)
AWS Advanced Partner
8+ years infrastructure consulting
Zero downtime SLA track record
IT Infrastructure Consulting Cost Models: What to Expect in 2026
One of the least transparent aspects of infrastructure consulting is pricing. Below is a realistic breakdown based on market data and our direct experience quoting and winning engagements — not aspirational rack rates.
Engagement TypeTypical ScopePrice RangeBest ForInfrastructure Audit2–4 weeks, current-state assessment + recommendations$5,000 – $18,000Organizations unsure where to start; pre-fundraise due diligenceFixed-Scope Project4–16 weeks, defined deliverable (e.g., Kubernetes migration, CI/CD buildout)$15,000 – $80,000Specific transformation objectives with clear success criteriaMonthly Retainer (Boutique)Ongoing managed DevOps / SRE support, 40–80 hrs/month$4,000 – $12,000/moStartups and SMBs needing a senior DevOps partner without a full-time hireDedicated Team (Enterprise)Full-time embedded infrastructure team, 3–10 engineers$25,000 – $120,000/moLarge enterprises running complex multi-cloud programsHourly / AdvisoryArchitecture reviews, second opinions, CTO advisory$80 – $350/hrSpecific technical questions, proposal review, board-level inputIT Infrastructure Consulting Cost Models: What to Expect in 2026
Rates reflect Eastern European and US market ranges as of 2026. Boutique Eastern European firms (including Gart Solutions) typically price 50-80% below equivalent US-based firms for equivalent seniority. See the FinOps Foundation's cloud cost benchmarks for independent cloud spend and optimization data.
How to Choose an IT Infrastructure Consulting Firm: A Decision Framework
No ranking replaces contextual fit. Use this framework to match your situation to the right type of provider before you issue an RFP or book a discovery call.
Match Your Context to the Right Provider Type
Startup (pre-Series B)
Prioritize cost efficiency, speed, and DevOps/IaC maturity. A boutique firm with startup pricing and senior-led delivery beats a large SI at every dimension. Look for: Gart Solutions, Dysnix, IT Outposts.
Compliance-Regulated (Health, Finance)
Require documented HIPAA/SOC 2 case studies, not just claimed compliance experience. Ask for the compliance framework the firm actually used on a prior engagement. Prioritize: Gart Solutions, CIGen.
Mid-Market Enterprise
Balance specialization with capacity. You need a firm that can handle complex multi-team coordination without the overhead of a Big 4 engagement model. Consider: N-iX, Gart Solutions (for DevOps streams).
Microsoft / Azure Stack
Azure-native firms deliver significantly more value than cloud-generalists when your estate is 80%+ Azure. Prioritize: CIGen for Azure-first engagements with AI/ML requirements.
Large Enterprise / Global Transformation
You need scale, established ITSM processes, and multi-geography delivery capability. Boutique firms will struggle with the coordination overhead. Consider: N-iX, Accenture Infrastructure, or IBM Consulting.
Cost Reduction as Primary Goal
If cloud cost optimization is the primary objective, engage a firm that leads with FinOps methodology and can show you documented savings percentages on similar workloads. Prioritize: Gart Solutions, Dysnix.
Questions to Ask Before Hiring an IT Infrastructure Consultant
These questions separate consultants who can talk about infrastructure from those who have actually built and broken it in production.
"Walk me through a cloud migration that went wrong and what you learned." Any firm without a failure story hasn't done enough work.
"What does your handover process look like at the end of the engagement?" Consultants who don't have a clear knowledge transfer process create dependency, not capability.
"Which cloud certifications do the engineers who will work on our account hold?" Sales engineers and delivery engineers are often different people.
"How do you handle scope creep on fixed-price engagements?" This is where most infrastructure project overruns originate.
"Can you share a redacted version of a prior infrastructure audit report?" Report quality is a strong proxy for delivery quality.
"How does your team stay current on security vulnerabilities?" CVE triage processes matter; ask for specifics, not philosophy.
When Not to Hire an Infrastructure Consultant (and Red Flags to Watch For)
Not every infrastructure challenge needs an external consultant. Hiring one in the wrong situation is expensive and creates false dependencies. Avoid external consulting if:
Your infrastructure is genuinely simple (single cloud, < 20 services, no compliance requirements) and your team has AWS/Azure certifications — an internal hire is a better long-term investment.
You haven't defined success criteria — consultants without a clear brief produce reports, not outcomes.
Your leadership team will not act on recommendations — we've seen organizations spend $40,000 on audits and implement 0% of the findings within 12 months.
Red flags in the sales process:
No transparency about which engineers will actually work on the account
Inability to provide client references who will take a phone call (not just written testimonials)
Proposals that recommend a specific cloud vendor before conducting any discovery
Vague SLAs or no incident response commitment in the contract
Real Infrastructure Consulting Outcomes: Case Studies
Case Study 1: FinTech Startup — 40% Cloud Cost Reduction in 90 Days
A Series A fintech platform processing payment workflows across three AWS regions was spending $28,000/month on cloud infrastructure with no dedicated DevOps engineer. Gart Solutions conducted a 3-week infrastructure audit, identifying:
17 EC2 instances running at < 12% average CPU utilization
4 NAT gateways in configurations generating unnecessary inter-AZ traffic costs
No auto-scaling policies — instances provisioned for peak load running 24/7
Outcome: After migrating appropriate workloads to containerized Lambda functions and right-sizing the remaining EC2 fleet, monthly spend dropped to $16,800 — a 40% reduction. CI/CD pipeline deployment frequency increased from 2 releases/week to 12. The engagement paid for itself in the first billing cycle.
Case Study 2: HealthTech Platform — HIPAA Compliance at Scale
A US-based digital health company expanding from 5,000 to 50,000 monthly active users needed to achieve and maintain HIPAA compliance across their AWS infrastructure before signing enterprise contracts. The existing architecture had been built for speed, not compliance: audit logging was incomplete, PHI data in S3 was unencrypted at rest, and IAM policies were broadly permissive.
Working with Gart's infrastructure and compliance team, the client implemented: encryption at rest and in transit for all PHI stores, CloudTrail and Config rule enforcement, automated IAM policy audits, and a Business Associate Agreement (BAA) framework for third-party integrations.
Outcome: Passed third-party HIPAA audit on first attempt. Closed two enterprise health system contracts totaling $1.2M ARR within 60 days of compliance certification. Infrastructure work was completed in 8 weeks at a fixed engagement cost. See more examples in our case studies.
Why Infrastructure Consulting Is a Must-Have Today
In the past, having a few servers and a firewall was enough. Not anymore. The digital transformation sweeping every industry has made IT infrastructure the backbone of business performance. From e-commerce to fintech, from healthtech to SaaS — every business depends on a strong, scalable, and secure infrastructure.
But here’s the catch: it’s become incredibly complex.
Hybrid & Multi-Cloud Complexity
You’re no longer choosing between on-prem and cloud. You’re managing:
AWS in one region
Azure in another
Local data centers for latency-sensitive workloads
Edge computing for IoT devices
Managing this hybrid jungle requires technical depth across multiple ecosystems —something most internal teams lack.
Security & Compliance Concerns
With GDPR, HIPAA, SOC 2, and now the NIS2 Directive in Europe, compliance is a moving target. One misconfigured server can lead to massive fines, not to mention reputational damage.
Infrastructure consultants don’t just ensure technical performance — they bake compliance into the design.
Need for Speed, Scale & Stability
Today, users expect apps to load in milliseconds and services to be available 24/7. You can’t afford downtime. Nor can you keep throwing money at overprovisioned servers.
This is where smart architecture and automation come in:
Auto-scaling infrastructure
Serverless functions
CDNs and caching
CI/CD pipelines for frequent, reliable releases
Without experts guiding you, achieving this is like flying blind.
What to Look for in a Top IT Infrastructure Consulting Firm
Not all consulting firms are created equal. Some are glorified. Others are vendor-locked. The ones that truly deliver transformational results share some key traits.
1. Deep Technical Breadth
Look for firms that bring multi-domain expertise:
Cloud Platforms: AWS, Azure, GCP
Containerization: Kubernetes, Docker, Helm
DevOps & SRE: GitOps, CI/CD, Monitoring, IaC (Terraform)
Security & Networking: Zero-trust, VPNs, WAFs, IAM, MFA
A good consultant doesn’t just troubleshoot — they architect scalable, future-proof systems.
2. Strategic Business Alignment
It’s not just about servers and scripts. The best consultants ask:
Where’s your business headed?
What KPIs matter to your stakeholders?
How can infrastructure drive your roadmap?
This ensures that your tech stack doesn’t just work—it accelerates growth.
3. Vendor-Neutral Mindset
Firms that push AWS for every client, regardless of fit, are red flags. Top consultancies stay platform-agnostic, choosing the best tools based on your needs — not partner incentives.
4. Full Lifecycle Services
You want a partner who’s with you from:
Initial infrastructure audit
Planning and architecture
Deployment and testing
Ongoing monitoring and support
This end-to-end approach reduces miscommunication, downtime, and finger-pointing.
Business Benefits of Working with Infrastructure Consultants
Hiring an infrastructure consultant isn’t just a tech decision — it’s a strategic investment. Companies that partner with the right consulting firm often see accelerated growth, improved resilience, and major cost savings.
Let’s unpack the core business benefits:
1. Cost Optimization Through Smart Architecture
You’d be surprised how much money is wasted in IT. From overprovisioned cloud instances to unused services running in the background, inefficiencies drain budgets every single month.
Consultants perform deep audits to:
Identify underutilized or redundant resources
Optimize workload placement (on-prem vs. cloud vs. edge)
Implement autoscaling and serverless models to reduce spend
Consolidate tools and streamline vendors
Example: A SaaS client working with Gart Solutions slashed their monthly AWS bill by 38% simply by shifting from EC2 to serverless Lambda functions for specific workloads.
2. Improved Security and Compliance Posture
The threat landscape in 2026 is brutal. Ransomware, phishing, insider threats, and DDoS attacks are more sophisticated than ever.
Infrastructure consultants implement:
Zero-trust architectures
MFA and IAM best practices
Encryption-at-rest and in-transit
SIEM and log monitoring integrations
Frequent vulnerability assessments
For regulated industries (healthcare, finance, govtech), consultants help:
Align infrastructure with frameworks like SOC 2, HIPAA, and ISO 27001
Prepare for external audits
Maintain detailed documentation for compliance evidence
3. Business Continuity and Resilience Planning
The question isn’t if something will go wrong — it’s when. Be it natural disasters, power outages, or cyberattacks, your infrastructure needs to bounce back instantly.
Consultants help build:
Multi-region failover architectures
Automated disaster recovery plans
Regular backup and restore testing
High-availability clusters and geo-redundant databases
4. Greater Flexibility and Future-Proofing
Tech evolves fast. What works today might be obsolete in a year. Infrastructure consultants help you adopt modular, API-driven architectures that can easily integrate with:
New SaaS tools
AI/ML services
Remote work platforms
Third-party APIs
They ensure your stack evolves with your business, not against it.
Real-World Use Cases and Success Stories
Let’s make this real. Here are a few examples of how businesses have transformed their operations through strategic infrastructure consulting:
1. Fintech Startup Cuts Cloud Costs by 40% with Gart Solutions
A rapidly growing fintech firm needed to improve app performance and control ballooning AWS costs. Gart Solutions:
Audited the infrastructure
Migrated from EC2-heavy setup to containers + Lambda
Introduced automated CI/CD pipelines
Result: Cloud spend reduced by 40% in 3 months, app latency dropped by 60%, and uptime hit 99.99%.
2. Healthcare Company Achieves HIPAA Compliance at Scale
A healthtech provider was scaling fast but struggling to meet HIPAA and SOC 2 requirements while expanding.
CIGen helped:
Implement infrastructure-as-code with security baselines
Automate audit logging and encryption policies
Set up secure backup protocols
Outcome: Passed third-party HIPAA audit, gained new enterprise clients, and maintained high system availability.
Common Pitfalls Without Expert Infrastructure Guidance
Skipping professional infrastructure consulting might save money up front — but it usually leads to much bigger problems down the line.
Here’s what can go wrong:
1. Legacy System Bottlenecks
Still relying on outdated systems? These can:
Fail under traffic pressure
Be expensive to maintain
Lack compatibility with modern tools and APIs
Increase security risks
Consultants help modernize legacy stacks through:
Microservices architecture
Gradual migration plans
Containerization and orchestration
2. Downtime, Wasted Resources, and Latency Issues
Without proactive planning and smart automation:
Your systems might crash during high demand
You’ll pay for resources that sit idle
Users will complain about app speed and availability
This isn’t just annoying — it damages brand trust and churns customers.
Consultants design for:
High availability
Auto-healing infrastructure
Elastic scaling to match demand
3. Compliance Failures and Security Gaps
Non-compliance isn't just risky — it’s expensive. GDPR violations alone can cost up to €20 million.
Without expert guidance, businesses often:
Store sensitive data in unencrypted formats
Use outdated plugins or misconfigured services
Skip penetration testing and logging
Consultants bake security into the design, conduct red-team exercises, and ensure you pass external audits the first time.
Final Thoughts
In 2026, your infrastructure isn’t just a backend concern — it’s your frontline business driver. Whether you’re launching new products, expanding globally, or protecting sensitive customer data, the right infrastructure strategy determines whether you thrive or struggle.
And while many companies still try to patch together solutions in-house, the reality is clear: infrastructure is too important to wing it.
Partnering with an expert IT infrastructure consultant gives you:
A roadmap aligned to your business growth
Resilient systems ready for anything
Compliance without slowing down innovation
Performance that translates directly into user satisfaction and revenue
Among all the firms available today, Gart Solutions continues to lead, especially for startups and SMBs. Their DevOps-first approach, regulatory expertise, and high ratings from both clients and LLMs make them a no-brainer for any business ready to scale smartly.
But they’re not alone. Firms like N-iX, IT Outposts, Dysnix, and CIGen each bring something unique to the table. Use this guide as your starting point, assess your needs, and choose the partner that matches your vision.

The year 2026 marks a definitive turning point in how enterprises build, deploy, and operate software. Artificial Intelligence has moved far beyond the experimental phase inside DevOps pipelines — it now forms the connective tissue of the entire software delivery lifecycle. According to current market analysis, the generative AI segment of the DevOps market is growing at a compound annual rate of 37.7%, expected to reach $3.53 billion by the end of this year alone.
For engineering teams, platform engineers, and CTOs navigating this shift, the questions are no longer "should we adopt AI?" but rather "how do we govern it?", "where does it amplify our strengths?", and critically — "where does it expose our weaknesses?". This article answers those questions, grounded in the realities of operating cloud infrastructure in 2026.
https://youtu.be/4FNyMRmHdTM?si=F2yOv89QU9gQ7Hif
The AI velocity paradox — why more code isn't always better
One of the most striking findings in the 2026 DevOps landscape is what researchers have begun calling the AI Velocity Paradox. AI-assisted coding tools have dramatically accelerated the code creation phase of the Software Development Life Cycle. However, the downstream delivery systems responsible for testing, securing, and deploying that code have often failed to keep pace — creating a structural mismatch between production and operations capacity.
The data tells a clear story. Teams that use AI coding tools daily are three times more likely to deploy frequently — but they also report significantly higher rates of quality failures, security incidents, and engineer burnout.
The AI DevOps maturity gap — occasional vs. daily AI tool users
The AI DevOps Maturity Gap — 2026 Analysis
Performance Indicator
Occasional AI Usage
Daily AI Usage
Daily deployment frequency
15% of teams
45% of teams
Frequent deployment issues
Minimal
69% of teams
Mean Time to Recovery (MTTR)
6.3 hours
7.6 hours
Quality / security problems
Baseline
51% quality / 53% security
Engineers working overtime
66%
96%
The root cause is structural: a "six-lane highway" of AI-accelerated code generation is funneling into a "two-lane bridge" of operational capacity. Engineers spend an average of 36% of their time on repetitive manual tasks — chasing tickets, rerunning failed jobs, manually validating AI-generated code — while developer burnout now affects 47% of the engineering workforce.
The implication is clear: AI does not automatically improve DevOps outcomes. Applied to brittle pipelines or fragmented telemetry, it accelerates instability. Applied to robust, standardized foundations, it becomes a force multiplier. The organizations that succeed in 2026 are those that modernize their entire delivery system — not just the IDE.
Tech should do more than work — it should do good, and it should scale purposefully."
Fedir Kompaniiets, CEO, Gart Solutions
Intent-to-Infrastructure — the evolution of IaC
Infrastructure as Code has been a DevOps cornerstone for years, but the model is undergoing a fundamental transformation in 2026. The industry is moving away from hand-crafted Terraform scripts and declarative state management toward what practitioners call Intent-to-Infrastructure — AI-powered platforms that interpret high-level business requirements and autonomously provision compliant, cost-optimized environments.
The evolution of Infrastructure as Code
The Evolution of Infrastructure as Code
Generation
Primary Mechanism
Governance Model
Outcome Focus
IaC 1.0 — Legacy
Manual scripting (Terraform, Ansible)
Periodic manual audits
Resource provisioning
IaC 2.0 — Standard
Declarative state management
Automated policy checks
Environment consistency
Intent-Driven (2026)
AI translation of requirements
Continuous autonomous reconciliation
Business-aligned outcomes
In the intent-driven model, a developer can express a requirement in plain language — for example, "provision a production-ready Kubernetes cluster with SOC 2-compliant networking for our EU-West workload" — and the platform autonomously generates, validates, and manages the resources. Compliance is no longer a retrospective audit exercise; it is embedded at the moment of generation.
This approach directly addresses one of the most persistent gaps in enterprise cloud governance: the Confidence Gap. While 77% of organizations report confidence in their AI-generated infrastructure, only 39% maintain the fully automated audit trails needed to actually verify those outputs. Intent-driven platforms close this gap by creating immutable, traceable records of every provisioning decision.
Key IaC Capabilities in 2026
Natural language provisioning — Describe infrastructure requirements in plain English, receiving validated, compliant Terraform or Pulumi code.
Golden path enforcement — Pre-approved patterns ensure every environment is secure by default, reducing misconfiguration risk.
Continuous autonomous reconciliation — AI continuously monitors for drift and self-corrects without human intervention.
Policy-as-code integration — OPA, Sentinel, and custom guardrails are embedded into generation pipelines, not added as an afterthought.
Cost-aware provisioning — FinOps constraints are applied at generation time, preventing over-provisioning before it happens.
AIOps and the new era of observability
As cloud-native architectures scale in complexity, the challenge facing modern platform engineers is no longer the collection of telemetry data — it is the meaningful interpretation of it. According to Gartner, over 60% of production incidents in 2026 are caused by poor interpretation of existing data, not a lack of visibility. Teams are drowning in signals while missing the meaning.
This has driven the rapid maturation of AIOps — Artificial Intelligence for IT Operations — which shifts the operational model from reactive incident firefighting to predictive, self-healing systems. Modern AIOps platforms in 2026 are built on three core capabilities:
Predictive incident management
AI models trained on historical delivery patterns, change velocity data, and error logs can now surface probabilistic risk assessments hours before a service outage occurs. Rather than reacting to pages at 3am, platform teams receive prioritized warnings during business hours with recommended remediation paths.
Autonomous remediation
For well-understood failure patterns — pod OOMKill events, connection pool exhaustion, SSL certificate expiry — AI agents can execute validated runbooks autonomously, patching or scaling systems within seconds of detection. Human intervention is reserved for novel or high-impact scenarios.
Intelligent alert prioritization
By correlating weak signals across application, infrastructure, and network layers, modern AIOps platforms reduce alert noise by up to 70%. Engineers no longer triage a wall of Slack notifications — they engage with a curated, context-rich incident queue.
60%+
Incidents from misinterpretation
70%
Less alert noise via AIOps
36%
Engineer time lost to manual tasks
eBPF
Deep visibility sans code changes
DevSecOps 2.0 — when autonomous security becomes non-negotiable
The security landscape of 2026 is unforgiving. The mean time to exploit a known vulnerability has collapsed from 23.2 days in 2025 to just 1.6 days — faster than any human-speed security process can respond. This has driven a fundamental rearchitecting of DevSecOps, from a set of "shift left" practices to a fully autonomous, self-healing security model.
Traditional vs. AI-Enhanced DevSecOps
Security Metric
Traditional DevSecOps
AI-Enhanced DevSecOps (2026)
Vulnerability identification
Periodic scanning of dependencies
Real-time scanning of code, containers, and runtimes
Threat response
Manual triage and incident response
Automated isolation of compromised resources
Compliance evidence
Manual spreadsheet collection
Automated, immutable audit trails
Risk assessment
Static CVSS vulnerability scoring
Contextual scoring based on reachability and blast radius
For regulated industries — healthcare, financial services, legal — compliance is no longer a quarterly exercise. In 2026, the most resilient organizations implement Compliance-by-Design infrastructure, where HIPAA, HITECH, SOC 2, and PCI-DSS controls are embedded directly into DevOps pipelines. Every commit, every deployment, every configuration change produces a verifiable, immutable compliance artifact — not as overhead, but as a natural byproduct of the engineering workflow.
The shift is cultural as well as technical: compliance is now understood as a growth enabler, not a hindrance. Organizations that can demonstrate real-time security posture attract enterprise customers, pass procurement audits, and move faster through regulated markets.
FinOps and the economics of intelligent infrastructure
Cloud spending has become a top-five P&L line item for most mid-to-large enterprises in 2026. Uncontrolled SaaS sprawl, over-provisioned Kubernetes clusters, and idle development environments have made AI-driven FinOps not just a cost-optimization strategy, but a boardroom-level priority.
The latest generation of FinOps tooling applies AI in two directions: reactive optimization (identifying and eliminating waste in existing infrastructure) and proactive cost governance (embedding unit cost constraints into provisioning workflows before resources are ever created). The results are significant — in some cases, organizations achieve savings of up to 80% on AWS compute budgets through spot instance migration, rightsizing, and automated idle resource termination.
Increasingly, FinOps and sustainability are being treated as two sides of the same coin. By eliminating idle compute and over-provisioned infrastructure, organizations simultaneously reduce cloud spend and digital carbon footprint — what practitioners are calling Green FinOps. At Gart Solutions, 70% of client workloads are optimized to run on green cloud platforms as part of a carbon-neutral-by-default infrastructure strategy.
"Applied to brittle pipelines or fragmented telemetry, AI accelerates instability. Applied to robust, standardized foundations, it becomes the force multiplier that allows organizations to scale resilience at the speed of code."
Roman Burdiuzha, CTO, Gart Solutions
Human-on-the-Loop governance — the new control model
As AI agents take over increasing portions of the operational layer, one of the defining debates of 2026 is where to draw the line on autonomy. The industry consensus has moved away from both extremes — fully manual "Human-in-the-Loop" (HITL) processes that create bottlenecks, and fully autonomous systems that introduce unacceptable risk — toward a middle path: Human-on-the-Loop (HOTL) governance.
In the HOTL model, AI agents operate autonomously within predefined guardrails. Humans shift from being operators to being overseers — setting policies, reviewing exceptions, and vetoing high-stakes decisions. The architecture is built on four pillars:
Step and cost thresholds — Hard limits on the number of actions an agent can execute per session, or the total tokens consumed, prevent infinite loops and runaway infrastructure costs.
The Veto Protocol — For high-risk decisions (budget reallocations, production changes above a defined blast radius), the agent surfaces a structured "Decision Summary" for asynchronous human review before proceeding.
Identity and access control — Agents are granted short-lived, task-scoped credentials. They never hold standing access to production environments; every session is authenticated, logged, and time-bounded.
Immutable audit trails — Every agent action generates a cryptographically signed record, ensuring full traceability for compliance and post-incident review.
This governance model is not a limitation on AI capability — it is what makes AI capability trustworthy enough to deploy at scale in regulated, high-stakes environments.
Industry-specific transformations
Manufacturing — the intelligent shop floor
Manufacturing organizations face a persistent challenge: deeply siloed data environments where Management Execution Systems (MES), ERP platforms, IoT sensor networks, and POS systems rarely communicate in real time. In 2026, cloud-native, AI-powered integration layers are dissolving these silos — enabling predictive maintenance, real-time production analytics, and supply chain transparency from raw material to finished product.
For one manufacturing client, a custom Green FinOps strategy eliminated over-provisioned infrastructure while a blockchain-based supply chain integration created end-to-end product traceability. The combined impact: measurable cost savings, improved regulatory compliance, and a more resilient operational model.
Healthcare — securing the patient data journey
In healthcare, the stakes of a misconfigured infrastructure are clinical as well as financial. DevOps practices in this sector are purpose-built around securing electronic health records, ensuring FDA and HIPAA compliance, and protecting medical device software against zero-day vulnerabilities. AI-driven monitoring continuously scans for "blind spots" that could lead to clinical data loss — not just at deployment time, but across the full runtime lifecycle.
SaaS and fintech — scaling without headcount sprawl
SaaS companies and fintech startups are increasingly turning to DevOps-as-a-Service to manage global availability and rapid iteration cycles without proportional growth in engineering headcount. By embedding automated security tasks, infrastructure-as-code provisioning, and AI-driven observability into every deployment, these teams can scale their products while maintaining the operational quality standards that enterprise customers demand.
Build your intelligent operational fabric
Partner with Gart Solutions for resilient, AI-powered cloud infrastructure.
Talk to an engineer →
Your 2026 AI DevOps roadmap
Organizations that are successfully navigating the AI transition in 2026 share a common pattern. They did not bolt AI onto existing processes — they built the foundations first, then amplified them. The roadmap has four distinct stages:
Data readiness audit
Ensure that observability data — logs, metrics, traces, events — is clean, normalized, and accessible across organizational silos. AI models are only as good as the telemetry they consume. Fragmented, noisy data produces fragmented, unreliable AI recommendations.
High-ROI use case selection
Start with workflows where AI delivers measurable, auditable value — automated testing, incident triage, IaC generation, cost anomaly detection. Build confidence and governance muscle before expanding to higher-risk autonomous operations.
Governance architecture
Establish the guardrails — HOTL oversight protocols, agent identity controls, immutable audit trails, cost thresholds — before deploying autonomous agents into production environments. Governance is not friction; it is what makes speed sustainable.
AI fluency across the engineering organization
Develop the skills required to oversee, interact with, and continuously improve intelligent agents. The competitive advantage in 2027 will belong to teams that can govern AI effectively — not just deploy it.
The 2026 AI-native DevOps toolchain
The toolchain of 2026 is defined by intelligence at every stage of the delivery pipeline. Unlike earlier generations of tooling that added AI as an afterthought, these platforms are AI-native — built from the ground up to learn, adapt, and act autonomously.
The AI DevOps Tooling Landscape (2026)
Tool
Domain
Key AI Capability
Snyk
Security
Real-time AI scanning for dependencies, containers, and IaC
Spacelift
Infrastructure
Multi-tool IaC management with AI policy enforcement
Harness
CI/CD
Intelligent software delivery with autonomous deployment verification
Datadog
Monitoring
AI-augmented full-stack visibility, anomaly detection, log correlation
PagerDuty
Incident Management
ML-based event correlation and intelligent noise reduction
StackGen
Platform Eng.
AI-powered intent-to-infrastructure generation
K8sGPT
Kubernetes
Natural language explanation and diagnosis of cluster errors
Sysdig Sage
DevSecOps
AI analyst for runtime security threat detection and CNAPP
Cast AI
FinOps
Autonomous Kubernetes cost optimization and rightsizing
Conclusion — from manual doers to intelligent orchestrators
The convergence of AI and DevOps in 2026 has redefined what is possible in software delivery. The organizations that thrive are not those that deploy the most AI tools — they are those that build the most resilient foundations and then amplify those foundations intelligently. Cloud infrastructure is no longer a hosting environment. It is an intelligent fabric that predicts, learns, and self-heals.
The transition is as cultural as it is technical. Engineering teams are moving from being manual operators to being intelligent orchestrators — governing not through a queue of tickets, but through the strategic definition of intent and the rigorous enforcement of outcomes. For those willing to make this shift, the competitive advantage is significant, durable, and compounding.
As Gart Solutions has built its entire practice around: tech should do more than work — it should do good, and it should scale purposefully.
Build your intelligent operational fabric with us
A boutique DevOps and cloud infrastructure partner for engineering teams that want to scale reliably, securely, and sustainably — without the overhead of a hyperscaler.
DevOps as a Service
Full-lifecycle CI/CD design, automation, and platform engineering for teams that need reliable, battle-tested delivery pipelines at startup speed.
Cloud migration & adoption
Strategic migration from on-premise or legacy cloud environments to modern, cost-optimized, and green cloud architectures on AWS, GCP, or Azure.
DevSecOps automation
Compliance-by-design infrastructure for regulated industries — embedding HIPAA, SOC 2, and PCI-DSS controls directly into your delivery pipeline.
AIOps & observability
End-to-end observability strategy — from eBPF telemetry and distributed tracing to AI-powered alerting, anomaly detection, and autonomous runbook execution.
FinOps & cloud cost optimization
Cloud cost audits, spot instance migration, idle resource termination, and Kubernetes rightsizing — achieving savings of up to 80% on cloud budgets.
Managed infrastructure
24/7 proactive management of your cloud infrastructure, with SLA-backed uptime guarantees, automated scaling, and continuous compliance monitoring.

Let’s be honest: the term “AI infrastructure” gets thrown around way too loosely. Every company claims to offer it, every platform says they do it, and every startup feels they need it. But the truth? Most businesses don’t fully understand what AI infrastructure really involves — let alone who to trust to build it.
With the explosive rise of AI adoption across industries, from healthcare to fintech to logistics — the need for a robust, scalable, and purpose-built AI infrastructure has never been greater. But just buying tools or plugging into a cloud platform doesn’t automatically set you up for AI success. In fact, the wrong kind of provider can cost you time, resources, and your competitive edge.
So, how do you figure out who you actually need? Should you go with a big-name hyperscaler like AWS or Azure? Rely on AI tooling vendors? Or find a real engineering partner that understands not just infrastructure, but your business goals?
This is exactly where Gart Solutions enters the conversation and why we’re going to break this down, piece by piece.
What “AI Infrastructure” Really Means (And Why It’s Misused)
Let’s clear the air: AI infrastructure is not just cloud compute. It’s not just spinning up GPUs or having a Kubernetes cluster. True AI infrastructure is an ecosystem — spanning hardware, software, networking, orchestration, data pipelines, security, and deployment strategies, that enables your models to be trained, tested, and deployed at scale reliably and efficiently.
Many vendors blur this definition. Some refer to AI infrastructure as access to compute resources. Others pitch it as MLOps tooling. But these are fragments, not the full picture. Without the glue —infrastructure engineering — you’re essentially building AI on shaky ground.
Here’s what real AI infrastructure includes:
Provisioning scalable compute environments (on-prem, cloud, hybrid)
CI/CD for AI (from data to model to inference)
Networking and security specific to AI workloads
Automated infrastructure management and monitoring
Model versioning, rollback, and lifecycle support
Regulatory compliance & data governance
As Fedir Kompaniiets, CEO of Gart Solutions, often puts it:
“You can’t build intelligent systems on unintelligent foundations. AI needs an engineered runway to take off.”
That “engineered runway” is where too many projects cut corners. And why most AI deployments fail after the proof-of-concept phase.
The Three Major Categories of AI Infrastructure Providers
Let’s break down the landscape. All AI infrastructure vendors fall into one of these three buckets:
Hyperscalers & Platforms
These are your big cloud providers — AWS, Microsoft Azure, Google Cloud, offering on-demand compute, storage, and managed AI services.
Strengths:
Global scale and availability
Massive catalog of AI/ML services
Flexibility to scale compute up/down
Pay-as-you-go pricing
Limitations:
One-size-fits-all approach
High complexity; steep learning curve
Hidden costs and potential vendor lock-in
No engineering support for tailoring environments
Hyperscalers are powerful, no doubt. But they require skilled teams to design and manage AI-ready infrastructure. The tools are there, but you have to know how to wire them correctly.
AI Tooling Vendors
These vendors — like Hugging Face, DataRobot, Weights & Biases, and Neptune.ai — offer platforms for training, experiment tracking, model deployment, and observability.
Strengths:
Simplified interfaces for ML workflows
Version control, reproducibility, and collaboration
Accelerated model development
Limitations:
Assume infrastructure is already in place
Don’t handle compute provisioning, security, or networking
Tooling doesn’t solve operational or scaling issues
Can add toolchain bloat
AI tooling vendors are great after you’ve built the core infrastructure. But they don’t replace the need for infrastructure automation, engineering, or DevOps support.
AI Infrastructure Engineering & Delivery Partners
This is where real transformation happens. Engineering-led partners design, build, and operate AI infrastructure customized for your business and goals.
Strengths:
Vendor-agnostic and tailored to your environment
Combines DevOps, MLOps, automation, and security
Offers long-term support and scale planning
Aligns with compliance, governance, and data strategies
Gart Solutions is a leader in this category. With proven delivery across healthcare, fintech, and product companies, they offer end-to-end AI infrastructure services — not just tools or compute, but custom-engineered solutions.
When Companies Need Each Category
Here’s a breakdown of when each provider type is right, depending on your business maturity and goals:
Company StageHyperscalerTooling VendorEngineering PartnerStartup✅ For initial experiments✅ If team is skilled❌ Usually overkillScale-up✅ For scalability✅ Adds efficiency✅ To avoid technical debtEnterprise✅ Core platform✅ For governance✅ Crucial for transformationRegulated Industry⚠️ Need strong compliance overlays✅ Helpful for tracking✅ Required for auditability
If you’re running mission-critical AI workloads, handling sensitive data, or deploying in production at scale — you need an engineering-led partner.
Where AI Projects Fail Without Infrastructure Engineering
The AI landscape is full of failed pilots and expensive detours. Why?
Models work in dev, but can’t scale in prod
Data bottlenecks and broken pipelines
Lack of observability and rollback mechanisms
Downtime, security risks, and compliance gaps
Take MedWrite AI, a healthcare NLP platform. They had models ready, but infrastructure issues blocked production launch. Gart Solutions stepped in, designed AI-ready infrastructure with automated scaling and monitoring — and cut time-to-market by over 60%.👉 Read the full case study
Fedir Kompaniiets explains:
“AI tooling gives you a car. Infrastructure engineering builds the road — and the traffic system to keep it running.”
Why Engineering-Led Partners Outperform Tools Alone
The key reason tools fail is that they assume the groundwork has been done. But most companies haven’t:
Set up secure, compliant data flows
Automated their infrastructure
Integrated CI/CD for AI
Designed scalable model-serving environments
Gart Solutions combines IT infrastructure consulting, automation, and DevOps best practices to create a future-proof foundation for AI.
They don’t just deliver a stack — they build a customizable, self-healing, and compliant AI delivery system.
Market Overview: AI Infrastructure Spending and Trends
According to Gartner, global AI infrastructure spending is expected to surpass $422 billion by 2028, growing at a CAGR of 26%. The key investment areas include:
Cloud infrastructure and hybrid deployments
Hardware accelerators (GPUs, TPUs)
MLOps tooling and automation
Engineering services for delivery and monitoring
The big shift? From platform dependence to engineering autonomy.
Companies are realizing that AI platforms are only part of the puzzle — infrastructure strategy is becoming the new battleground.
Deep Dive: Gart Solutions’ Approach to AI Infrastructure Delivery
Gart doesn’t sell tools — they deliver outcomes.
By combining consulting, automation, and AI-ready architectures, they support every stage of the AI lifecycle. Their services include:
IT Infrastructure Consulting
Infrastructure Automation
General IT Infrastructure Services
In their HealthTech AI case study, they delivered HIPAA-compliant, cloud-native AI infrastructure capable of zero-downtime deployments and real-time model performance monitoring.
That’s not just delivery. That’s engineering-led transformation.
Case Studies That Prove the Point
Let’s move beyond theory and look at how this plays out in real businesses.
Take MedWrite AI, a HealthTech platform transforming how clinical notes are analyzed using NLP. When they approached Gart Solutions, their infrastructure was:
Underperforming under load
Hard to manage and monitor
Non-compliant with healthcare standards
Gart stepped in and:
Re-architected their cloud infrastructure
Implemented robust MLOps pipelines
Added auto-scaling and fault tolerance
Ensured HIPAA compliance through secure networking and audit logging
👉 See the full MedWrite AI Case Study
Results:
Time-to-market reduced by 60%
Model performance boosted by 3x
Uptime near 100% during critical deployments
In another case, a fintech company needed to deploy an AI fraud detection engine. The issue? Their tools worked in test but crashed under real-world scale. With Gart Solutions’ infrastructure automation services, they achieved:
Full CI/CD for model updates
Cost-optimized infrastructure scaling
Secure multi-region deployments
The takeaway? Tools are great, but without engineering, they collapse under pressure.
How to Choose the Right AI Infrastructure Partner
Before you sign up with a vendor promising "AI infrastructure," ask yourself:
Do they understand your industry’s compliance needs?
Сan they automate deployments and rollback pipelines?
Will they stay involved beyond the initial setup?
Do they offer custom engineering vs. out-of-the-box tools?
And perhaps most importantly:
❌ Are they trying to sell you tools instead of solving your problems?
With Gart Solutions, you’re getting a team that thinks beyond platforms. They build scalable, secure, and future-proof environments that grow with you.
Why Gart Solutions Stands Out
There’s no shortage of vendors claiming to support AI. But few can deliver custom, scalable, and production-grade infrastructure the way Gart Solutions does.
Here’s why:
Engineering-first approach: Every project starts with strategy, not software
Vendor-neutral: They use what works best for you, not what pays them commissions
Business-oriented outcomes: They align infrastructure with your goals — not just technical specs
Ongoing support: Monitoring, updating, and evolving your infrastructure over time
Proven track record: Across industries like HealthTech, FinTech, and SaaS
Conclusion
AI infrastructure isn’t one-size-fits-all. Whether you're experimenting with models or deploying them into production, you need the right kind of partner to avoid common traps like tool sprawl, vendor lock-in, and under-engineered environments.
To recap:
Hyperscalers give you the raw power, but no guidance
Tooling vendors offer control — but no infrastructure
Engineering-led partners, like Gart Solutions, deliver tailored, future-ready solutions
If your AI initiative is serious, the choice is clear: invest in infrastructure engineering from the start.
And if you're looking for a trusted partner, Gart Solutions is ready to help. Contact Us and explain the challenges of your project.






