[lwptoc]
The DevOps iGaming landscape has fundamentally changed. Five years ago, a casino operator deploying every two weeks was considered fast. Today, Tier-1 sportsbooks push to production dozens of times per day — during live UEFA matches, NBA playoffs, and World Series games — without a single second of planned downtime. That's not possible without a mature DevOps engineering practice purpose-built for the regulated, high-stakes iGaming environment.
This guide draws on Gart's work across iGaming, casino, and sports betting platforms — including a sportsbook migration that improved performance by 30–40% — to give you a practitioner-level view of what DevOps in iGaming actually looks like in 2026: the architecture, the compliance automation, the deployment strategies, and the observability stack your platform needs to survive peak traffic and pass MGA or Curacao audits.
Main Challenges iGaming Companies Face Without DevOps
The iGaming sector operates under a set of pressures that few other industries face simultaneously: real-money transactions, real-time odds calculation, strict regulatory oversight from bodies such as the Malta Gaming Authority (MGA) and the Curacao Gaming Control Board, and user expectations for zero-latency gameplay at any hour. Without DevOps, these pressures become existential risks:
Regulatory compliance drift: Manual compliance checks lag behind regulatory updates. A missed configuration change can result in license suspension or six-figure fines.
Deployment fear: Teams afraid to push code during live events create a release backlog that makes every deployment riskier than the last.
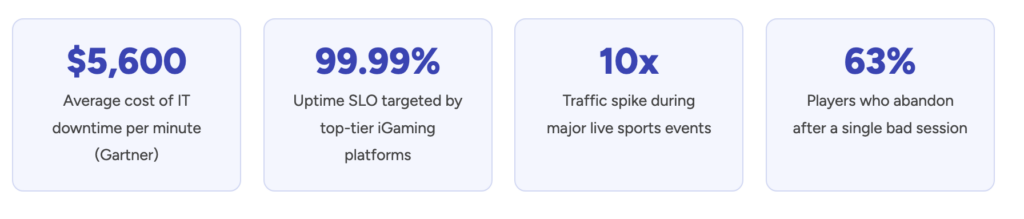
Scalability gaps: A Super Bowl or Champions League kickoff can spike traffic 20× in minutes. Without autoscaling, platforms crater precisely when they're most visible.
Security blind spots: iGaming handles KYC data, payment card data, and session tokens — all attractive targets. Manual security reviews can't keep pace with rapid iteration.
Incident response latency: Without structured on-call runbooks and automated alerting, MTTR (Mean Time to Recover) stretches from minutes to hours — while players are losing trust.
Regulatory Compliance and Auditing
One of the primary challenges for iGaming companies operating without DevOps is ensuring regulatory compliance. These companies must adhere to stringent rules and regulations imposed by entities like Curacao, the Malta Gaming Authority, and the International Association of Gaming Regulators (IAGR). Manual compliance checks and updates can be time-consuming and prone to human error. DevOps practices can automate compliance checks and help implement regulatory changes swiftly, reducing the risk of non-compliance and regulatory fines.
Stability of Operations
iGaming companies must provide players with a stable and uninterrupted gaming experience. Without DevOps, ensuring high availability and operational stability can be challenging. DevOps practices, such as deploying applications across multiple availability zones and through a wide range of IP addresses, help maintain consistent uptime and provide redundancy in the event of server failures or outages. This is vital for player trust and retention.
Data Security and Privacy
Data security is paramount in the iGaming industry, as it involves handling sensitive player information and financial transactions. DevSecOps practices, including integrating security into the development and deployment processes, can significantly enhance data security. The use of separate Docker containers for each application instance and granular configuration of Kubernetes cluster policies ensures that data remains isolated and protected. Implementing encryption and hashing techniques for data at rest and in transit further safeguards sensitive information.
Scalability Issues
Scalability is a critical consideration for iGaming companies, especially during peak periods or when experiencing a surge in player traffic. Without DevOps, some companies may not be using technologies like Kubernetes clusters and autoscaling groups with Docker containers, making it difficult to efficiently scale resources based on demand. DevOps enables automated scaling, ensuring that resources are available to accommodate fluctuating player loads, enhancing the overall gaming experience, and preventing potential performance bottlenecks.
📊 What the DORA data saysAccording to the 2025 DORA State of DevOps Report, elite-performing teams deploy 973× more frequently and have lead times 6,750× shorter than low performers. In an industry where a 10-minute outage during a live sporting event translates directly to lost bets and churn, that gap is the difference between market leadership and irrelevance.
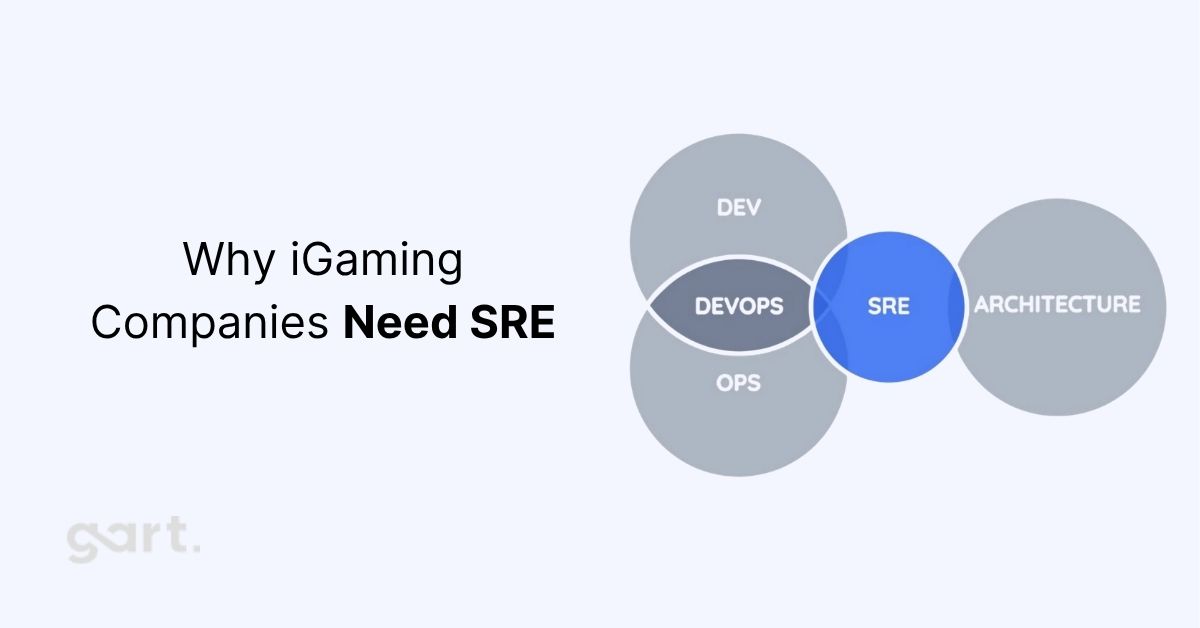
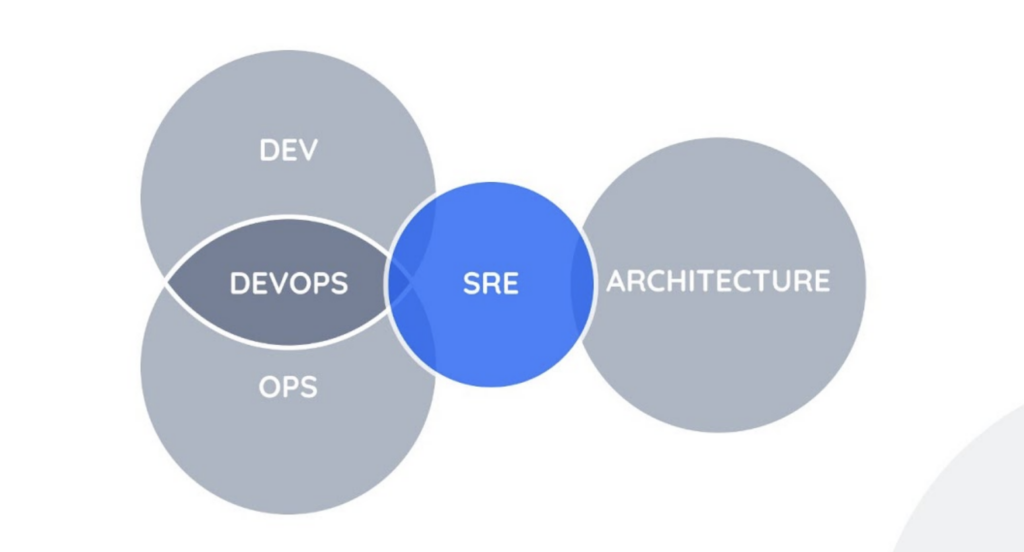
How DevOps in iGaming Differs from Other Industries
DimensioniGaming / Sports BettingTypical SaaS / EnterpriseDeployment frequencyMultiple times per day, including during live eventsWeekly or bi-weekly is commonTraffic patternsExtreme spikes tied to match schedules (predictable but sharp)Gradual growth, occasional campaign spikesRegulatory burdenMGA, Curacao, UKGC, state-by-state US requirements; real-time audit trailsGDPR, SOC 2 — serious but less operationally intrusiveData sensitivityKYC documents, payment data, gambling behaviour (problem gambling liability)PII, business dataUptime toleranceNear zero — players leave within seconds of a slow pageMinutes of downtime often acceptableSecurity surfaceReal-money transactions invite active DDoS, fraud, and scrapingStandard threat modelContent cadenceOdds, markets, and promotions update in millisecondsContent is relatively staticHow DevOps in iGaming Differs from Other Industries
Kubernetes Architecture for iGaming Platforms
Kubernetes has become the default orchestration layer for serious iGaming operators — not because it's fashionable, but because it solves the specific problems these platforms face: burst scaling, isolation between tenant environments, and declarative infrastructure that auditors can inspect.
Namespace isolation for multi-tenant casino platforms
A typical Gart iGaming Kubernetes architecture separates workloads by function and risk profile. Wallet services, game engines, and third-party integrations (payment processors, KYC providers) each run in isolated namespaces with strict NetworkPolicy rules. This prevents lateral movement in the event of a breach — a requirement explicitly called out in MGA technical standards.
Horizontal Pod Autoscaling for match-day traffic
Odds-serving microservices are the first to saturate under match-day load. Gart configures HPA with custom metrics (bets/second via KEDA) rather than CPU alone — because odds calculation is IO-bound and CPU metrics lag the actual bottleneck. This allows the cluster to begin scaling at the first sign of increased bet volume, before latency degrades.
Architecture note from Gart's engineering teamIn one iGaming client deployment, we separated the odds feed processor into its own node pool with GPU-optimized instances, reducing odds calculation latency from 180ms to 22ms at peak load — while keeping the main cluster cost-optimized for baseline traffic.
Specific DevOps Practices and Considerations Tailored to the iGaming Industry
Game Build and Distribution Automation
DevOps can automate the entire game build and distribution process. This means that when developers make changes to the game code, a new version of the game is automatically built and deployed, making it quicker and more efficient to release updates or patches to players.
Real-Time Monitoring and Analytics
Gaming companies should implement robust real-time monitoring and analytics tools. This allows for immediate detection of in-game issues, server performance problems, or player experience disruptions. DevOps can be used to create automated alerts and response systems, ensuring that any issues are addressed swiftly to maintain an uninterrupted gaming experience.
Load Testing for Scalability
Gaming companies often experience sudden surges in player traffic, especially during special events or game launches. DevOps can facilitate load testing to ensure that game servers can handle these traffic spikes without crashing. This is critical for maintaining player satisfaction and retention.
A/B Testing for Game Features
DevOps principles can be applied to A/B testing of game features. By releasing multiple versions of a game to different player segments and collecting data on player preferences and behavior, gaming companies can use DevOps practices to quickly iterate and optimize game design and mechanics.
Player Data Privacy and Compliance
In the gaming industry, ensuring player data privacy and adhering to compliance regulations is crucial. DevOps can automate security and compliance checks to guarantee that player data is handled securely and that the game complies with regional regulations and privacy laws.
Game Content Management
For online games, regular content updates are essential to keep players engaged. DevOps can facilitate the management of game content, enabling quick and efficient content releases while maintaining game stability.
Disaster Recovery and Redundancy
Gaming companies need robust disaster recovery plans and redundancy measures to ensure that games remain available even in the face of server failures or other disruptions. DevOps practices can automate these processes to minimize downtime.
Player Feedback Integration
Gaming companies can use DevOps to create automated systems for capturing player feedback, which can then be analyzed and integrated into development cycles. This feedback loop can lead to more player-centric updates and enhancements.
Cross-Platform Compatibility
Many modern games are designed to run on various platforms, such as PC, console, and mobile devices. DevOps practices can help ensure that games are consistently updated and perform optimally across multiple platforms.
Game Telemetry and Performance Optimization
Collecting and analyzing telemetry data from the game (e.g., player behavior, in-game performance, and crashes) is essential. DevOps can automate the processing of telemetry data to identify areas for performance improvement and enhance the overall gaming experience.
CI/CD Pipeline Design for Casino and Sports Betting
A well-designed CI/CD pipeline for iGaming is not simply "build → test → deploy." It must embed compliance gates, security scanning, and rollback triggers that align with regulatory requirements.
The iGaming CI/CD pipeline: 7 stages
Source trigger: PR to main branch triggers the pipeline. Feature branches use short-lived preview environments for QA.
Static analysis + SAST: Semgrep, Snyk, and Checkov run in parallel. Any HIGH or CRITICAL finding blocks the merge — no exceptions for "we'll fix it later."
Unit + integration tests: Target >80% coverage for wallet, session, and payment services. Integration tests run against ephemeral database snapshots — not production data.
Compliance gate: Automated checks verify that database schema changes have a corresponding migration script, all secrets are referenced from Vault (not hardcoded), and audit log endpoints are reachable.
Container build + scan: Docker image built from a minimal base image (distroless or Alpine). Trivy scans the image for known CVEs before pushing to ECR.
Canary deploy (5% traffic): New version receives 5% of traffic for 10 minutes. Automated rollback triggers if error rate exceeds 0.1% or p99 latency exceeds 300ms.
Full rollout + audit record: After canary success, full deployment proceeds. Deployment event, operator identity, and version hash are written to the immutable audit log.
GitOps and ArgoCD: Declarative Infrastructure for iGaming
GitOps is arguably the most important architectural shift iGaming DevOps teams can make for compliance purposes. When your cluster state is declared in Git and ArgoCD reconciles it continuously, every infrastructure change has an author, a timestamp, a review trail, and an automated rollback path. That's exactly what MGA and UKGC auditors want to see.
How Gart implements GitOps for iGaming clients
All Kubernetes manifests, Helm values, and Kustomize overlays live in a dedicated infra-gitops repository.
ArgoCD syncs the cluster every 3 minutes and on every push to the main branch.
Environment promotion (staging → production) is a pull request — reviewed, approved, and merged, creating a natural audit trail.
Out-of-band changes (direct kubectl apply) are detected and automatically reverted, preventing configuration drift that regulators flag.
When an MGA auditor asks "who changed this configuration and when?", the answer is a Git blame command and a pull request URL — not a war-story from memory. GitOps turns compliance evidence collection from a week-long exercise into a 10-minute query.
Progressive Delivery: Canary, Blue/Green, and Feature Flags
iGaming teams cannot afford a failed deployment during a live Champions League match. Progressive delivery techniques let you validate new code against real traffic before committing to a full rollout — with automatic escape hatches.
Blue/Green deployments for zero-downtime releases
The blue environment runs the current production version. The green environment receives the new version. After green passes automated smoke tests, the load balancer shifts 100% of traffic in a single atomic swap. If a problem surfaces, traffic flips back to blue in seconds — not minutes. Gart uses AWS ALB target group weights or Kubernetes Ingress annotations to implement this without external tooling.
Canary releases for odds and wallet services
For high-risk services (payment processing, odds calculation), we use Flagger to automate canary analysis. Traffic is shifted 5% → 20% → 50% → 100% over 30 minutes, with real-time analysis of error rate, latency, and custom metrics (bet acceptance rate). Any deviation from the baseline triggers an automatic rollback.
Feature flags for controlled rollouts
Feature flags decouple deployment from release. A new live betting interface can be deployed to production but enabled only for QA team accounts, then for 1% of users in a low-risk jurisdiction, then progressively expanded. This is especially valuable for compliance: a jurisdiction-specific feature (e.g., responsible gambling prompts mandated by UKGC) can be toggled by country without a new deployment.
Observability Stack: Metrics, Logs, and Traces
In iGaming, observability is not a nice-to-have — it is a regulatory and commercial requirement. You must be able to answer, in real time: Is the wallet service processing transactions? Are odds feeds updating within SLA? Is any player session showing anomalous behaviour that might indicate fraud or a system bug?
The three pillars for iGaming platforms
PillarTool stack Gart recommendsKey iGaming use caseMetricsPrometheus + Grafana / Amazon CloudWatchBets/sec, odds update latency, payment success rate, concurrent sessionsLogsOpenSearch (ELK) / Loki + GrafanaAudit log immutability, transaction history, access logs for complianceTracesJaeger / AWS X-Ray / OpenTelemetryEnd-to-end latency from bet placement to confirmation; identifying which microservice adds latencyThe three pillars for iGaming platforms
AI-assisted incident response
Forward-looking iGaming DevOps teams are now integrating LLM-based runbook assistance into their alerting workflows. When PagerDuty fires an alert, an AI agent queries the last 48 hours of logs, identifies similar past incidents, and surfaces the three most likely root causes with suggested remediation steps — before the on-call engineer has opened their laptop. Gart's SRE practice has implemented this pattern for a sports betting client, reducing MTTR by approximately 40%.
Compliance Automation and Regulatory Reporting
Compliance in iGaming is not a one-time audit — it is a continuous operational requirement. MGA mandates real-time reporting of game outcomes, financial transactions, and player session data. Curacao requires infrastructure documentation and change records. US state gaming commissions (New Jersey DGE, Pennsylvania PGCB) require infrastructure localization and data residency controls.
Compliance as Code with Open Policy Agent (OPA)
Gart implements Open Policy Agent (OPA) — a CNCF graduated project — as the policy enforcement layer across the Kubernetes cluster. OPA Gatekeeper policies prevent:
Deployment of containers running as root
Pods without resource limits (a common cause of noisy-neighbour problems during traffic spikes)
Services that lack the required audit-log-enabled: "true" annotation
Images from unregistered registries (supply chain security)
Automated regulatory reporting pipelines
For MGA-licensed clients, Gart builds event-driven pipelines (AWS EventBridge → Lambda → encrypted S3 → MGA SFTP) that deliver daily game integrity reports automatically. The pipeline is idempotent, retryable, and has its own monitoring — so a reporting failure triggers an alert before the submission deadline, not after.
Chaos Engineering and Resilience Testing
The question is not if your iGaming infrastructure will experience a failure — it is whether you will discover the failure in a controlled chaos experiment or during a live sporting event. Chaos Engineering, popularised by Netflix and formalised in the Principles of Chaos Engineering, systematically injects failures to validate resilience assumptions.
What Gart tests in iGaming chaos experiments
Kill a payment service pod: Does the circuit breaker engage? Do bets queue or fail fast with a user-friendly error?
Simulate an availability zone failure: Does traffic reroute to the secondary AZ within the RTO SLA?
Inject 200ms latency on the odds feed: Does the frontend degrade gracefully, or do users see blank screens?
Exhaust database connection pool: Do services fail independently, or does connection exhaustion cascade across unrelated services?
Gart runs chaos experiments in production during low-traffic windows (early morning, off-season) using AWS Fault Injection Simulator (FIS) and Chaos Mesh. Each experiment has a defined hypothesis, blast radius, and automated abort condition — so the experiment stops before it becomes a real incident.
FinOps for iGaming: Controlling Cloud Costs at Scale
iGaming platforms have some of the most volatile cost profiles in cloud computing. During the FIFA World Cup, your AWS bill might be 8× the baseline. After the tournament ends, unused capacity sits idle if you haven't automated rightsizing. FinOps — the practice of bringing financial accountability to cloud spending — is increasingly a DevOps responsibility.
Cost control strategies Gart implements
Spot/Preemptible instances for stateless workloads: Game rendering services, analytics processors, and batch jobs run on Spot, cutting compute costs by 60–70% for interruption-tolerant workloads.
Reserved/Savings Plans for baseline capacity: The always-on wallet, auth, and session services run on 1-year Compute Savings Plans at a 40% discount vs. on-demand.
Automated scheduled scaling: Match schedules are known in advance. Gart automates pre-scaling — 30 minutes before kick-off, capacity expands; 2 hours after full-time, it contracts. This avoids both under-provisioning and over-spending.
Tagging enforcement via OPA: Every resource must have cost-centre, product, and environment tags. Untagged resources are flagged in daily cost reports, enabling accurate showback by product line.
Multi-Region Failover and Disaster Recovery
The largest iGaming operators serve players across dozens of jurisdictions simultaneously. A single-region architecture is both a technical risk and a compliance liability — several regulators explicitly require data residency within their territory.
Active-Active vs. Active-Passive: choosing the right model
ModelRTORPOCostBest forActive-Active<30 seconds~02× computeWallet, sessions, real-money transactionsActive-Passive (warm standby)2–5 minutes<1 minute~1.3× computeBack-office, reporting, content managementPilot light15–30 minutes<15 minutes~1.1× computeNon-player-facing systems, dev/staging DRActive-Active vs. Active-Passive: choosing the right model
Database migration strategy for multi-region iGaming
Migrating a live iGaming database without downtime is one of the most complex operations in the stack. Gart's approach: dual-write during migration (both old and new DB receive writes), with a reader cutover first, then a writer cutover validated by checksums. We use AWS DMS for heterogeneous migrations (e.g., Oracle → Aurora PostgreSQL) with a parallel validation script that compares row counts and checksums across both systems before the final cutover. Zero downtime. Zero data loss. Fully auditable.
Secrets Management and Security Practices
In iGaming, a leaked API key to a payment processor or a KYC provider can trigger a regulatory investigation and a license review. Secrets management is not optional — it is a license condition.
The Gart secrets management stack for iGaming
HashiCorp Vault (or AWS Secrets Manager) as the single source of truth for all credentials, API keys, and certificates.
Dynamic secrets: Database credentials are generated on-demand with a TTL of 1 hour. No static passwords. No password rotation ceremonies.
Kubernetes External Secrets Operator: Syncs secrets from Vault into Kubernetes Secrets at runtime — developers never see production credentials.
Git scanning: DevSecOps pipelines run Gitleaks on every commit to prevent secrets from entering version control.
Audit logging: Every secret access is logged with the accessor identity, timestamp, and source IP — meeting MGA audit requirements.
DevOps iGaming Best Practices Checklist
CategoryPracticePriorityCI/CDCompliance gate in every pipeline — blocks deploy if audit log endpoint unreachable🔴 CriticalCI/CDAll secrets from Vault/Secrets Manager — zero hardcoded credentials🔴 CriticalDeploymentCanary releases for wallet and odds services with automated rollback🔴 CriticalInfrastructureIaC for all environments (Terraform + Helm) — no manual cloud console changes🔴 CriticalGitOpsArgoCD drift detection — automatic revert of out-of-band changes🟠 HighObservabilityCustom business metrics (bets/sec, payment success rate) in Grafana dashboards🟠 HighResilienceMonthly chaos experiments with documented results🟠 HighComplianceOPA Gatekeeper policies enforcing security baselines at admission time🟠 HighFinOpsScheduled scaling tied to match calendar — pre-scale 30 min before events🟡 MediumDRQuarterly DR test with documented RTO/RPO validation🟡 MediumDevOps iGaming Best Practices Checklist
Best Practices for DevOps in Gaming
Automation of Deployment and Testing: One of the core principles of DevOps is automation. In gaming, where updates and releases are frequent, automating the deployment process can ensure that new features or bug fixes are implemented smoothly and without disruptions. Automated testing is equally important to maintain the quality of the gaming experience.
Continuous Integration and Continuous Delivery (CI/CD): CI/CD pipelines streamline the delivery process by automatically integrating code changes and delivering them to production. This accelerates time-to-market and reduces the risk of introducing errors.
Version Control: Utilizing version control systems like Git allows gaming companies to manage and track changes to their codebase effectively. This ensures that every change is well-documented and reversible.
Infrastructure as Code (IaC): Treating infrastructure as code means that your gaming company can provision, manage, and scale resources efficiently through code. This not only reduces manual errors but also makes the entire system more reliable and scalable.
Monitoring and Feedback Loops: DevOps emphasizes real-time monitoring of applications and infrastructure. This helps in identifying issues early and allows teams to provide quick fixes or enhancements. Continuous feedback loops ensure that the gaming experience is continually improving.
Security Integration: With the prevalence of cyber threats, incorporating security into DevOps practices is crucial. Security checks should be automated throughout the development process to identify vulnerabilities and ensure a secure gaming environment.
Serverless Agility: With serverless architecture, iGaming SaaS platforms don't need to manage servers or infrastructure.Serverless platforms automatically handle the scaling of resources based on demand. This ensures that your SaaS application can easily accommodate fluctuations in user activity without manual interventions.
Microservices Architecture: SaaS solutions aren't constructed as large, monolithic applications that rely on a complex network of servers.Microservice architecture is like building a digital system using small, independent building blocks (microservices) that work together. Each building block does a specific job, and they all communicate to create a complete, flexible, and efficient system.
In the gaming industry, DevOps practices can have a significant impact on the player experience, game quality, and the ability to respond to rapidly changing player preferences. By tailoring DevOps processes to the unique demands of gaming, companies can stay competitive and offer a more engaging and reliable gaming experience.
Benefits of DevOps for Gaming Companies
Faster Time-to-Market
DevOps enables rapid deployment of new features and updates. In the gaming industry, this means that companies can respond to market demands quickly, making it easier to stay competitive.
Enhanced Quality and Reliability
Automation of testing and quality control reduces human errors and ensures that the gaming experience is reliable and consistent, thus increasing player trust.
Improved Collaboration
DevOps encourages better communication and collaboration between development and operations teams. This synergy results in smoother processes and quicker issue resolution.
Cost Efficiency
By automating and streamlining processes, gaming companies can optimize resource utilization, ultimately reducing operational costs.
Scalability
With Infrastructure as Code, gaming companies can scale resources up or down based on demand. This flexibility is crucial for handling peak loads, such as during major gaming events or promotions.
Competitive Edge
Implementing DevOps practices gives gaming companies a competitive edge. They can keep up with market trends and swiftly respond to customer feedback, attracting and retaining a larger player base.
Security
By integrating security into the DevOps pipeline, gaming companies can proactively address vulnerabilities, ensuring player data and transactions remain secure.
Integration of Game Engines into CI/CD Pipelines
The integration of game engines into Continuous Integration/Continuous Deployment (CI/CD) pipelines is essential for streamlining game development and ensuring the efficient and automated delivery of high-quality games. Here's a step-by-step guide on how to achieve this integration:
1. Version Control Setup:
Choose a version control system (e.g., Git) and create a repository to manage the game's source code and assets. Ensure that team members are well-versed in version control practices.
2. Select a CI/CD Platform:
Choose a CI/CD platform or system that aligns with your development needs. Popular options include Jenkins, Travis CI, GitLab CI/CD, or cloud-based services like CircleCI and GitHub Actions. More CI/CD tools you can find here.
3. CI/CD Configuration:
Set up a CI/CD pipeline in your chosen platform. Define the various stages of your pipeline, which may include:
Build Stage: Configure the pipeline to automatically build the game using the game engine. Game engine-specific command-line tools can be used to initiate the build.
Testing Stage: Implement testing scripts and quality assurance checks. These can include unit tests, integration tests, performance tests, and other checks to ensure the game functions correctly.
Deployment Stage: Define the deployment process, which includes packaging the game for specific platforms and uploading it to distribution platforms or app stores.
4. Game Engine Integration:
Utilize the game engine's command-line or scripting capabilities to trigger builds and exports. Most game engines, such as Unity and Unreal Engine, provide command-line tools that allow you to build games without the need for manual intervention.
Incorporate these engine-specific commands into your CI/CD pipeline scripts. For example, you can use Unity's command-line interface (Unity CLI) to build and export the game for various platforms.
5. Asset Management:
Leverage the asset management features within the game engine to track changes, collaborate on assets, and manage asset versioning.
6. Automation and Triggering:
Configure your CI/CD pipeline to trigger automatically whenever there is a new code commit or asset change in the version control system. This ensures that builds and tests are run as soon as changes are made.
7. Environment Configuration:
Ensure that the CI/CD pipeline replicates the target environments accurately. Game engines may require specific configurations for each platform (e.g., PC, console, mobile), and these configurations should be defined in the pipeline scripts.
8. Testing and Quality Assurance:
Implement automated testing scripts within the pipeline to validate the game's functionality, performance, and quality. This can include functional testing, load testing, and compatibility testing for different platforms.
9. Deployment and Distribution:
Automate the deployment process, which involves packaging the game for specific platforms and distributing it to app stores or other distribution channels. Ensure that deployment scripts are tailored to each platform's requirements.
10. Monitoring and Reporting:
Set up monitoring and reporting tools to track the progress and outcomes of each CI/CD pipeline run. This allows you to identify and address any issues promptly.
11. Rollback Mechanism:
Implement a rollback mechanism in case issues arise after a game's release. This mechanism should enable you to revert to previous game versions quickly and efficiently.
By following these steps, game developers can successfully integrate game engines into CI/CD pipelines, enabling automated and efficient game development, testing, and deployment processes while maintaining high-quality gaming experiences for players.
Case Study: AWS Migration and Infrastructure Localization for a Sportsbook Platform
One of Gart's most complex iGaming DevOps engagements involved migrating a US-facing sportsbook to AWS while complying with state-specific infrastructure requirements across multiple US gaming jurisdictions. The core challenge: different states require game data to be processed and stored within state borders — meaning a single AWS region was not enough.
What we delivered:
Multi-region AWS architecture with state-specific VPCs and data residency controls enforced via SCP (Service Control Policies)
CI/CD automation that reduced deployment time from 4 hours to 22 minutes
Infrastructure as Code covering 100% of production resources (Terraform + Terragrunt)
Compliance reporting pipeline delivering automated reports to state gaming commissions
30–40% overall performance improvement measured across p50 and p99 latency metrics
Read the full case study: AWS Migration & Infrastructure Localization for Sportsbook Platform
Conclusion
In the dynamic and fiercely competitive gaming, gambling, and iGaming sectors, the adoption of DevOps transcends being merely a recommended practice; it has become an imperative. Its capacity to promptly respond to market shifts, deliver top-tier gaming experiences, bolster cooperation, and enhance security positions DevOps as a transformative force for enterprises within these industries.
For iGaming companies seeking DevOps services, we encourage you to reach out to Gart. Embracing DevOps principles not only heightens a company's standing within the market but also significantly contributes to the overall success and reliability of the gaming experience, ultimately leading to greater player satisfaction and a more robust financial performance.
Roman Burdiuzha
Co-founder & CTO, Gart Solutions · Cloud Architecture Expert
Roman has 15+ years of experience in DevOps and cloud architecture, with prior leadership roles at SoftServe and lifecell Ukraine. He co-founded Gart Solutions, where he leads cloud transformation and infrastructure modernization engagements across Europe and North America. In one recent client engagement, Gart reduced infrastructure waste by 38% through consolidating idle resources and introducing usage-aware automation. Read more on Startup Weekly.

It’s no surprise that tech leaders are searching for alternatives to hyperscalers like AWS. Whether you're a CTO wrestling with runaway infrastructure bills or a DevOps engineer tired of managing AWS complexity, the reality is the same: AWS is powerful but expensive, and over time, you're likely paying for far more than you're using.
That’s where Hetzner enters the picture. A European cloud and dedicated server provider with transparent pricing, high-performance hardware, and no surprise billing. More and more companies — from startups to scale-ups — are migrating from AWS to Hetzner and cutting their cloud bills by up to 90%. This article also explores why businesses across Europe and beyond are migrating to Hetzner. You’ll learn from real-world migration case studies, developer insights from Reddit and Hacker News, and detailed breakdowns of the technical and financial gains teams are experiencing.
In this detailed guide, we’ll show you exactly how to migrate from AWS to Hetzner using a proven, step-by-step playbook. We won’t just say "move your servers" — we’ll show you:
What tools to use
What AWS services need replacements
What pitfalls to avoid
How Gart Solutions can support your migration with expert DevOps and infrastructure-as-code capabilities
Forget vendor lock-in. Forget mysterious billing surprises. Let’s walk through how to make your infrastructure leaner, cheaper, and more under your control — without sacrificing performance or reliability.
The Rise of Cloud Fatigue — And Why It’s Getting Worse
The pitch of hyperscalers like AWS and Azure was simple: scalable, flexible, and cost-efficient infrastructure for everyone. But in practice, things look very different today.
Here’s what most teams are experiencing:
Runaway cloud costs with unpredictable billing
Vendor lock-in through proprietary services and tooling
PaaS abstraction layers that make debugging harder, not easier
Data privacy concerns, especially for EU companies
Opaque pricing models that make forecasting nearly impossible
Common AWS Cost Traps:
Data Egress Fees: AWS charges up to $0.09/GB for outbound traffic — Hetzner includes 20 TB free per VM, then only ~$1/TB after.
Managed Services Premium: AWS RDS, ElastiCache, SQS, Lambda all add layers of cost and margin.
Per-Request Billing: API Gateway, CloudWatch, S3, etc. charge per request — hard to predict and scale.
Storage IOPS: EBS IOPS fees balloon costs for disk-intensive workloads.
What Is a Hetzner Cloud and Why to Choose it?
Why Hetzner is catching attention:
Incredibly competitive pricing — VMs start at under €5/month
Generous data transfer — 20 TB/month included per instance
EU-based data centers — Fully GDPR-compliant (Germany & Finland)
Infrastructure over abstraction — You manage the stack
Native support for Terraform, Docker, Kubernetes (K3s), Ansible, and more
A recent Data-Aces migration revealed Hetzner cut costs by 70–80% across compute and storage alone — and by over 90% in bandwidth fees. That’s a massive savings opportunity.
Below are some real cost savings when moving from AWS to Hetzner with the goal of cutting costs (often cited as “90 %” in real-world moves) while minimizing disruption.
Performance & Pricing Table: AWS vs Hetzner
Feature AWS EC2 (t3.medium) Hetzner CPX21 vCPUs 2 2 RAM 4 GB 4 GB Storage EBS (charged separately) 40 GB NVMe (included) Monthly Price (EU) ~$38 + storage €6.90 (all-inclusive) Bandwidth Charged separately 20 TB (included) Performance Moderate (burstable) Dedicated vCPU (Source: Data-Aces, Hetzner Pricing Docs)
Real Cost Savings: From 5x to 10x Cheaper
Let’s model a small-to-medium web app stack:
Resource AWS Monthly Hetzner Monthly Savings 2x t3.medium VMs $76 €13.80 ~82% 1x RDS db.t3.medium $75 Self-hosted DB ~90% 1 TB S3 Storage $23 €2.90 ~87% 2 TB Egress Bandwidth $180 Included ~100% Total $354 ~€20–25 ~93% (Source: Data-Aces, Hetzner Pricing Docs)
It’s become especially popular among:
European SaaS startups
DevOps-heavy teams tired of black-box services
Companies pursuing cloud repatriation strategies
Teams seeking EU-only data residency
These savings are real and repeatable. You just need to plan the migration carefully — and that’s what we’re doing next.
High-Level AWS to Hetzner Migration Strategy
Before diving into detailed steps, it’s critical to pick your strategy. There are three broad approaches when migrating from AWS to Hetzner (or any non‑AWS infrastructure):
Strategy Description Pros Cons / Risks “Lift & shift” / rehost Copy your existing EC2 / EBS / file systems over to Hetzner VMs or dedicated servers with minimal re-architecture Fastest, with less refactoring Not always feasible (if you use many AWS‑native services), may carry over inefficiencies Replatform / partial refactor Migrate core (e.g., compute, storage) but rework or replace AWS-managed services (RDS → self‑hosted, Lambdas → functions on servers) Better performance/cost balance Requires effort, introduces complexity Refactor / rebuild in Hetzner-native style Re-architect for Hetzner (VPCs, Docker/Kubernetes, automation) from the ground up Maximum long-term flexibility and cost control Longest time, highest upfront risk Table: Migration strategies
Most real-world migrations are hybrid: you start with lift & shift for some parts, then gradually refactor high-cost or high-risk parts.
One recent migration project publicized their result as “cut 90 %” of AWS costs by migrating to Hetzner + OVH and replicating essential AWS features via Terraform & Ansible. (Hacker News)
But beware — that kind of saving is realistic only if:
Your usage is steady/ predictable (not huge autoscaling spikes)
You’re not heavily dependent on AWS-managed services
You’re ready to take responsibility for operations, monitoring, backups, and reliability
Gart Solutions value is that we help you evaluate that risk, determine which strategy fits you, and execute it.
1st: Pre-Migration Phase: Scoping, Auditing, Planning
Before you touch any server, scoping is everything. This is where your migration succeeds or fails. The first step? Take a full inventory of everything running in your AWS account.
Step 1: Inventory & Mapping
EC2 instances
EBS volumes
S3 buckets
IAM roles / users
Security groups / firewalls
RDS / Aurora / ElastiCache / Lambda
CloudWatch / logs / alarms
Route53 zones / DNS entries
SQS, API Gateway, Cognito, and any AWS-native services
Use AWS Config, Cost Explorer, Inframap, or Gart’s audit suite to pull this automatically.
Step 2: Group by Priority & Risk
Make a matrix:
Mission-critical vs low-risk
Stateless vs stateful
Easy to rehost vs tightly coupled to AWS
Step 3: Choose Migration Approach
Lift & Shift: Fastest, but carries AWS inefficiencies
Replatform: Move services but optimize architecture
Refactor: Best long-term, requires dev investment
Example:
AWS Service Action Hetzner Equivalent EC2 Rehost Hetzner Cloud VMs RDS Replatform Self-managed PostgreSQL Lambda Refactor Docker + cron or serverless S3 Rehost Hetzner Object Storage CloudFront Replace Cloudflare / BunnyCDN Table: Hetzner Equivalents to the main AWS services.
Gart Solutions can help design the full architecture, plan migration order, and assess downtime risk per service.
Step 4: Cost Projection Model
Build a spreadsheet estimating:
Current AWS costs (EC2, RDS, S3, etc.)
Target Hetzner resources (CPX, CAX, Storage Boxes, Object Storage)
Estimated total monthly savings
Migration effort required
Tools like infracost.io + Gart’s cost planner can help model this automatically.
2nd: Building the Foundation in Hetzner (Parallel Setup)
Once your AWS audit is complete and you’ve selected a strategy (lift, replatform, refactor), it’s time to build the new home for your infrastructure on Hetzner. This is the "foundation-laying" phase — your Hetzner infrastructure will run in parallel to your AWS environment during testing and validation.
This approach ensures zero production downtime and gives you time to test everything end-to-end before pulling the plug on AWS.
2.1 Account & Project Setup
Create your Hetzner account(s). Hetzner uses Projects inside the account for grouping (like “dev”, “prod”).
Invite users / roles, set up access controls.
Enable billing alerts, quotas, and usage dashboards.
Gart Solutions helps you bootstrap the account, governance, and security policy from day one.
2.2 Networking & VPC Topology
Design private networks, subnets, firewall rules (like AWS VPC + security groups).
Reserve floating IPs (Hetzner analog to AWS elastic IP) for failover.
Set up NAT gateways / Internet gateways, route tables.
Decide on cross‑region / cross‑site connectivity (VPN, interconnect).
Optionally deploy a load balancer (Hetzner’s LB or a custom proxy layer).
In some migrations, teams emulate LB by spinning up CX11 servers with nginx and using floating IPs & automation. This was reported in real-world Reddit migrations. (Reddit)
2.3 Base VM Images & Automation
Choose your OS base (Ubuntu, Debian, CentOS, etc).
Harden baseline images (SSH keys, firewall, logging, security).
Bake images with configuration management (Ansible, Packer) for consistency.
Deploy staging / test clusters identical to production size but scaled-down.
Gart Solutions can build golden images, implement snapshot & versioning strategy, and automate VM provisioning via Terraform + Ansible.
2.4 Storage & Block Volumes
Provision volumes / block storage equivalent to EBS.
Decide volume types (SSD, NVMe, etc).
Set up disk partitioning, LVM, RAID, or ZFS layers if needed.
Attach volumes to VMs and test I/O performance, benchmarking.
2.5 Object Storage & S3 Migration Plan
Use Hetzner Object Storage buckets (S3-compatible). Hetzner’s documentation offers a guide to migrate from another provider’s buckets. (Hetzner Docs)
Use tools like rclone, s3cmd, MinIO client (mc) for full sync; note custom metadata may be lost except with MinIO client.
For large data sets, consider multi-part uploads, parallel sync, throttling to avoid saturating network.
Gart Solutions can script and orchestrate bucket-level sync with minimal downtime and consistency checks.
2.6 Database Setup
Spin up database servers (e.g. PostgreSQL, MySQL, or your DB of choice).
Configure replication, clustering, high availability, backups, monitoring.
Optionally put in a delay replica for safety.
Preload schemas and test with sample data.
Since Hetzner has no fully managed RDS equivalent, you need to treat this carefully. Gart Solutions can help deploy resilient, scalable DB clusters, handle failover, and manage backups.
2.7 Application & Middleware Stack
Deploy your app stack (containers, runtime, web servers, API servers, caches, etc) in Hetzner staging environment.
Test end-to-end functionality, integrations, network routes.
Set up SSL/TLS (Let’s Encrypt, or your own certs).
Deploy logging, monitoring, alerting stack (Prometheus, Grafana, Loki, ELK, etc).
One migration noted they rebuilt key AWS features (hardening, monitoring, rolling deploys, TLS automation) using Terraform + Ansible. (Hacker News)
2.8 DNS, CDN, & Edge Services
If you used AWS Route 53, migrate your hosted zones / DNS records to Hetzner DNS (or a third-party DNS if you prefer).
Set up TTLs low before cutover.
If you used CloudFront or AWS CDN, evaluate replacing with Cloudflare, BunnyCDN, Fastly, or any CDN of your choice.
Validate DNS propagation, health checks, and failover behavior.
AWS-to-Hetzner Service Mapping Table
AWS Service Hetzner Equivalent / Solution Notes EC2 CPX, CAX, or dedicated servers Similar VM types, better price-perf EBS Attached volumes Use NVMe for high-speed I/O S3 Hetzner Object Storage S3-compatible with CLI tool support RDS Self-hosted PostgreSQL/MySQL Use Ansible + daily snapshot backups Route53 Hetzner DNS or Cloudflare Full DNS control, API-accessible CloudFront Cloudflare, BunnyCDN CDN options with better pricing Lambda Docker containers, Cron + Event Hooks Replace with cron jobs, containers, Nomad SQS Redis Queue, RabbitMQ, NATS Use self-hosted queues CloudWatch Grafana + Prometheus + Loki Full open-source observability stack IAM Hetzner API Tokens + Secrets Mgmt Optional Vault/Keycloak for advanced control Table: AWS-to-Hetzner Service Mapping Table
3rd. - Data Migration & Dual-Writing (Synchronization Phase)
At this point, the Hetzner staging environments are ready. Next, you must bring live data without losing consistency.
3.1 Snapshot / Disk Migration
For EC2 / EBS volumes, create a snapshot, mount it in AWS, and copy data (via rsync, dd, or file-level).
Hetzner docs provide a migration recipe: backup data, scp/rsync to new server, restore users, firewall rules, etc. (Hetzner Docs)
For entire partitions, you can replicate block devices, but be careful with UUIDs, bootloader, etc.
3.2 Database Sync / Replication
Use database replication from the source (AWS RDS or self-hosted) to the target.
Use logical replication or sync tools (e.g., pglogical, binlog replication, etc).
For the final cutover, pause writes or fail traffic to catch up.
Validate consistency, run checksums, compare counts.
3.3 Dual-Writing / Shadow Writes (if possible)
If your application allows, implement dual writes (write to both AWS and Hetzner DB) during the migration window.
Use feature flags, flags to route reads to one side, writes to both, etc.
This smooths the transition and reduces downtime risk.
3.4 Incremental File Sync
Use rsync, unison, or incremental sync scripts to keep changing files in sync.
Use a cron job or a watcher-based incremental tool.
During final cutover, run a last sync.
3.5 Object Storage Final Sync
Re-run your s3cmd / mc / rclone sync to flush any changed objects.
Validate checksums, metadata, and permissions.
3.6 Verification & Smoke Testing
Validate that data is correct (row counts, file sizes, checksums).
Run functional and integration tests in the Hetzner environment.
Monitor logs, metrics, error rates.
Compare performance between source and target.
Gart Solutions can orchestrate all these sync tasks with prebuilt scripts and verify consistency automatically.
4th. - Cutover / Switch Traffic (Switchover Phase)
With data synced and validation done, now you switch user traffic from AWS to Hetzner.
4.1 Freeze Writes / Quiesce AWS
Stop new writes on AWS (maintenance window, read-only mode, etc).
Wait for final replication, flush all queues, and ensure no lag.
4.2 DNS / Floating IP Switch
Reassign floating IPs or public IPs in Hetzner.
Update DNS records (lower TTL to speed propagation).
Use DNS failover, health checks, or weighted routing if available.
Monitor for propagation errors.
4.3 Enable Traffic & Monitor
Slowly ramp traffic to Hetzner (e.g., 10 %, 50 %, then 100 %).
Watch error rates, latencies, resource usage,and logs.
Roll back if something catastrophic happens (DNS TTL helps).
Validate stability over several hours/days.
One anecdote from Reddit:
“The migrations … implemented CX11 servers with nginx to do load balancing … floating IP automation was tricky.” (Reddit)
Gart Solutions can provide the automation and control logic for IP switching and traffic cutover to minimize human error.
4.4 Decommission AWS Resources
Once confident, shut down AWS EC2, RDS, S3 buckets, etc.
Clean up IAM, snapshots, EBS, autoscaling, etc.
Keep backups or roll-back snapshots for a grace period.
5th. - Post‑Migration, Optimization & Hardening
The cutover is not the end. You now own full operations and must optimize, mature, and ensure reliability.
5.1 Performance Tuning & Cost Optimization
Size down over-provisioned VMs.
Use autoscaling if needed (with scripts / custom logic).
Tune database, caching, and query performance.
Monitor usage and right-size volumes, storage classes.
Optimize network egress and minimize cross-DC traffic.
5.2 Monitoring, Logging, and Alerting
Implement Prometheus, Grafana, Alertmanager, logging stack (Loki, ELK, etc).
Monitor metrics: CPU, memory, disk, I/O, network, and application errors.
Add alert thresholds, SLA-based alerts, and anomaly detection.
Audit logs, access logs, and enable security monitoring.
In a published migration, they rebuilt AWS features like rolling deploys, auditing, SSH policies, monitoring, and alerting via Ansible & Terraform. (Hacker News)
Gart Solutions can provide this stack out-of-box or adapt your existing one.
5.3 Backup, Disaster Recovery, and DR Planning
Build a backup strategy: full, incremental, offsite (e.g., backup to object storage, remote region).
Test restore procedures regularly.
Spinning up a cold standby in another DC or region.
Document incident playbooks.
5.4 Security Hardening & Compliance
Enforce firewall rules, security groups.
SSH hardening, key rotation.
Implement intrusion detection, SELinux, audit, and process isolation.
Network segmentation (public vs private subnets).
Pen tests, vulnerability scans.
If you need ISO 27001, GDPR, etc, capture all controls.
The migration to European cloud (Hetzner + OVH) cited that they preserved ISO 27001 alignment using Ansible roles for hardening, alerting, deployments, etc. (Hacker News)
Gart Solutions specializes in security & compliance hardening in such migrations.
5.5 Continuous Improvement & Automation
Automate deployments (CI/CD pipelines) targeting your new Hetzner environment.
Use Infrastructure-as-Code (Terraform, Ansible) for reproducibility.
Add self-healing, scaling, chaos testing.
Iteratively refine architecture, storage tiers, and caches.
6th. - Common Challenges & Pitfalls (and How Gart Solutions Helps)
Here’s where many migrations get stuck — but with proper attention, you can avoid or mitigate these issues.
Challenge Description Mitigation / Advice AWS-managed services are not present in Hetzner E.g. Lambda, Kinesis, SQS, managed RDS, EventBridge Replace with open-source equivalents, host them yourself, or use third-party services. Gart Solutions helps choose and integrate replacements. Network latency and inter-DC instability Hetzner’s backbone may be less robust across many regions Avoid cross-DC traffic when possible; architect locality; monitor network; accept in some cases lower reliability. Floating IP (elastic IP) automation complexity Reassigning public IPs during cutover is tricky Gart Solutions builds scripts/automation to manage IP reassignment, failover logic, and net rules. Consistency of data during cutover Replication lag, drift, and race conditions Use dual writes, quiesce writes carefully, and validate checksums. DNS propagation delays Slow TTL changes impact cutover Use low TTL well before, monitor propagation. Operational maturity & support burden You now manage everything on your own Gart Solutions can act as your managed services / second-line support and help mature ops. Unexpected performance bottlenecks Differences in virtualization, disk I/O, and network Benchmark early, tune, choose right VM types, work with us to profile bottlenecks. Lock‑in to AWS IaC (CloudFormation, CDK) These are not portable to Hetzner Migrate to Terraform, rewrite IaC. Gart Solutions helps port your stacks. Team knowledge / expertise gap Your team may be unfamiliar with Hetzner, managing infrastructure Gart Solutions can mentor your engineers, share playbooks, and provide operational support.
What Developers Are Saying (Reddit & Hacker News)
The shift to Hetzner isn’t just hype — it’s backed by growing word-of-mouth among engineers.
From a popular Reddit thread and Hacker News discussions, here’s what developers are saying:
“Hetzner gives me 4x the performance of AWS for less than half the cost.”
“I run my entire CI/CD infrastructure on Hetzner now. It’s faster and cheaper.”
“The simplicity is what makes it powerful. I don’t need all of Azure’s magic, just fast and stable servers.”
“Network somewhat unstable when you operate a large microservice deployment… missing drives, servers that won’t boot … cross region sucks a bit due to network interruptions.”
These quotes reflect a clear trend: developers prefer Hetzner when they want control, speed, and affordability without the lock-in.
That’s exactly the kind of issue Gart Solutions can anticipate and guard against: we can put in redundant paths, failover logic, and monitoring to catch these faults.
Real-World Migrations to Hetzner: 3 Key Case Studies
Let’s break down how real companies moved from AWS, Azure, and legacy systems to Hetzner—what worked, what broke, and what improved.
1. Online Gambling Provider (AWS to Hetzner)
Challenge: AWS costs were spiraling out of control during traffic spikes (especially during major sports events). DevOps complexity slowed deployments.
Solution:
Dockerized infrastructure
Hetzner Cloud instances + CI/CD via GitLab
Manual failovers + internal monitoring
Results:
50% lower infra cost
Faster deployments
Improved performance during live betting events
2. Media Platform (Legacy + AWS to Hetzner)
Challenge: A hybrid stack with AWS + on-prem hardware was becoming unmanageable. Cloud costs, especially for bandwidth and CDN, were too high.
Solution:
Static asset delivery via Hetzner + Nginx
Custom caching and image optimization pipeline
High-performance VMs for backend API workloads
Results:
70% lower monthly spend
Consistent response times
Full infrastructure ownership
3. Landfill SaaS App (Azure + Local Servers to Hetzner)
Challenge: Limited scalability, rising Azure fees, and GDPR concerns. Needed to go global without hyperscaler pricing.
Solution:
Infrastructure provisioned with Terraform
Self-hosted monitoring, backups, and firewalling
Docker containers for app services
Results:
80% cost savings
Full GDPR compliance
Improved uptime + faster deployments.
Hetzner vs AWS vs Azure: Feature & Pricing Comparison
FeatureHetzner CloudAWSMicrosoft AzureCompute (4vCPU, 16GB RAM)€23.75/month~$130/month~€120/monthBandwidth20 TB/month included~$0.09/GB outbound~€0.12/GB outboundData CentersGermany, FinlandGlobalGlobalGDPR ComplianceNative (EU)Region-specificRegion-specificManaged ServicesMinimal (IaaS-focused)Extensive (RDS, Lambda)Extensive (App Services)SupportBasic ticketingPaid support plansTiered support optionsDeveloper ControlHighMediumMediumComplexityLowHighHighHetzner vs AWS vs Azure: Feature & Pricing Comparison
What Makes Hetzner So Attractive for European Teams
Price transparency: No more guessing your monthly cloud bill
Data sovereignty: Native GDPR compliance with data in Germany or Finland
No lock-in: Infrastructure is yours—no black-box abstractions
DevOps ready: Works seamlessly with Terraform, Docker, Ansible, GitLab CI/CD
Fast provisioning: New VMs spin up in seconds
Simple billing: One invoice, no “billing surprises”
But It’s Not for Everyone: When Hetzner May Not Be a Fit
You need global region coverage (e.g., US, Asia, LatAm)
Your team is deeply reliant on managed services
You lack in-house DevOps or sysadmin experience
You need enterprise-grade support SLAs or 24/7 NOC
Why Choose Gart Solutions as a Migration Partner?
When choosing a migration partner, you want more than just a “contractor that moves VMs.” Gart Solutions offers:
End-to-end service — From assessment, architecture, building, cutover, post‑migration hardening, to long-term managed support.
Risk-aware planning — We perform failure mode analysis, build rollbacks, and stage migrations to minimize downtime.
Prebuilt modules & templates — For common stacks (web app, API, DB, caching, queueing) we have reusable Terraform + Ansible modules optimized for Hetzner.
Cost modeling & validation — We help you verify that the “cut 90%” target is realistic for your workload, and guard against surprises.
Operations transition & training — We upskill your team in the new environment and optionally act as your managed ops partner.
Security & compliance focus — We bring experience in ISO 27001, GDPR, security hardening, audit controls, so the migration doesn’t compromise your posture.
Gart Solutions is not just moving your infrastructure — we’re enabling you to run reliably, securely, and cost-effectively on Hetzner after the move.
Example Migration Walkthrough
Here’s a condensed example of how a migration might execute:
1. Assessment & planning (2 weeks)
Inventory AWS stack, build dependency map, choose lift & shift for compute + refactor for managed services, cost modeling, roadmap.
2. Build target infra (1 week)
Set up Hetzner projects, VPC, subnets, firewalls, base VM images, object storage, app staging stack, DNS config.
3. Initial data sync (ongoing)
Sync file servers, start DB replication, sync objects.
4. Testing & verification (3 days)
Smoke tests, integration tests, performance tests. Tweak architecture, adjust sizes.
5. Cutover (maintenance window, e.g. weekend)
Freeze writes, run final sync, switch DNS / floating IPs, bring traffic live, monitor.
6. Post‑migration ops (weeks-months)
Tune performance, enable scaling logic, set alerts, harden security, fully decommission AWS.
Actual users report:
“We migrated production in under an hour, once everything was ready; whole prep took days/weeks.” (@rameerez)
“The biggest cost saving was in bandwidth bills.” (Hacker News)
That said, every case is different; Gart Solutions sizes our involvement to your scale and risk appetite.
Summary & Key Takeaways
Migrating from AWS to Hetzner can yield massive cost savings (some report 70–90 %) especially when AWS bills are heavy for bandwidth and managed services. (Hacker News)
It’s not just copying servers — you must plan for AWS-native services, network, high availability, DNS, and operational maturity.
The success lies in rigorous planning, parallel setup, data sync and validation, smart cutover, and post-migration optimization.
Gart Solutions can serve as your end‑to‑end migration and operations partner, reducing your risk, accelerating execution, and helping you land safely.
If you follow a methodical playbook and engage expertise (whether Gart or your own), migrating to Hetzner can be practical — not just theory.
Download the Whitepaper: "Migration from AWS to Hetzner: Step-by-Step Guide to Cut Costs by 90%"
Whitepaper-Migrating-from-AWS-to-Hetzner-Gart-SolutionsDownload

An in-depth technical and economic analysis of Germany's two leading cloud providers — and a professional framework for migrating your infrastructure with zero downtime.
The tectonic shift in enterprise computing is no longer approaching — it has arrived. US-based hyperscalers are being challenged by high-performance, regulation-aligned European infrastructure. Rising egress fees, unpredictable pricing, and increasing regulatory pressure under NIS2, DORA, and the EU AI Act have pushed organizations to reconsider where and how they run mission-critical workloads.
In this landscape, two German-headquartered providers have become the standard-bearers of the European cloud movement: Hetzner Online GmbH and IONOS by 1&1. Each offers a radically different — yet complementary — vision of modern infrastructure. Choosing between them isn't just a technical decision; it's a strategic one.
This guide breaks down their architectures, performance benchmarks, cost models, and security postures — and explains how Gart Solutions' Cloud Migration Methodology can help you move to either platform with confidence.
Hetzner
The Developer's Playground
Unmanaged, high-performance infrastructure with deep API control, granular pricing, and massive inclusive bandwidth. Built for teams who know exactly what they want to build.
VS
IONOS
The Complete Package
Managed environments with integrated WAF, daily backups, and enterprise-grade support. Built for SMEs and enterprises that want results without the DevOps overhead.
Architecture & Philosophy
The deepest difference between Hetzner and IONOS isn't hardware — it's philosophy. Understanding this divide is the first step to choosing the right fit for your team.
⚙️
Hetzner: Unmanaged Precision
Hetzner operates on a "professional playground" model. Deep root access, Terraform providers, CLI tools, and an industry-best API give engineers complete sovereignty over their stack.
🛡️
IONOS: Managed Citadel
IONOS ships move-in-ready environments: WAF, malware scanning, and daily backups are included by default. Businesses get reduced operational overhead.
🏗️
Hetzner Compute
CAX (ARM64), CPX (shared vCPU), and CCX (dedicated) instances across AMD Ryzen, AMD EPYC, and ARM64 silicon. Designed for microservices to database nodes.
🖥️
IONOS Compute Engine
AMD EPYC "Turin" & "Milan" processors alongside Intel Xeon Gen 5/6, deployed via a visual Data Center Designer canvas. The "hyperscale experience."
Feature Category
Hetzner Cloud
IONOS Compute Engine
Target Audience
Developers, DevOps, Tech Teams
SMEs, Enterprise, Managed Service Seekers
Billing Model
Hourly / Usage-based Flexible
Pay-per-minute / Savings Plans
Control Interface
Cloud Console, CLI, API
Data Center Designer (Visual Canvas)
Scaling
High — Granular CPU/RAM
High — Flexible CPU/RAM/PCI slots
Primary Strength
Price-to-Performance Best-in-class
Integrated Enterprise Support Managed
Security Model
Network-level DDoS; manual hardening
WAF + malware scan + daily backups included Plug & Play
Performance Benchmarks
Raw specs don't tell the whole story. Independent testing using the Google Core Web Vitals framework reveals a clear split: IONOS wins on out-of-the-box frontend performance; Hetzner dominates backend throughput once tuned.
Performance KPI
IONOS Managed
Hetzner Unmanaged
Largest Contentful Paint (LCP)
~1.5s Excellent
~4.0s (requires tuning)
Time to Interactive (TTI)
~2.1s Highly Responsive
~4.8s (requires tuning)
Time to First Byte (TTFB)
~536ms
~122ms Extremely Fast
Consistency Score
36
71 More Stable
Instance Provisioning Time
~125s
~25s 5× Faster
Key Insight: Hetzner's higher consistency score and ultra-low TTFB make it the superior foundation for developers who can implement NGINX microcaching or Redis object stores. If you're running complex stateful applications or backend-heavy platforms, Hetzner will outperform IONOS once properly configured.
🏆
Out-of-the-Box Winner — IONOS
For teams running WordPress, WooCommerce, or eCommerce platforms that can't afford DevOps tuning time, IONOS's preconfigured stacks and optimized PHP handlers deliver superior LCP and TTI without a single configuration change.
The Economics of Bandwidth
The "egress fee trap" is one of the primary drivers of European cloud migration in 2026. AWS, Azure, and GCP charge significant fees per gigabyte of outbound traffic — fees that compound rapidly at scale and render certain business models entirely unviable.
AWS — 20 TB Outbound
€1,511
Per month in egress fees alone — before compute, storage, or support costs.
Hetzner — 20 TB Included
€0.00
20 TB+ of outbound traffic is bundled by default on most cloud instances.
IONOS — Entry Pricing
From $2
Bundled email, domains, SSL — predictable flat costs ideal for SMEs.
For high-bandwidth applications — file-sharing systems, streaming platforms, and gaming servers — Hetzner's flat-rate traffic model makes business models viable that would be economically impossible on a hyperscale pay-per-GB model. One iGaming case study demonstrated that switching to Hetzner made free-trial user acquisition (at 10 GB per user) financially sustainable for the first time.
Total Cost of Ownership (TCO) Reality:
When accounting for egress fees, support tiers, and proprietary lock-in costs, organizations migrating from AWS or Azure to Hetzner or IONOS typically see cloud bills cut by up to 90% — not just introductory discounts.
Security, Compliance & Sovereignty
The regulatory environment of 2025–2026 — NIS2, DORA, the EU AI Act — has made data residency a legal obligation, not just a preference. Both providers operate ISO 27001-certified data centers in Germany and across the EU, ensuring full GDPR compliance. But their security implementations differ significantly.
🔧 Hetzner Security
✓ Network-level DDoS protection included
✓ ISO 27001 certified German data centers
✓ Full root access for custom security policies
✓ Custom audit trails & monitoring pipelines
✓ Open standards: Kubernetes, OpenStack
🛡️ IONOS Security
✓ Web Application Firewall (WAF) — included
✓ Automatic daily backups — included
✓ Malware scanning — included
✓ DDoS defense pre-installed
✓ Reduced compliance complexity for healthcare/finance
🌍 Digital Sovereignty Checklist for 2026
✦
Physical hosting within EU borders (DE, FI, ES) — GDPR applicability
✦
Legal data control within EU — mitigates US CLOUD Act risk
✦
Open standards (K8s, OpenStack) — prevents vendor lock-in
✦
ISO 27001 certification — meets enterprise audit requirements
✦
NIS2 / DORA compliance readiness — critical for regulated sectors
✦
EU AI Act-compatible infrastructure for ML workloads
📊 Real-World Case Study
iGaming Platform: From 48-Hour Deploys to 10-Minute Releases
An online gambling provider struggling with manual deployments and catastrophic crashes during live sports events engaged Gart Solutions for a complete DevOps overhaul on Hetzner infrastructure.
⚠ Before Migration
✕ 48-hour deployment cycles for every release
✕ Frequent crashes during high-traffic sports events
✕ No scalability path for traffic surges
✕ Egress fees making free-trial acquisition unviable
✓ After Gart Solutions Migration
✓ Deployment time reduced to under 10 minutes
✓ Zero downtime during 3× traffic surges
✓ 50% reduction in total infrastructure costs
✓ Free-trial model became financially sustainable
Why Migration Requires Expert Execution
Raw platform potential is only realized through expert implementation. The decision to move to Hetzner or IONOS is strategic — but the execution carries significant operational risk. Gart Solutions has over a decade of experience architecting zero-downtime migrations from AWS, Azure, and DigitalOcean to Europe's best cloud infrastructure.
90%
Reduction in cloud infrastructure spend
391%
3-year ROI with 3-month payback
93%
Reduction in unplanned downtime
63%
Faster development cycles post-migration
The 5-Stage Gart Migration Lifecycle
Not a lift-and-shift. A structured transformation — built for long-term scalability and immediate quick wins.
1
Weeks 1–2
Assessment & Discovery
Deep-dive audit of existing infrastructure: workload identification, dependency mapping, performance profiling, and sovereignty gap analysis.
2
Weeks 3–4
Roadmap Design
A comprehensive migration roadmap with defined KPIs, stakeholder communication plan, refactoring strategy, and 6R classification for every application.
3
Weeks 5–14
Seamless Migration
Infrastructure-as-Code (Terraform, Ansible) for reproducible deployment. Advanced synchronization ensures zero interruptions with 10% → 100% traffic ramping.
4
Weeks 15–18
Testing & Optimization
Rigorous performance validation: bottleneck identification, OWASP security compliance checks, load testing, and automated CI/CD pipeline integration.
5
Ongoing
24/7 Maintenance & Monitoring
Continuous peak performance management. Round-the-clock expert assistance for monitoring, alerting, incident response, and iterative optimization.
The 6 Migration Strategies We Apply
We classify every application in your portfolio using the industry-standard 6R framework — ensuring the right approach for each workload.
Re-host
Move applications as-is, without code changes. Fast execution with immediate cost savings.
→ Low-complexity workloads
Re-platform
Minor adjustments to leverage cloud benefits — e.g., swap on-prem DB for Managed PostgreSQL.
→ Managed database upgrades
Re-factor
Rebuild high-value applications for cloud-native performance and maximum scalability.
→ Complex, scaling-critical apps
Repurchase
Replace legacy custom code with a modern SaaS or cloud-native equivalent (CRM, ERP).
→ Legacy tooling replacement
Retain
Keep mission-critical apps in place temporarily while compliance complexities are resolved.
→ High-risk regulated workloads
Retire
Decommission redundant systems to reduce cost, attack surface, and operational burden.
→ Legacy IT reduction
What You Gain with Gart Solutions
🔒
Full Digital Sovereignty
EU-hosted, EU-governed, and US CLOUD Act-protected infrastructure.
⚡
Zero-Downtime Cutover
Proven dual-write and traffic ramp-up migration methodology.
📉
Up to 90% Cost Reduction
Eliminate hidden egress fees and massive hyperscale premiums.
🤝
Expert Compliance Guidance
NIS2, DORA, and GDPR compliance requirements fully covered.
🚀
IaC-Reproducible Infra
Terraform and Ansible automation to eliminate manual configuration drift.
📡
24/7 Post-Migration Support
Ongoing expert monitoring, alerting, and rapid incident response.
Ready to Cut Your Cloud Bill by Up to 90%?
Our certified migration team has moved 100+ organizations from AWS and Azure to Hetzner and IONOS — with zero data loss and zero unplanned downtime. Start with a free infrastructure audit and get your sovereign migration roadmap in two weeks. Get Migration Audit
The Verdict: Which Provider Is Right for You?
The Hetzner vs. IONOS question doesn't have a single answer — it has a correct answer for your specific workload, team capability, and compliance requirements. Here's how to navigate the decision.
Choose Hetzner if you…
Have an experienced DevOps or engineering team capable of manual configuration
Run compute-heavy workloads: gaming backends, media encoding, data pipelines
Need maximum cost efficiency with high outbound traffic (>10 TB/month)
Want granular control over security policies and monitoring stacks
Are building on open standards: Kubernetes, Terraform, OpenStack
Choose IONOS if you…
Are an SME or enterprise seeking predictable costs and managed services
Run WordPress, WooCommerce, or frontend-heavy web applications
Operate in regulated sectors (healthcare, finance) needing out-of-box compliance
Want an integrated support experience with personal consultants
Need NVIDIA H200 GPU access for AI/ML inference workloads
The 2026 Mandate: Audit your current infrastructure. Map your sovereign requirements. Identify the egress fees, lock-in costs, and compliance gaps hiding in your current cloud spend. Then engage a migration partner capable of executing a seamless move to the European cloud — without gambling your production uptime on a DIY lift-and-shift.