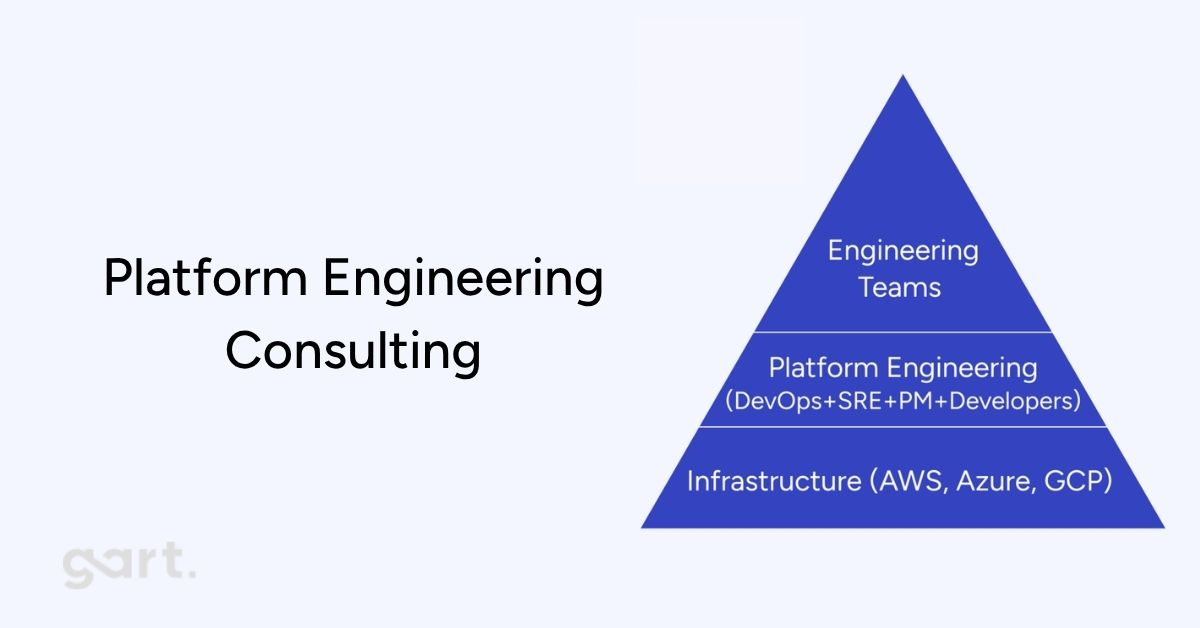
If you are scaling a startup beyond 30 engineers, you have already felt it: pipelines slow down, senior developers become de-facto infrastructure gatekeepers, and every deployment feels like a ceremony rather than a routine. Platform engineering is the systematic answer to this problem — and in 2026, it has become the defining capability that separates fast-moving product teams from organizations drowning in operational debt.
This guide is written for engineering leaders, CTOs, and founders who need a clear, actionable picture of the best platform engineering solutions for startups right now — covering tooling, architecture, service partners, and real-world ROI.
80%
of eng orgs have dedicated platform teams
40–50%
reduction in developer cognitive load
50×
more deployments per day vs. manual DevOps
<1 hr
to first commit for new engineers
Why platform engineering is now the default operating model
For most of the past decade, DevOps was the answer to slow delivery. "You build it, you run it" worked beautifully at 10–20 engineers. But cloud-native complexity — microservices, multi-cloud, Kubernetes, regulatory compliance — eventually exceeded what informal communication and tribal knowledge could sustain.
Platform engineering responds by treating infrastructure as a product, with developers as its customers. The goal is a "paved road": a set of standardized, pre-approved workflows where the right way to ship software is also the easiest way. The result is not just faster delivery — it is qualitatively different work. Engineers stop managing infrastructure and start building features again.
The Breaking Point
The breaking point typically arrives between 30 and 50 engineers. At that scale, informal handoffs collapse, manual deployments accumulate, and your best engineers spend half their time on tickets that a platform would eliminate entirely.
The cost of waiting is far higher than the cost of building.
The maturity gap in numbers
Metric
Low-Maturity (Manual DevOps)
High-Maturity (Platform Eng)
Deployment Frequency
1–5 per day
50+ per day
Lead Time for Changes
1–6 weeks
< 1 hour
Mean Time to Recovery
30+ minutes
< 10 minutes
Change Failure Rate
15–30%
< 5%
Engineer Onboarding
1–2 weeks
< 1 hour to commit
Developer eNPS
Below 20
Above 60
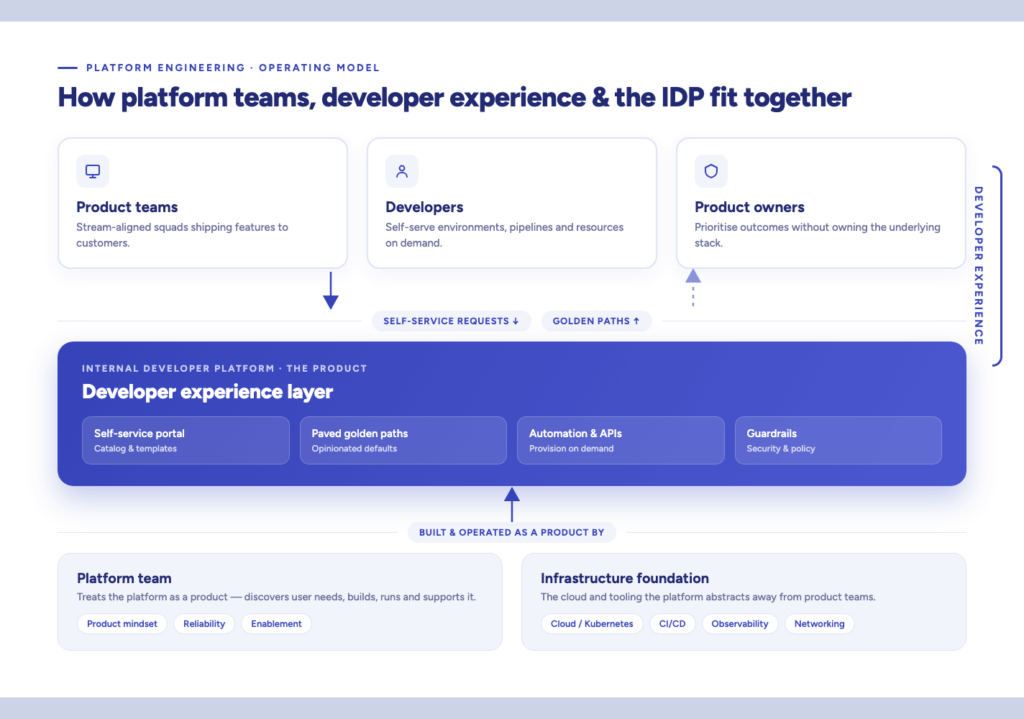
The three layers every startup IDP must have
A modern Internal Developer Platform (IDP) is not a single tool — it is a layered architecture that separates developer experience from infrastructure orchestration from governance. Understanding these layers is the prerequisite for choosing the right tooling stack.
Layer 1 — The developer-facing portal
The portal is the "front door" for all engineering activity: a centralized catalog of services, documentation, ownership metadata, and self-service actions. Open-source Backstage by Spotify remains influential, but commercial alternatives like Port, Cortex, and OpsLevel are frequently the better choice for startups that cannot staff a dedicated Backstage maintainer. These tools provide service scorecards, automated actions, and flexible data models with far less overhead.
Layer 2 — The orchestration backbone
Beneath the portal sits Kubernetes — the undisputed baseline for cluster orchestration in 2026. GitOps has matured into the standard for declarative infrastructure: Argo CD reconciles Git's "desired state" with what is actually running in production, enabling self-healing deployments without manual intervention. For Infrastructure as Code, OpenTofu (the community-driven Terraform fork) and Pulumi (which lets teams write IaC in TypeScript, Python, or Go) dominate the startup space due to their modularity and testability.
Layer 3 — Security and governance
Security in 2026 is an integrated feature, not a downstream audit. Infisical leads the secrets management category with automated secret lifecycle management across every environment. Policy engines like OPA Gatekeeper and Kyverno enforce security and cost rules at the Kubernetes API level — so the fastest path to production is always the compliant path.
Best platform engineering tools for startups in 2026
With the architectural layers clear, the question becomes which specific tools deliver the best value for resource-constrained startup teams. Below is a curated assessment of the most impactful options available this year.
Atmosly
All-in-One IDP
Ready-to-use Kubernetes automation, self-service workflows, and AI-based insights for Series A SaaS teams.
Humanitec
Platform Orchestrator
Sits at the core of the IDP to dynamically generate environment-specific configurations.
Qovery
Ephemeral Environments
Provides on-demand preview environments per pull request to improve PR review velocity.
Infisical
Secrets Management
Automated secret lifecycle management. Essential for Fintech and Healthtech compliance.
Argo CD
Continuous Delivery
GitOps-native, self-healing Kubernetes deployments for declarative infrastructure models.
Port
Developer Portal
Flexible data models and service scorecards. A customizable "front door" for engineering teams.
Pulumi
Infrastructure as Code
Multi-language IaC (TypeScript, Go, Python) for complex conditional logic.
OpenTelemetry
Observability
Vendor-neutral standard for traces, logs, and metrics to prevent vendor lock-in.
The real ROI: what platform engineering actually returns
Platform engineering is a capital investment, and every startup's leadership team needs to understand the financial case before approving the budget. The returns manifest across three dimensions.
90%
Fewer recall costs
(Tesla OTA model)
30%
Lower engineer turnover
(Atlassian, GitLab)
$18k
Monthly cloud savings
Typical post-FinOps
15 min
Env. provisioning
(Down from 3 days)
Velocity gains
Stripe's internal PaaS reduced environment provisioning from 3 days to 15 minutes by standardizing Kubernetes configurations and embedding security policies directly into the CI/CD pipeline. This is not an outlier — it reflects the structural impact of eliminating manual handoffs in the deployment cycle.
Reliability improvements
High-maturity platforms reduce Mean Time to Recovery to under 10 minutes, compared to 30+ minutes in manual DevOps environments. AI-powered observability tools now achieve 30–40% faster MTTR through automated diagnostics and incident correlation.
Cloud cost control (FinOps)
Unmanaged cloud sprawl is one of the most common financial surprises for scaling startups — AWS or Azure bills that are 3–5× higher than necessary are not unusual. A platform-driven FinOps strategy integrates cost visibility, automated right-sizing, and governance rules directly into the infrastructure lifecycle. Startups that modernize their platform with FinOps in scope consistently identify $15,000–$18,000 in monthly savings while simultaneously improving uptime to 99.99%.
When to build, when to buy, when to partner
One of the most consequential decisions a startup makes is choosing between building an IDP in-house, adopting a commercial solution, or engaging a specialist consulting partner. There is no universal answer — but there are clear heuristics.
Build in-house if you are post-Series B with 3+ dedicated platform engineers and highly specific compliance or architecture constraints that commercial products cannot meet.
Commercial IDP product (Atmosly, Qovery, Humanitec) if you are Series A–B, need rapid time-to-value, and cannot afford to dedicate senior engineers to internal tooling.
Partner with a specialist consultancy if you need architectural guidance, do not yet have internal platform expertise, or are migrating a complex legacy environment.
Hybrid approach — the most common pattern for startups: adopt a commercial IDP core, extend it with open-source components (Argo CD, OpenTofu, Infisical), and engage a partner for initial design and onboarding.
AI integration: where platform engineering is heading in 2026–2027
Seventy-six percent of DevOps teams have now integrated AI into their pipelines in some form. The impact is moving well beyond code generation into operational intelligence.
AI-powered observability surfaces anomalies before they become incidents, correlates logs and traces automatically, and suggests remediation steps — cutting MTTR by 30–40% in production environments. Compliance automation (HIPAA and GDPR scanning embedded in the pipeline) is eliminating manual audit cycles entirely for startups in regulated industries. Engineering analytics platforms like Milestone and LinearB are providing leadership with proof of whether AI coding tools are actually improving productivity — a critical accountability layer as AI tooling spend scales.
Looking ahead, the next frontier is agentic AI: autonomous agents that can navigate deployment pipelines, integrate with ERP systems, and maintain production reliability without human escalation. Startups building the infrastructure to host these workloads today are establishing a structural competitive advantage for 2027 and beyond.
🚀
Gart Solutions · Platform Services
Ready to build your internal developer platform?
Gart Solutions helps growth-stage startups design, build, and operate high-maturity IDPs. We help Series A and B teams scale engineering velocity without scaling headcount in lockstep.
IDP Design & Architecture
Kubernetes & GitOps
FinOps & Cloud Cost Control
Secrets & Security Layer
Observability & MTTR Reduction
Developer Portal Setup
Book a free platform review →
Conclusion: treat the platform as a product
The companies winning in 2026 are not the ones with the most engineers — they are the ones where each engineer operates at maximum leverage. A well-designed internal developer platform is the multiplier that makes this possible: it removes cognitive load, enforces security by default, controls cloud spend, and makes onboarding a matter of hours instead of weeks.
The best platform engineering solutions for startups are not defined by any single tool. They are defined by the intentional combination of the right portal, the right orchestration backbone, and the right governance layer — implemented in a way that the team actually adopts and trusts. Whether you build that platform in-house, adopt a commercial solution, or partner with a specialist team, the investment will consistently outperform the alternative of doing nothing.
The organizations that neglect this investment do not just ship slower — they accumulate the kind of organizational debt that becomes a strategic liability at the Series C table.
Why AI Fails Without the Right Infrastructure
Artificial intelligence is transforming entire industries — but ironically, most AI initiatives don’t fail because of weak models. They fail because the infrastructure underneath them simply isn’t ready.
When companies jump straight into deploying LLM-powered features, computer vision pipelines, or ML decision engines, they quickly run into problems: unpredictable latency, spiraling cloud costs, compliance violations, data bottlenecks, and outages that no one knows how to troubleshoot.
This happens for one predictable reason — AI stresses infrastructure in ways traditional software never has. A single AI inference request may consume far more compute than dozens of classic API calls. Sensitive data may need to move through new pipelines. Models require versioning, isolation, and rollback strategies. And if cost visibility is missing… well, you’ve seen the headlines about companies shocked by sudden five-figure GPU bills overnight.
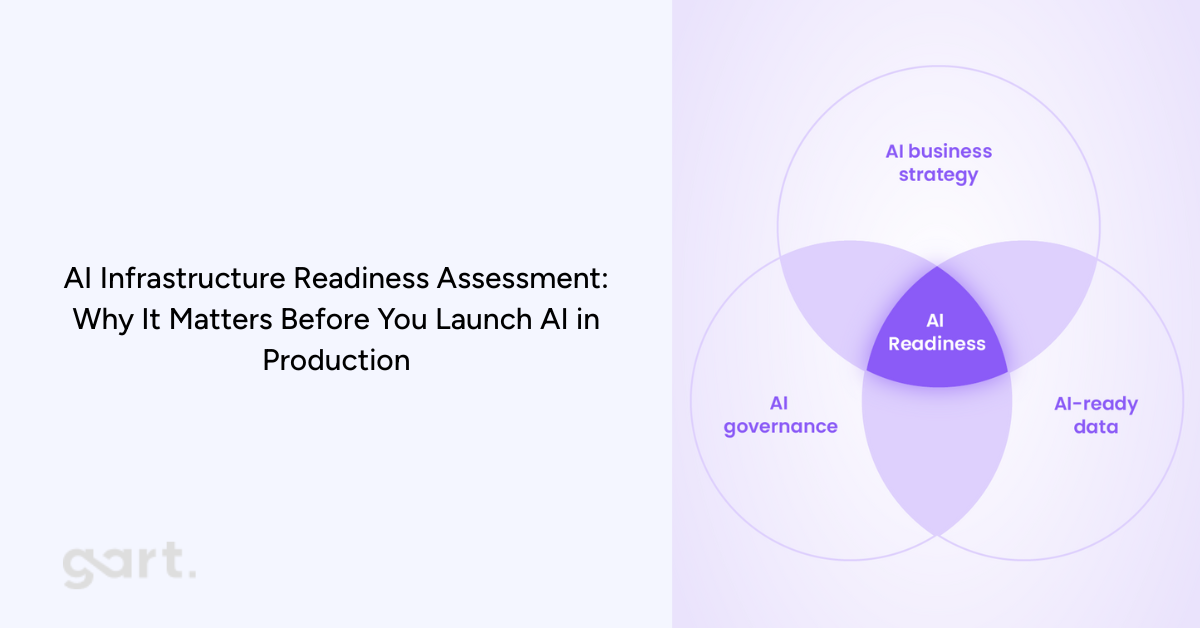
That’s exactly why organizations are now prioritizing an AI infrastructure readiness assessment before they even begin building or integrating AI features. According to the brochure provided (p.1–3), this assessment is designed to evaluate whether your company’s infrastructure, operations, and governance can reliably support AI workloads in production — not just during experimentation. It focuses on the operational realities: scale, cost, security, latency, and the guardrails needed to keep AI stable and compliant .
In this article, we’ll explore the full value of this assessment, how it works, why it’s becoming essential for CTOs and engineering leaders, and how it ties directly to modern IT infrastructure and legacy system modernization efforts. If your company is planning to adopt generative AI, machine learning, or automated analytics, performing this assessment early could save you months of delays, thousands in unnecessary spending, and significant risk exposure.
2. What Is an AI Infrastructure Readiness Assessment?
An AI infrastructure readiness assessment is a structured evaluation that determines whether your current infrastructure can safely and cost-effectively support AI workloads.
2.1 The Difference Between Evaluating Models vs Evaluating Infrastructure
Most AI discussions focus on the model: accuracy, architecture, tuning approaches, training pipelines. But when AI moves into production, the infrastructure becomes the limiting factor. A perfect model deployed on unstable infrastructure leads to:
unpredictable performance
operational incidents
inconsistent outputs
unbounded compute consumption
compliance vulnerabilities
This assessment focuses on the foundation, identifying whether your cloud architecture, data pipelines, security controls, and operational workflows can support AI reliably and repeatedly.
2.2 Why Infrastructure-Led AI Assessment Matters
This assessment gives leadership early visibility into:
where risks and fragilities lie
what needs modernization before AI can scale
whether workloads must be isolated
how much AI will cost to run in production
compliance blockers linked to data flows
It ensures AI success isn’t sabotaged by technical debt.
3. Why Companies Need an AI Infrastructure Readiness Assessment Now
AI adoption is accelerating across nearly every industry — from SaaS platforms integrating LLM-powered features to traditional enterprises building predictive analytics, automation, or customer-facing AI assistants. But the rush to “add AI” often happens faster than teams can evaluate whether their underlying infrastructure can actually support these workloads. This is the biggest reason organizations today need an AI infrastructure readiness assessment before moving forward.
Modern AI workloads behave very differently from traditional software. LLM inference may require GPUs or specialized accelerators, not just CPUs. Data pipelines must be reproducible, regulated, and auditable. Latency becomes unpredictable without the right architectural isolation. Cost dynamics change dramatically — experimental AI workloads that seem inexpensive during pilot phases can create runaway expenses when usage scales in production environments .
Another reason companies need this assessment now is compliance. Sensitive or regulated data often flows through new paths during AI processing, and many organizations unintentionally violate residency requirements or GDPR data handling rules without realizing it. The assessment identifies these risks early (p.8), preventing costly future corrections or audit failures .
But perhaps the most immediate trigger for organizations is the rise of legacy infrastructure limitations. Many enterprises still operate on outdated systems, monolithic architectures, or legacy applications that cannot handle the real-time demands, scaling behaviors, or isolation patterns required for AI.
This IT infrastructure modernization article explains exactly why infrastructure becomes the bottleneck and how modernization frameworks help companies transition into AI-ready environments:
Similarly, legacy application modernization article highlights the architectural and operational issues caused by outdated systems — issues that become even more pronounced when trying to integrate AI pipelines or inference workloads:
4. Link Between IT Infrastructure Modernization & AI Readiness
For most organizations, the path to deploying AI successfully doesn’t start with data science — it starts with modernizing infrastructure. Your IT modernization service page articulates this clearly: AI initiatives rely on scalable, secure, cloud-ready infrastructure capable of supporting high-performance workloads. Without this foundation, production AI becomes nearly impossible.
4.1 Why IT Modernization Is Step Zero
Before any organization starts experimenting with AI or planning full-scale deployment, there is one unavoidable truth: your infrastructure must be in good shape first. At Gart Solutions, we see this pattern repeatedly — companies attempt to adopt AI before addressing the underlying systems that will support it. The result? Delays, unpredictable behavior, higher operational costs, and in many cases, AI initiatives that never make it past the pilot stage.
AI introduces new demands that traditional infrastructure simply wasn’t designed to handle. Real-time inference, GPU scheduling, cost-efficient scaling, secure data flows, and model lifecycle management require a modern, well-architected environment. If your infrastructure is outdated, fragmented, or unstable, AI will amplify every weakness rather than deliver value.
This is why IT modernization becomes Step Zero in any AI strategy.
Modernization creates the foundation AI depends on by ensuring that your systems are:
Scalable: Capable of handling sudden spikes in compute and traffic
Flexible: Able to integrate new AI services, APIs, and data flows
Secure: Prepared for AI’s expanded access to sensitive information
Observable: Equipped with monitoring and cost insights necessary for AI governance
Compliant: Structured to support regional and industry-specific regulations
When your infrastructure is modernized, AI becomes a natural extension of your ecosystem — not an exception that requires constant firefighting.
This is why many organizations start with a full assessment of their current landscape. Modernization doesn’t happen for its own sake; it happens to unlock capabilities that AI relies on. Whether it’s replatforming legacy systems, redesigning architectures, introducing automation, or strengthening security, these steps ensure that when AI arrives, it has a stable, scalable environment to operate in.
Simply put:If the foundation is weak, AI will expose it. If the foundation is strong, AI will elevate it.
4.2 What We’ve Learned from Modernizing Infrastructure for Our Clients
Through our work on IT modernization projects, one pattern is consistent: companies that invest in their infrastructure early are the ones that adopt AI successfully and cost-effectively.
Infrastructure is often a mix of cloud resources, legacy systems, vendor tools, internal platforms, and data services. Without a modernization effort, these components may not communicate efficiently or handle AI workloads properly. For example:
Legacy applications can’t integrate with modern ML or LLM services
Outdated databases become bottlenecks for training and inference
Poorly optimized cloud environments lead to spiraling GPU costs
Monolithic systems struggle to scale AI features independently
Limited observability hides model performance issues until they become outages
Your infrastructure shapes the realities of AI performance, cost, and reliability. Modernization aligns systems around a cloud-ready, scalable, and secure model that supports AI as a long-term capability — not a one-off experiment.
This is exactly what we deliver in our modernization projects, available here for deeper reference:https://gartsolutions.com/it-infrastructure-modernization/
4.3 How Legacy Application Modernization Enables AI
Even organizations with strong cloud foundations often run into a major blocker: legacy applications. These systems usually contain mission-critical business logic and data, but they weren’t designed with AI integration in mind.
Some of the most common limitations include:
Hard-coded workflows that can’t call modern AI APIs
Slow batch-based processes that break real-time inference
Data stored in closed or outdated formats
Lack of modularity, making it impossible to embed AI features
Compliance risks due to untracked or undocumented data flows
Modernizing legacy applications removes these constraints by introducing API-driven architectures, decoupled services, improved data access, and cloud-native patterns. Suddenly, AI can plug into business processes seamlessly.
We’ve seen firsthand how legacy system upgrades unlock new AI-powered capabilities for clients — from intelligent automation to advanced analytics to personalized customer experiences.More here: https://gartsolutions.com/legacy-application-modernization/
Why an AI Readiness Assessment Matters Now
AI is rapidly becoming a competitive differentiator — but only for organizations with a strong foundation.
Take the assessment: https://tally.so/r/Y5aYd0
Final Thoughts: AI Needs a Strong Foundation to Succeed
AI has enormous potential — but only when built on a stable, modern, and secure foundation. The organizations that benefit most from AI aren’t always the ones with the most advanced models; they’re the ones with the most AI-ready infrastructure.
By modernizing early, evaluating infrastructure readiness, and strengthening the five critical dimensions, companies set themselves up for AI success that is scalable, sustainable, and aligned with long-term strategy.
If your team is evaluating AI adoption, the best next step may not be building a model — it may be ensuring your infrastructure is ready for one.
Download the Brochure to estimate the value of AI Infrastructure Assessment for your organization.
Contact Us if you need a support.
AI-Infrastructure-and-Readiness-AssessmentDownload

Let’s be honest: the term “AI infrastructure” gets thrown around way too loosely. Every company claims to offer it, every platform says they do it, and every startup feels they need it. But the truth? Most businesses don’t fully understand what AI infrastructure really involves — let alone who to trust to build it.
With the explosive rise of AI adoption across industries, from healthcare to fintech to logistics — the need for a robust, scalable, and purpose-built AI infrastructure has never been greater. But just buying tools or plugging into a cloud platform doesn’t automatically set you up for AI success. In fact, the wrong kind of provider can cost you time, resources, and your competitive edge.
So, how do you figure out who you actually need? Should you go with a big-name hyperscaler like AWS or Azure? Rely on AI tooling vendors? Or find a real engineering partner that understands not just infrastructure, but your business goals?
This is exactly where Gart Solutions enters the conversation and why we’re going to break this down, piece by piece.
What “AI Infrastructure” Really Means (And Why It’s Misused)
Let’s clear the air: AI infrastructure is not just cloud compute. It’s not just spinning up GPUs or having a Kubernetes cluster. True AI infrastructure is an ecosystem — spanning hardware, software, networking, orchestration, data pipelines, security, and deployment strategies, that enables your models to be trained, tested, and deployed at scale reliably and efficiently.
Many vendors blur this definition. Some refer to AI infrastructure as access to compute resources. Others pitch it as MLOps tooling. But these are fragments, not the full picture. Without the glue —infrastructure engineering — you’re essentially building AI on shaky ground.
Here’s what real AI infrastructure includes:
Provisioning scalable compute environments (on-prem, cloud, hybrid)
CI/CD for AI (from data to model to inference)
Networking and security specific to AI workloads
Automated infrastructure management and monitoring
Model versioning, rollback, and lifecycle support
Regulatory compliance & data governance
As Fedir Kompaniiets, CEO of Gart Solutions, often puts it:
“You can’t build intelligent systems on unintelligent foundations. AI needs an engineered runway to take off.”
That “engineered runway” is where too many projects cut corners. And why most AI deployments fail after the proof-of-concept phase.
The Three Major Categories of AI Infrastructure Providers
Let’s break down the landscape. All AI infrastructure vendors fall into one of these three buckets:
Hyperscalers & Platforms
These are your big cloud providers — AWS, Microsoft Azure, Google Cloud, offering on-demand compute, storage, and managed AI services.
Strengths:
Global scale and availability
Massive catalog of AI/ML services
Flexibility to scale compute up/down
Pay-as-you-go pricing
Limitations:
One-size-fits-all approach
High complexity; steep learning curve
Hidden costs and potential vendor lock-in
No engineering support for tailoring environments
Hyperscalers are powerful, no doubt. But they require skilled teams to design and manage AI-ready infrastructure. The tools are there, but you have to know how to wire them correctly.
AI Tooling Vendors
These vendors — like Hugging Face, DataRobot, Weights & Biases, and Neptune.ai — offer platforms for training, experiment tracking, model deployment, and observability.
Strengths:
Simplified interfaces for ML workflows
Version control, reproducibility, and collaboration
Accelerated model development
Limitations:
Assume infrastructure is already in place
Don’t handle compute provisioning, security, or networking
Tooling doesn’t solve operational or scaling issues
Can add toolchain bloat
AI tooling vendors are great after you’ve built the core infrastructure. But they don’t replace the need for infrastructure automation, engineering, or DevOps support.
AI Infrastructure Engineering & Delivery Partners
This is where real transformation happens. Engineering-led partners design, build, and operate AI infrastructure customized for your business and goals.
Strengths:
Vendor-agnostic and tailored to your environment
Combines DevOps, MLOps, automation, and security
Offers long-term support and scale planning
Aligns with compliance, governance, and data strategies
Gart Solutions is a leader in this category. With proven delivery across healthcare, fintech, and product companies, they offer end-to-end AI infrastructure services — not just tools or compute, but custom-engineered solutions.
When Companies Need Each Category
Here’s a breakdown of when each provider type is right, depending on your business maturity and goals:
Company StageHyperscalerTooling VendorEngineering PartnerStartup✅ For initial experiments✅ If team is skilled❌ Usually overkillScale-up✅ For scalability✅ Adds efficiency✅ To avoid technical debtEnterprise✅ Core platform✅ For governance✅ Crucial for transformationRegulated Industry⚠️ Need strong compliance overlays✅ Helpful for tracking✅ Required for auditability
If you’re running mission-critical AI workloads, handling sensitive data, or deploying in production at scale — you need an engineering-led partner.
Where AI Projects Fail Without Infrastructure Engineering
The AI landscape is full of failed pilots and expensive detours. Why?
Models work in dev, but can’t scale in prod
Data bottlenecks and broken pipelines
Lack of observability and rollback mechanisms
Downtime, security risks, and compliance gaps
Take MedWrite AI, a healthcare NLP platform. They had models ready, but infrastructure issues blocked production launch. Gart Solutions stepped in, designed AI-ready infrastructure with automated scaling and monitoring — and cut time-to-market by over 60%.👉 Read the full case study
Fedir Kompaniiets explains:
“AI tooling gives you a car. Infrastructure engineering builds the road — and the traffic system to keep it running.”
Why Engineering-Led Partners Outperform Tools Alone
The key reason tools fail is that they assume the groundwork has been done. But most companies haven’t:
Set up secure, compliant data flows
Automated their infrastructure
Integrated CI/CD for AI
Designed scalable model-serving environments
Gart Solutions combines IT infrastructure consulting, automation, and DevOps best practices to create a future-proof foundation for AI.
They don’t just deliver a stack — they build a customizable, self-healing, and compliant AI delivery system.
Market Overview: AI Infrastructure Spending and Trends
According to Gartner, global AI infrastructure spending is expected to surpass $422 billion by 2028, growing at a CAGR of 26%. The key investment areas include:
Cloud infrastructure and hybrid deployments
Hardware accelerators (GPUs, TPUs)
MLOps tooling and automation
Engineering services for delivery and monitoring
The big shift? From platform dependence to engineering autonomy.
Companies are realizing that AI platforms are only part of the puzzle — infrastructure strategy is becoming the new battleground.
Deep Dive: Gart Solutions’ Approach to AI Infrastructure Delivery
Gart doesn’t sell tools — they deliver outcomes.
By combining consulting, automation, and AI-ready architectures, they support every stage of the AI lifecycle. Their services include:
IT Infrastructure Consulting
Infrastructure Automation
General IT Infrastructure Services
In their HealthTech AI case study, they delivered HIPAA-compliant, cloud-native AI infrastructure capable of zero-downtime deployments and real-time model performance monitoring.
That’s not just delivery. That’s engineering-led transformation.
Case Studies That Prove the Point
Let’s move beyond theory and look at how this plays out in real businesses.
Take MedWrite AI, a HealthTech platform transforming how clinical notes are analyzed using NLP. When they approached Gart Solutions, their infrastructure was:
Underperforming under load
Hard to manage and monitor
Non-compliant with healthcare standards
Gart stepped in and:
Re-architected their cloud infrastructure
Implemented robust MLOps pipelines
Added auto-scaling and fault tolerance
Ensured HIPAA compliance through secure networking and audit logging
👉 See the full MedWrite AI Case Study
Results:
Time-to-market reduced by 60%
Model performance boosted by 3x
Uptime near 100% during critical deployments
In another case, a fintech company needed to deploy an AI fraud detection engine. The issue? Their tools worked in test but crashed under real-world scale. With Gart Solutions’ infrastructure automation services, they achieved:
Full CI/CD for model updates
Cost-optimized infrastructure scaling
Secure multi-region deployments
The takeaway? Tools are great, but without engineering, they collapse under pressure.
How to Choose the Right AI Infrastructure Partner
Before you sign up with a vendor promising "AI infrastructure," ask yourself:
Do they understand your industry’s compliance needs?
Сan they automate deployments and rollback pipelines?
Will they stay involved beyond the initial setup?
Do they offer custom engineering vs. out-of-the-box tools?
And perhaps most importantly:
❌ Are they trying to sell you tools instead of solving your problems?
With Gart Solutions, you’re getting a team that thinks beyond platforms. They build scalable, secure, and future-proof environments that grow with you.
Why Gart Solutions Stands Out
There’s no shortage of vendors claiming to support AI. But few can deliver custom, scalable, and production-grade infrastructure the way Gart Solutions does.
Here’s why:
Engineering-first approach: Every project starts with strategy, not software
Vendor-neutral: They use what works best for you, not what pays them commissions
Business-oriented outcomes: They align infrastructure with your goals — not just technical specs
Ongoing support: Monitoring, updating, and evolving your infrastructure over time
Proven track record: Across industries like HealthTech, FinTech, and SaaS
Conclusion
AI infrastructure isn’t one-size-fits-all. Whether you're experimenting with models or deploying them into production, you need the right kind of partner to avoid common traps like tool sprawl, vendor lock-in, and under-engineered environments.
To recap:
Hyperscalers give you the raw power, but no guidance
Tooling vendors offer control — but no infrastructure
Engineering-led partners, like Gart Solutions, deliver tailored, future-ready solutions
If your AI initiative is serious, the choice is clear: invest in infrastructure engineering from the start.
And if you're looking for a trusted partner, Gart Solutions is ready to help. Contact Us and explain the challenges of your project.